

![Image from Medium, [C++] Concurrency by Valentina](/api/page/6705609052258304/image/download/6277800983003136?collection_token=undefined&get_optimised=true "Image from Medium, [C++] Concurrency by Valentina")
Threading models in C++ are techniques for managing and executing multiple threads concurrently, improving application performance and responsiveness.
Table of Contents
A tutorial on modern multithreading and concurrency in C++
21 mins read
Jun 09, 2026
Share
In the modern tech climate, concurrency has become an essential skill for all CPP programmers. As programs continue to get more complex, computers are designed with more CPU cores to match.
The best way for you to make use of these multicore machines is the coding technique of concurrency.
In this tutorial, we’ll get you familiar with concurrent programming and multithreading with the basics and real-world examples you’ll need to know.
Here’s what we’ll cover today:
- What is concurrency?
- Methods of implementing concurrency
- Examples of multithreading
- C++ concurrency in action: real-world applications
- Resources
Get hands-on with C++ today
Modern C++ Concurrency: Get the most out of any machine
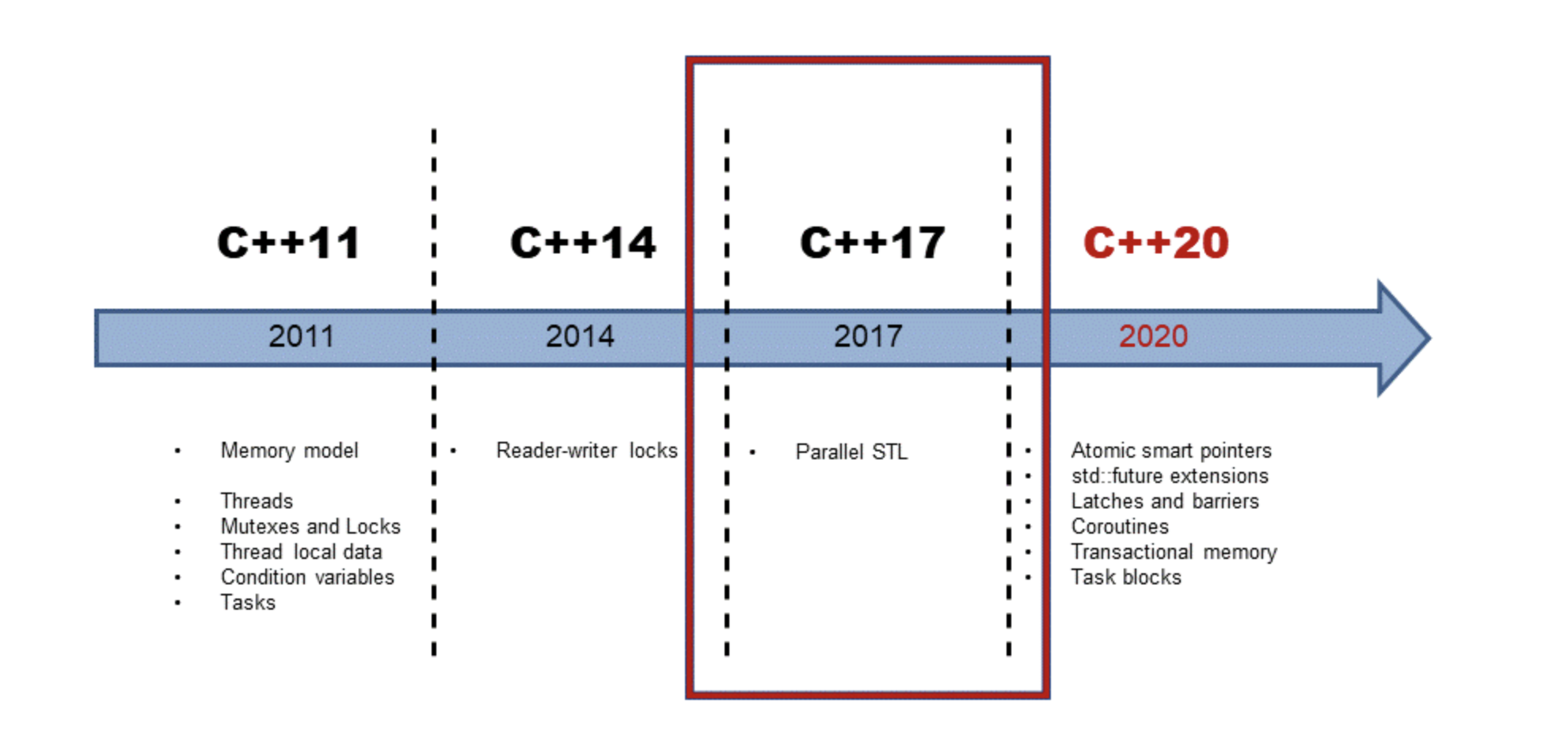
"Concurrency with Modern C++" is a journey through the present and upcoming concurrency features in C++. - C++11 and C++14 have the basic building blocks for creating concurrent and parallel programs. - With C++17 we have the parallel algorithms from the Standard Template Library (STL). That means that most STL based algorithms can be executed sequentially, parallel, or vectorized. - The concurrency story in C++ goes on. With C++20 we can hope for extended futures, co-routines, transactions, and more. In addition to explaining the details of concurrency in modern C++, this course gives you many interactive code examples; therefore, you can combine theory with practice to get the most out of it. Apart from theory, this course contains a lot of real-world scenarios and use-cases along with pitfalls and how to overcome them using best practices.
What is concurrency? #
Concurrency occurs when multiple copies of a program run simultaneously while communicating with each other.
Simply put, concurrency is when two tasks are overlapped. A simple concurrent application will use a single machine to store the program’s instruction, but that process is executed by multiple, different threads.
This setup creates a kind of control flow, where each thread executes its instruction before passing to the next one.
The threads act independently and to make decisions based on the previous thread as well. However, some issues can arise in concurrency that make it tricky to implement.
For example, a data race is a common issue you may encounter in C++ concurrency and multi-threaded processes. Data races in C++ occur when at least two threads can simultaneously access a variable or memory location, and at least one of those threads tries to access that variable.
