Running MapReduce End to End
Explore how to run MapReduce jobs end to end by submitting them to a Hadoop pseudo-distributed cluster using HDFS for data storage and YARN for resource management. Understand job submission commands, monitor execution, and interpret job output through various interfaces and counters.
We'll cover the following...
Running MapReduce End to End
We know how to run a MapReduce job using the code widget. In this lesson, we’ll learn to submit the job to a Hadoop cluster. For this purpose, we use a pseudo-distributed Hadoop cluster running in a docker environment.
Conceptually, the end-to-end MapReduce program works as follows:
The following code snippet lists the commands to execute that run a MapReduce job. Each command is explained later in the lesson. You may read the explanation first, and then execute the commands in the terminal. At the end of the lesson, a video shows the execution run of these commands.
Exercise
Explanation
-
Copy and execute the following command in the terminal:
/DataJek/startHadoop.sh -
Once the script finishes running, execute the following command:
jpsThe jps command lists all the running Java processes. If you see the following six processes running, then the pesudo-distributed Hadoop cluster is working correctly:
- Namenode
- Datanode
- NodeManager
- ResourceManager
- SecondaryNameNode
- JobHistoryServer
Here’s a screenshot of the expected outcome.
-
Before we run our MapReduce job, we have to upload our data to HDFS. We’ll learn more about HDFS in a later chapter, but for now it is suffice to know that the job will read the input file from HDFS. Execute the following command to upload data to HDFS:
hdfs dfs -copyFromLocal /DataJek/cars.data / -
We can verify if the upload to HDFS command has successfully executed. Run the following command and verify that cars.data file is present at the root:
hdfs dfs -ls /The result of the command should look like the following screenshot:
-
Now that our Hadoop pseudo-cluster is up and input data ready, we can submit our job for execution. Submitting the job implies submitting a Java jar file containing code to be executed by the framework.
We already made the jar file available for execution in the terminal. The jar file name is followed by the class name to be executed. We create a class called
Driverto represent the job appearing in the code snippet below. Finally, the class name is followed by command line arguments to theDriverclass. The code for theDriveris similar to theCarCounterMrProgramused in the unit test-case of the previous section. However, a slight code change allows us to specify the number of reducers tasks to spawn. In the next lesson, we’ll examine how changing the number of reducers affects the program output. For now, we have a single reducer.public class Driver { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration config = new Configuration(); Path input = new Path(args[0]); Path output = new Path(args[1]); // Set default number of reducers to 1 int numReducers = 1; if (args.length > 2) { numReducers = Integer.parseInt(args[2]); } Job job = Job.getInstance(config); job.setJarByClass(Driver.class); job.setMapperClass(CarMapper.class); job.setReducerClass(CarReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, input); FileOutputFormat.setOutputPath(job, output); job.setNumReduceTasks(numReducers); job.waitForCompletion(true); } }Use the following command to submit the job for execution:
hadoop jar
JarDependencies/MapReduceJarDependencies/MapReduce-1.0-SNAPSHOT.jar Driver /cars.data /MyJobResult
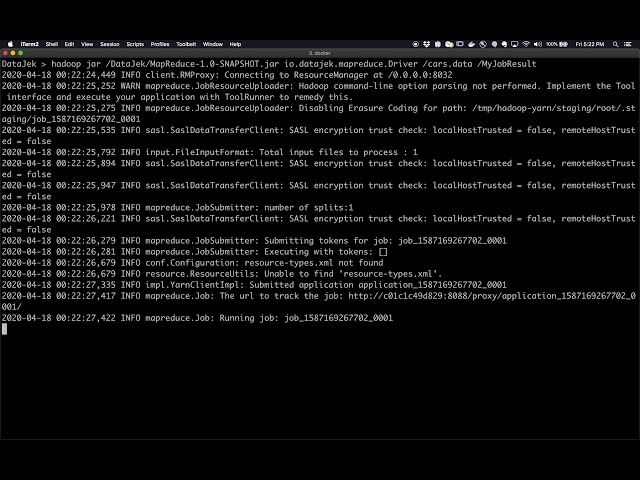
After submitting, a successful run should produce the output similar to this screenshot:
The job run shows useful counters and related information. For example, the number of bytes read and written by Hadoop’s File Input Format are shown at the end. Note that, how the input bytes are significantly greater than input bytes. The output only consists of summed-up values per key.
File Input Format Counters
Bytes Read=463052
File Output Format Counters
Bytes Written=200
-
Next, we can list the contents of the directory MyJobResult as follows:
hdfs dfs -ls /MyJobResultThe listing shows two files. The empty file _SUCCESS is a marker file denoting the successful execution of the job. The second file, part-r-00000 contains the result by the reducer task.
-
We can cat or text the file like this:
hdfs dfs -text /MyJobResult/part-r-00000
Observe the summed-up counts for each car brand.
- The execution of the job is also visible in the web UIs of YARN and the job history server. Below is a screen-shot of the YARN web UI:
Because we are also running the job history server, the job details can be found there too:
For convenience, we capture running all these steps in the video below:
Finally, you can see the YARN UI as it would look with the job submitted for execution. The job is submitted only once and subsequent clicks may show the job as complete. Click around the UI and the job links to explore various details.
Note, that the UI will not load in the widget below. Click on the URL link beside the message “Your app can be found at” or wait for the Firefox message to load “Open Site in New Window” and click on that. The YARN UI may be slow to load, so please be patient.