Natural Language Processing performance metrics (benchmarks)
Natural Language Processing is a very vast field of research. It consists of many tasks like Machine translation, Question Answering, Text Summarization, Image captioning, Sentiment Analysis, etc. Researchers try to make different machine learning and deep learning models to solve these tasks. The most difficult job in NLP is to measure the performance of these models for different tasks. In other Machine learning tasks, it is easier to measure the performance because the cost function or evaluation criteria are well defined as we can calculate Mean absolute error(MAE) or Mean square error(MSE) for regression, and we can calculate accuracy and F1-score for classification tasks. One more reason for this is that labels are well-defined in other tasks, but in the NLP task, the ground truth/result can vary.
Example: If someone asks, “What is your name?” a person can answer in many different ways like:
- My name is Aman
- Sir/Madam my name is Aman Aman
Or a more elaborate answer can be given like:
- I am Aman Anand, but you can call me Aman
Similarly, if we want the summary of a paragraph or essay, different answers are possible. Different people will write different summaries based on their understanding and linguistic skills(vocabulary and grammar). In the same way, different models will write different summaries and all of them will be correct.
Also, in the case of Natural Language Processing, it is possible that biases may creep into models based on the dataset or evaluation criteria. Therefore, Standard Performance Benchmarks are necessary to evaluate the performance of models for NLP tasks. These Performance metrics gives us an indication of which model is better for which task.
Some famous NLP Performance Benchmarks are listed below:
GLUE
General Language Understanding Evaluation is a benchmark based on different types of tasks rather than the evaluation a single task. The three major categories of tasks are single-sentence tasks, similarity and paraphrase tasks, and inference tasks.
A detail of the different tasks and evaluation metrics are given below:
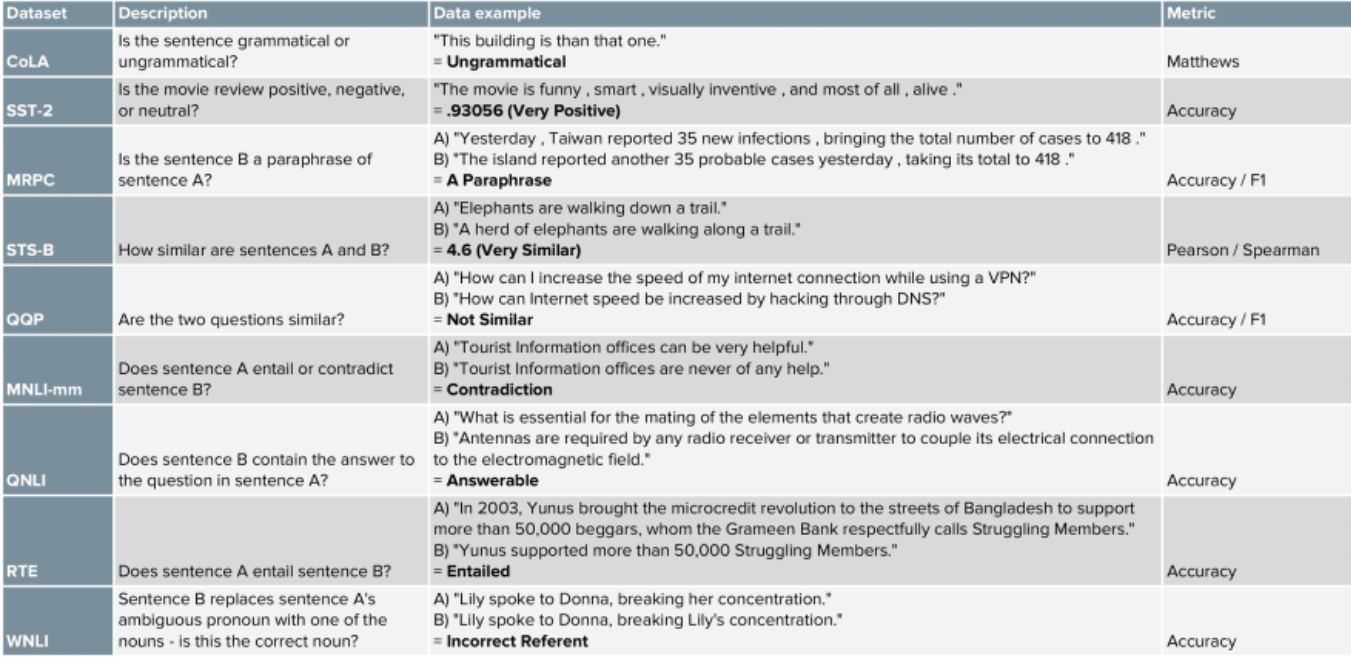
Out of the nine tasks mentioned above, CoLA and SST-2 are single sentence tasks, MRPC, QQP, and STS-B are similarity and paraphrase tasks, and MNLI, QNLI, RTE and WNLI are inference tasks. The different state-of-the-art(SOTA) language models are evaluated on this benchmark.