This can result in undefined behavior. Regardless of its challenges, concurrency is very important for handling multiple tasks at once.
History of C++ concurrency#
C++11 was the first C++ standard to introduce concurrency, including threads, the C++ memory model, conditional variables, mutex, and more. The C++11 standard changes drastically with C++17.
The addition of parallel algorithms in the Standard Template Library (STL) greatly improved concurrent code.
Concurrency vs. parallelism#
Concurrency and parallelism often get mixed up, but it’s important to understand the difference. In parallelism, we run multiple copies of the same program simultaneously, but they are executed on different data.
For example, you could use parallelism to send requests to different websites but give each copy of the program a different set of URLs. These copies are not necessarily in communication with each other, but they are running at the same time in parallel.
As we explained above, concurrent programming involves a shared memory location, and the different threads actually “read” the information provided by the previous threads.
Image from EdPresso shot, "What is concurrent programming?"
Methods of Implementing Concurrency #
In C++, the two most common ways of implementing concurrency are through multithreading and parallelism. While these can be used in other programming languages, C++ stands out for its concurrent capabilities with lower than average overhead costs as well as its capacity for complex instruction.
Below, we’ll explore concurrent programming and multithreading in C++ programming.
C++ Multithreading#
C++ multithreading involves creating and using thread objects, seen as std::thread in code, to carry out delegated sub-tasks independently.
New threads are passed a function to complete, and optionally some parameters for that function.
Image from Medium, [C++] Concurrency by Valentina
While each individual thread can complete only one function at a time, thread pools allow us to recycle and reuse thread objects to give programs the illusion of unlimited multitasking.
Not only does this take advantage of multiple CPU cores, but it also allows the developer to control the number of tasks taken on by manipulating the thread pool size. The program can then use the computer resources efficiently without overloading becoming overloaded.
To better understand thread pools, consider the relationship of worker bees to a hive queen:
The queen (the program) has a broader goal to accomplish (the survival of the hive) while the workers (the threads) only have their individual tasks given by the queen.
Once these tasks are completed, the bees return to the queen for further instruction. At any one time, there is a set number of these workers being commanded by the queen, enough to utilize all of its hive space without overcrowding it.
Enjoying the article? Scroll down to sign up for our free, bi-monthly newsletter.
