The Principles of the Convolution
Learn about the convolution operation and how it is used in deep learning.
We'll cover the following...
Why convolution?
The fully connected layer that we saw doesn’t respect the spatial structure of the input. If, for example, the input is an image, the NN will destruct the 2D structure into a 1-dimensional vector. To address the issue, we have designed Convolutional Neural Networks (CNNs). They work exceptionally well for computer vision applications.
Why do we use them when we process images? Because we know a priori that nearby pixels share similar characteristics and we want to take that into account by design. That assumption is called the inductive bias.
Convolutional layers exploit the local structure of the data.
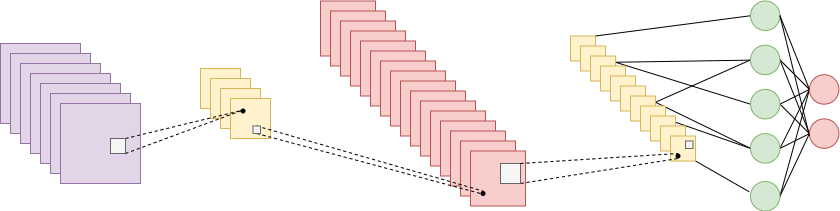
But how is it possible to focus on the local structure instead of fully connected layers that take linear combinations of the input?
The answer is quite simple. We restrict the convolutional layer to operate on a local window called kernel. Then, we slide this window throughout the input image.
Convolution
The basic operation of CNNs is the convolution. Mathematically, a convolution between two 2-dimensional functions is defined as:
...