Super GLUE
In the Super General Language Understanding Evaluation metric, 2 of the tasks were kept from the GLUE metric, namely RTE and WSC(which is almost the same); and six new tasks were added to make better performance metrics than GLUE.
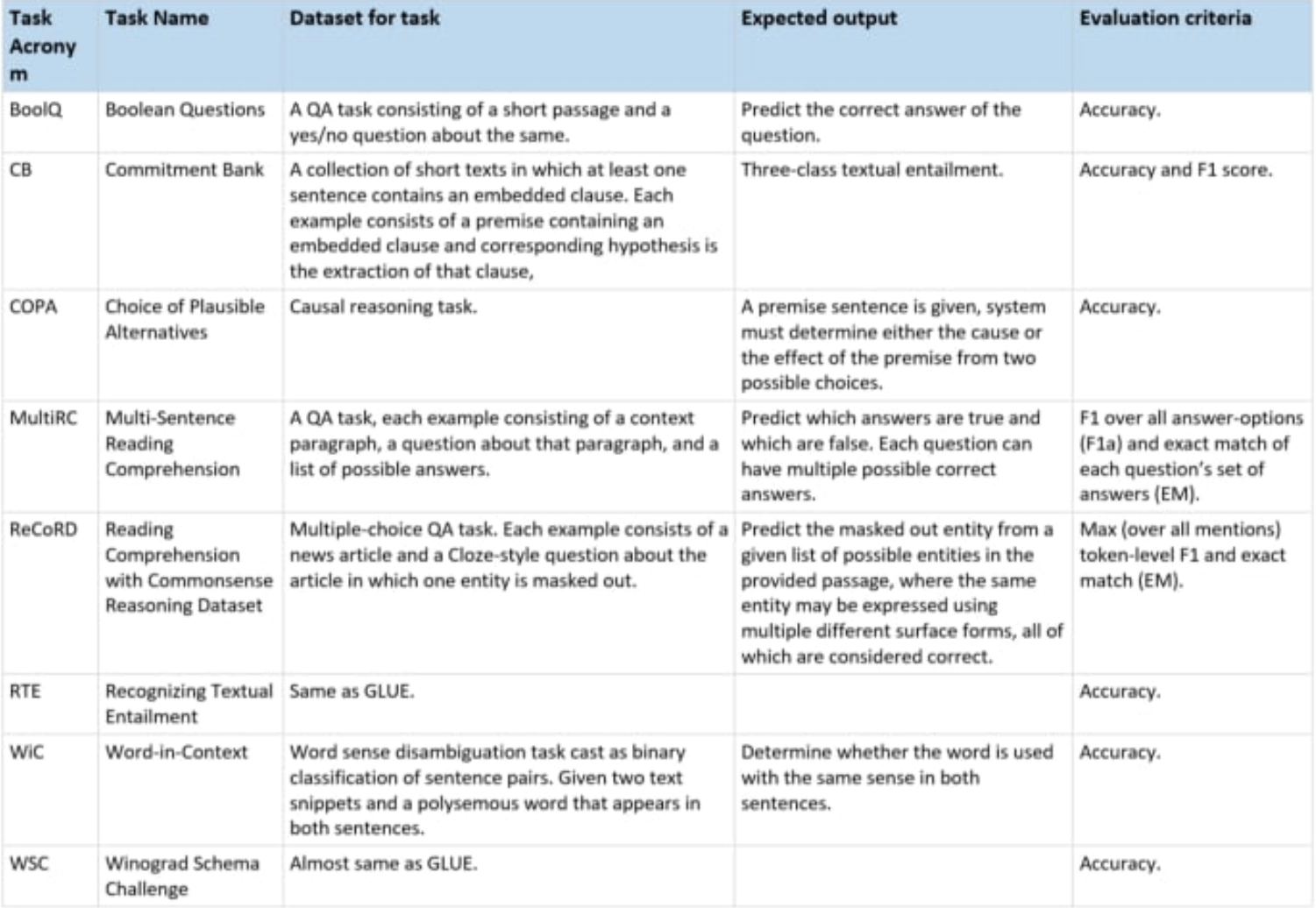
SQuAD
Stanford Question Answering Dataset is a reading comprehension dataset with questions created through crowdsourcing. A passage is given and questions are asked based on that passage. The answer to these questions is a segment of text from the passage.
An example from the vast set of passages present in the dataset is:
Oxygen is a chemical element with symbol O and atomic number 8. It is a member of the chalcogen group on the periodic table and is a highly reactive nonmetal and oxidizing agent that readily forms compounds (notably oxides) with most elements. By mass, oxygen is the third-most abundant element in the universe, after hydrogen and helium. At standard temperature and pressure, two atoms of the element bind to form dioxygen, a colorless and odorless diatomic gas with the formula O. Diatomic oxygen gas constitutes 20.8% of the Earth’s atmosphere. However, monitoring of atmospheric oxygen levels show a global downward trend because of fossil-fuel burning. Oxygen is the most abundant element by mass in the Earth’s crust as part of oxide compounds such as silicon dioxide, making up almost half of the crust’s mass.
The questions asked based on this paragraph are:
-
What is the atomic number of the periodic table for oxygen?
-
What is the second most abundant element?
-
Which gas makes up 20.8% of the Earth’s atmosphere?
-
How many atoms combine to form dioxygen?