Parallelism#
Creating different threads is typically expensive in terms of both time and memory overhead for the program. Multithreading can therefore be wasteful when dealing with short simpler functions.
For times like these, developers can instead use parallel execution policy annotations, a way of marking certain functions as candidates for concurrency without creating threads explicitly.
At its most basic, there are two marks that can be encoded into a function. The first is parallel, which suggests to the compiler that the function be completed concurrently with other parallel functions. The other is sequential, meaning that the function must be completed individually.
Parallel functions can significantly speed up operations because they automatically use more of the computer’s CPU resources.
However, it is best saved for functions that have little interaction with other functions using dependencies or data editing. This is because while they are worked on concurrently, there is no way to know which will complete first, meaning the result is unpredictable unless synchronization such as mutex or condition variables are used.

Parallel execution of separate threads
Imagine we have two variables, A and B, and create functions addA and addB, which add 2 to their value.
We could do so with parallelism, as the behavior of addA is independent on the behavior of the other parallel function addB, and therefore has no problem executing concurrently.

Parallel functions that create unexpected outcomes
However, if the functions both impacted the same variable, we would instead want to use sequential execution.
Imagine that we instead had one which multiplied variable A by two, doubleA, and another which added B to A, addBtoA.
In this case, we would not want to use parallel execution as the outcome of this set of functions depends on which is completed first and would, therefore, result in a race condition.
While both multithreading and parallelism are helpful concepts for implementing concurrency in a C++ program, multithreading is more widely applicable due to its ability to handle complex operations. In the next section, we’ll look at a code example of multithreading at its most basic.
Get hands-on with C++ today.
Modern C++ Concurrency: Get the most out of any machine
"Concurrency with Modern C++" is a journey through the present and upcoming concurrency features in C++. - C++11 and C++14 have the basic building blocks for creating concurrent and parallel programs. - With C++17 we have the parallel algorithms from the Standard Template Library (STL). That means that most STL based algorithms can be executed sequentially, parallel, or vectorized. - The concurrency story in C++ goes on. With C++20 we can hope for extended futures, co-routines, transactions, and more. In addition to explaining the details of concurrency in modern C++, this course gives you many interactive code examples; therefore, you can combine theory with practice to get the most out of it. Apart from theory, this course contains a lot of real-world scenarios and use-cases along with pitfalls and how to overcome them using best practices.
Modern C++20 concurrency features#
C++ has supported multithreading since C++11 through tools like std::thread, mutexes, condition variables, and atomic operations. These features remain essential, but they often require careful resource management and can be difficult to use correctly in large applications.
C++20 expands the concurrency toolkit with safer and more expressive abstractions. New features such as std::jthread, coroutines, std::latch, and std::barrier make it easier to manage thread lifecycles, coordinate work between threads, and write asynchronous code.
Rather than replacing existing concurrency primitives, these features build on them and address common pain points developers have faced for years.
If you are learning C++ concurrency today, learn
std::threadfirst, then move tostd::jthreadand C++20 synchronization tools.
std::jthread#
One of the most useful additions in C++20 is std::jthread, a safer alternative to std::thread.
With std::thread, forgetting to call join() or detach() before a thread object is destroyed results in program termination. std::jthread automatically joins when it goes out of scope, reducing the risk of thread-management bugs.
Traditional std::thread#
#include <thread>#include <iostream>void worker() {std::cout << "Working...\n";}int main() {std::thread t(worker);t.join(); // Must be called manually}
C++20 std::jthread#
#include <thread>#include <iostream>void worker() {std::cout << "Working...\n";}int main() {std::jthread t(worker);// Automatically joined when t goes out of scope}
Cooperative cancellation#
Another advantage of std::jthread is support for stop tokens.
#include <thread>#include <chrono>#include <iostream>void worker(std::stop_token stopToken) {while (!stopToken.stop_requested()) {std::cout << "Running...\n";std::this_thread::sleep_for(std::chrono::milliseconds(500));}}int main() {std::jthread t(worker);std::this_thread::sleep_for(std::chrono::seconds(2));t.request_stop();}
This makes cancellation much cleaner than manually managing shared flags.
Coroutines#
Coroutines are one of the most significant additions to modern C++. They allow functions to pause and resume execution without blocking a thread.