-
Roughly how much oxygen makes up the Earth’s crust?
This metric is for a single task unlike the other two metrics mentioned above.
BLEU
BiLingual Evaluation Understudy is a performance metric to measure the performance of machine translation models. It evaluates how good a model translates from one language to another. It assigns a score for machine translation based on the unigrams, bigrams, or trigrams present in the generated output and compares it with the ground truth. This performance metric has many problems, but it was one of the first methods to assign a score to machine translation models – it always gives a score between 0 and 1.
Some of its shortcomings are:
-
It doesn’t consider meaning.
-
It doesn’t directly consider sentence structure.
-
It doesn’t handle morphologically rich languages.
MS MACRO
Machine Reading Comprehension Dataset is a large scale dataset focused on machine reading comprehension. It consists of the following tasks:
- Question answering — generates a well-formed answer (if possible) based on the context passages that can be understood with the question and passage context.
- Passage ranking — ranks a set of retrieved passages given a question.
- Key phrase Extraction — predicts if a question is answerable given a set of context passages, and extracts and synthesize the answer as a human would. The evaluation of these tasks is done using BLEU and ROGUE(Recall-Oriented Understudy for Gisting Evaluation) metrics.
XTREME
Cross-lingual TRansfer Evaluation of Multilingual Encoders is a benchmark developed by Google for the evaluation of 40 languages on 9 different tasks. A representation of the tasks are given below.