Traditional asynchronous code often relies on callbacks, state machines, or complex thread management. Coroutines make these workflows much easier to express.
Key coroutine keywords#
Keyword | Purpose |
| Suspend until an async operation completes |
| Produce a value and pause |
| Return a final result |
Conceptual example#
Task fetchData() {auto result = co_await networkRequest();co_return result;}
Instead of manually tracking state, the compiler generates the machinery needed to suspend and resume execution.
Common use cases#
Coroutines are particularly useful for:
Networking applications
Web servers
Database operations
Event-driven systems
Generators and streams
High-performance asynchronous APIs
A useful mental model is to think of coroutines as functions that can "pause here and continue later."
std::latch#
A std::latch allows multiple threads to wait until a counter reaches zero.
Unlike condition variables, a latch is simple to use when you only need one synchronization point.
When to use it#
A common use case is waiting for multiple worker threads to finish initialization before continuing.
Example#
#include <iostream>#include <thread>#include <latch>std::latch startupLatch(3);void worker(int id) {std::cout << "Worker " << id << " ready\n";startupLatch.count_down();startupLatch.wait();std::cout << "Worker " << id << " started\n";}int main() {std::thread t1(worker, 1);std::thread t2(worker, 2);std::thread t3(worker, 3);t1.join();t2.join();t3.join();}
Important characteristic#
A latch is one-time use only.
Once the counter reaches zero, it cannot be reset.
Think of a latch as a starting gate that opens once and never closes again.
std::barrier#
A std::barrier is similar to a latch, but it can be reused multiple times.
This makes it useful for applications where threads repeatedly synchronize at different stages of execution.
When to use it#
Typical scenarios include:
Scientific computing
Simulation systems
Parallel algorithms
Multi-stage processing pipelines
Example#
#include <barrier>#include <thread>#include <iostream>std::barrier syncPoint(3);void worker(int id) {std::cout << "Thread " << id << " Phase 1\n";syncPoint.arrive_and_wait();std::cout << "Thread " << id << " Phase 2\n";syncPoint.arrive_and_wait();std::cout << "Thread " << id << " Phase 3\n";}int main() {std::thread t1(worker, 1);std::thread t2(worker, 2);std::thread t3(worker, 3);t1.join();t2.join();t3.join();}
Each thread waits until all participants reach the synchronization point before moving to the next phase.
Unlike a latch, the barrier remains available for future synchronization phases.
Comparing modern C++ concurrency tools#
| Basic thread creation | Yes | Low-level concurrency | Foundation of C++ threading |
| Safer thread lifecycle management | Yes | General-purpose threading | Usually preferred over std::thread |
Coroutines | Asynchronous workflows | Yes | Networking and async systems | Makes async code easier to write |
| One-time synchronization | No | Waiting for setup or initialization | Think "countdown gate" |
| Repeated synchronization phases | Yes | Multi-stage parallel algorithms | Think "meeting point" |
When should you use each?#
Use std::jthread when:#
You need safer thread ownership
Automatic joining is beneficial
You want built-in cancellation support
You're writing new C++20 code
For most modern applications, std::jthread is a better default than std::thread.
Use coroutines when:#
Building asynchronous applications
Writing network services
Handling large numbers of concurrent operations
Avoiding callback-heavy code
Coroutines improve readability and scalability for async workflows.
Use std::latch when:#
You need one-time synchronization
Worker threads must finish setup before execution begins
A countdown mechanism is sufficient
Use std::barrier when:#
Threads repeatedly synchronize
Work happens in multiple phases
Parallel algorithms need coordination
Use std::thread when:#
Working with older standards
You need maximum control
Compatibility is important
Existing codebases already use it extensively
Practical guidance#
A good progression for learning modern C++ concurrency looks like this:
std::thread↓Mutexes & Condition Variables↓std::jthread↓std::latch / std::barrier↓Coroutines↓Production-Grade Concurrent Systems
Start by understanding how threads work, then move toward the safer abstractions introduced in C++20.
A note on safety#
While these features improve ergonomics and reduce common mistakes, they do not eliminate concurrency bugs.