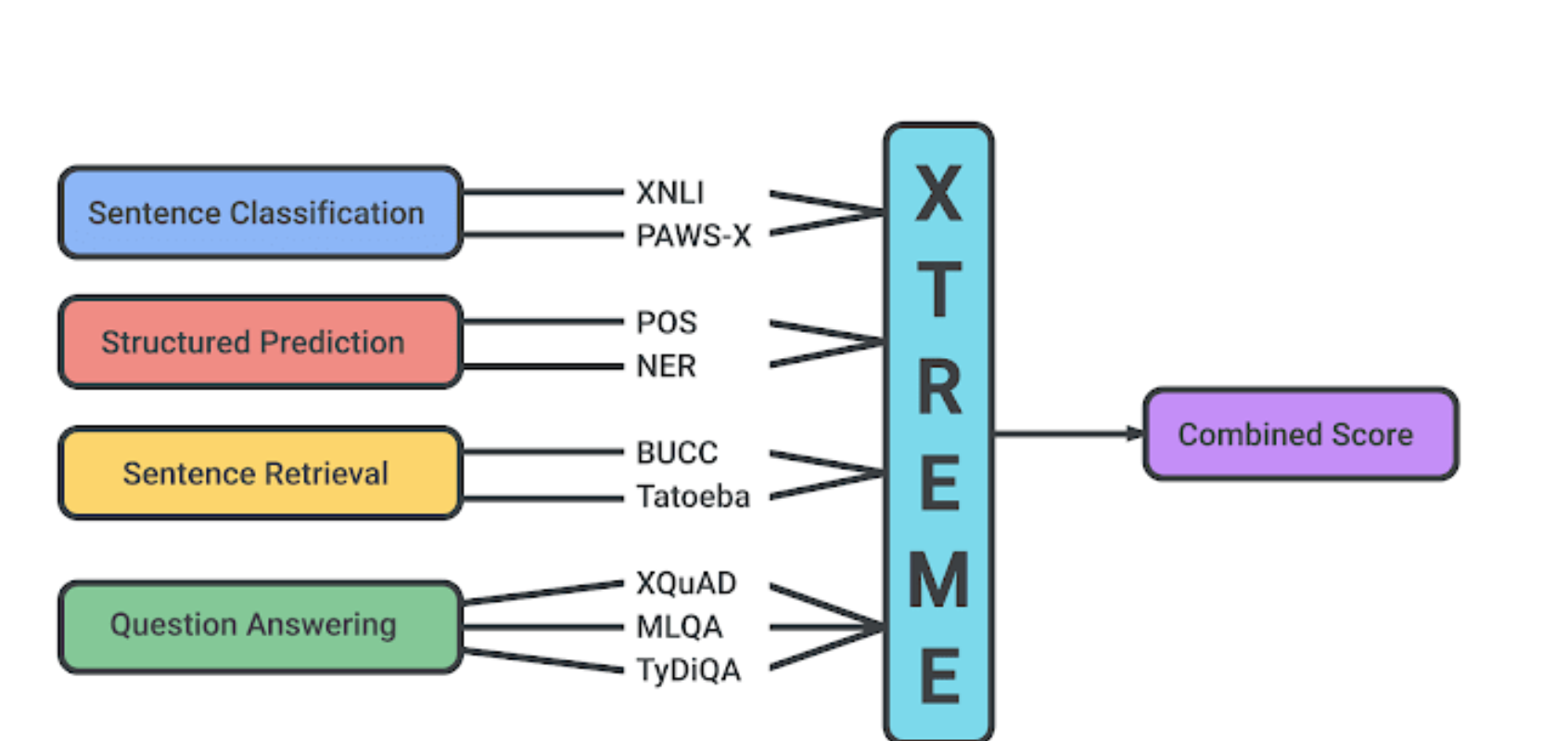
This evaluation dataset and metrics is the most recent one. Itis used to evaluate SOTA models for cross-lingual tasks and pre-trained models performance for zero-shot learning.
I hope you could get a good review of the different NLP benchmarks and how complex they are. Thanks for reading this post.
Free Resources
- undefined by undefined