You still need to understand:
Race conditions
Shared state
Synchronization
Atomic operations
Memory visibility
Modern tools make concurrent code easier to write, but correctness still depends on careful design.
C++20 significantly improves the concurrency experience. std::jthread provides safer thread management, coroutines simplify asynchronous programming, and synchronization primitives like std::latch and std::barrier make thread coordination more intuitive.
For most developers learning concurrency today, mastering std::thread and then adopting these C++20 features is one of the best ways to build modern, scalable, and maintainable concurrent applications.
Understanding the C++ memory model#
When developers first learn multithreading, they often focus on creating threads with std::thread and synchronizing them with mutexes. However, the real foundation of concurrent programming lies deeper: understanding how threads interact with memory.
The C++ memory model defines the rules that govern shared memory access between threads. Without these rules, programs could behave differently depending on the compiler, operating system, or CPU architecture being used. The memory model provides a common set of guarantees that make concurrent code predictable and portable.
Understanding the memory model is important because many concurrency bugs aren't caused by thread creation itself. Instead, they're caused by threads seeing stale data, reading values unexpectedly, or modifying shared memory without proper synchronization.
Many concurrency bugs are actually memory visibility problems rather than thread creation problems.
What is the C++ memory model?#
The C++ memory model defines how threads interact with shared memory.
Specifically, it establishes:
Rules for reading and writing shared data
Visibility guarantees between threads
Synchronization requirements
Ordering constraints for memory operations
Portable behavior across compilers and CPU architectures
Without a memory model, two threads could observe completely different views of the same data, making reliable concurrent programming nearly impossible.
A useful way to think about the memory model is that it acts as a contract between:
Your code
The compiler
The operating system
The hardware
That contract defines what behavior is allowed and what behavior is not.
Why C++11 introduced the memory model#
Before C++11, multithreaded behavior was not formally defined by the language standard.
This created several problems:
Compilers could perform aggressive optimizations that broke threaded code.
Hardware architectures had different memory visibility rules.
Portable concurrent programming was difficult.
Developers often relied on platform-specific behavior.
C++11 introduced a standardized memory model so that concurrency primitives such as:
std::threadstd::mutexstd::condition_variablestd::atomic
could behave consistently across platforms.
This was one of the most important changes in modern C++ because it provided a formal foundation for multithreaded programming.
Data races and undefined behavior#
One of the most important concepts in the memory model is the data race.
A data race occurs when:
Two or more threads access the same memory location.
At least one thread performs a write.
No synchronization mechanism is used.
Example#
#include <thread>#include <iostream>int counter = 0;void increment() {for (int i = 0; i < 100000; i++) {counter++;}}int main() {std::thread t1(increment);std::thread t2(increment);t1.join();t2.join();std::cout << counter << '\n';}
At first glance, you might expect:
200000
But because both threads modify counter simultaneously without synchronization, the result is undefined.
Possible outcomes include:
182341193452200000
or even more surprising behavior.
Why is this dangerous?#
The compiler and CPU are allowed to reorder operations and perform optimizations that assume no data race exists.
Once a data race occurs, the C++ standard considers the program's behavior undefined.
Atomic operations#
To safely share simple values between threads, C++ provides std::atomic.
An atomic operation completes as a single indivisible action from the perspective of other threads.
Atomic counter example#
#include <atomic>#include <thread>#include <iostream>std::atomic<int> counter{0};void increment() {for (int i = 0; i < 100000; i++) {counter++;}}int main() {std::thread t1(increment);std::thread t2(increment);t1.join();t2.join();std::cout << counter << '\n';}
Output:
200000
Why atomics work#
Atomic operations:
Prevent data races
Ensure updates are visible between threads
Often avoid the overhead of mutexes
Can be implemented using hardware-supported instructions
Atomics are particularly useful for:
Counters
Flags
Reference counts
State indicators
However, they are not a replacement for mutexes when dealing with complex shared data structures.
Memory ordering#
One of the more advanced aspects of the memory model is memory ordering.
Memory ordering controls how operations become visible to other threads.
The most common memory orderings are:
Memory Order | Intuition |
| Atomicity only, minimal ordering guarantees |
| Read synchronization point |
| Write synchronization point |
| Strongest and easiest-to-reason-about ordering |
memory_order_relaxed#
counter.fetch_add(1, std::memory_order_relaxed);
Provides atomicity but minimal synchronization guarantees.
Useful for:
Statistics counters
Metrics
Independent values
memory_order_release#
Used when publishing data.
ready.store(true, std::memory_order_release);
This tells other threads that preceding writes should become visible before the flag is observed.
memory_order_acquire#
Used when consuming published data.
if (ready.load(std::memory_order_acquire)) {// Safe to access published data}
Acquire and release often work together.
memory_order_seq_cst#
counter++;
Most atomic operations default to sequential consistency.
This is the easiest ordering to reason about because it creates behavior that resembles a single global execution order.
For beginners, memory_order_seq_cst is usually the best choice until performance requirements justify more advanced orderings.
Memory visibility: a visual explanation#
Thread Awrites data↓memory synchronization↓Thread Bsees updated data
The key idea is that writing data is not enough.
Without synchronization:
Thread A updates value↓Thread B may still see old value
Synchronization creates a visibility guarantee.
This distinction is one of the most important ideas in concurrent programming.
The problem is often not whether a thread executed—it is whether another thread can reliably see the result.
When should you use atomics vs mutexes?#
Complexity | Higher | Lower for complex state |
Performance | Often faster | More overhead |
Use cases | Counters, flags, simple shared values | Complex shared objects |
Protection scope | Single variables | Multiple related operations |
Use atomics when:#
Managing counters
Tracking status flags
Updating simple numeric values
Building lock-free structures
Use mutexes when:#
Multiple variables must remain consistent
Updating complex objects
Protecting containers such as vectors or maps
Simplicity is more important than micro-optimizations
A common rule of thumb is:
If you're sharing a single value, consider an atomic. If you're sharing a data structure, use a mutex.
Common memory model interview questions#
What is a data race?#
A data race occurs when multiple threads access the same memory location, at least one access is a write, and no synchronization mechanism is used.
What is std::atomic?#
std::atomic provides thread-safe operations on shared values without requiring a mutex.
What is memory ordering?#
Memory ordering controls how reads and writes become visible across threads and defines synchronization guarantees.
Why does C++ need a memory model?#
The memory model provides portable rules for concurrent programming and ensures consistent behavior across compilers and hardware platforms.
Atomic vs mutex?#
Atomics work well for simple shared values. Mutexes are generally preferred for protecting complex shared state.
Best practices#
A few habits can prevent many concurrency bugs:
Avoid unsynchronized shared state whenever possible.
Prefer higher-level synchronization primitives over custom lock-free solutions.
Use
std::atomiconly when it genuinely simplifies the problem.Favor correctness over premature performance optimization.
Keep shared mutable state to a minimum.
Use thread sanitizers during development.
Document synchronization assumptions clearly.
For most applications, a correct mutex-based solution is better than a complicated lock-free solution that's difficult to maintain.
Takeaway#
The C++ memory model is the foundation of modern concurrency. It defines how threads interact with shared memory, establishes visibility guarantees, and provides the rules that synchronization primitives rely on.
You don't need to memorize every memory-ordering detail to write concurrent programs, but understanding data races, atomics, visibility, and synchronization will help you reason about thread interactions and avoid some of the most subtle bugs in software development.
Lock-free programming with std::atomic#
As concurrent applications scale across more CPU cores, synchronization overhead can become a significant performance bottleneck. Traditional locking mechanisms such as mutexes are simple and reliable, but they can force threads to wait for one another, reducing parallelism and throughput.
This is where lock-free programming comes in. Instead of coordinating access through locks, threads communicate using atomic operations that allow safe concurrent access to shared data without blocking. The result can be lower latency, reduced contention, and better scalability under heavy workloads.
It's important to understand that lock-free programming is not synchronization-free programming. Synchronization still exists—it simply happens through carefully designed atomic operations rather than traditional mutexes.
Many high-performance systems use lock-free techniques selectively rather than attempting to make the entire application lock-free.
What is lock-free programming?#
Lock-free programming is a concurrency technique in which threads coordinate access to shared data without using mutexes or other blocking locks.
Instead of this:
Thread A↓Acquire mutex↓Modify data↓Release mutex
lock-free code relies on atomic operations:
Thread A↓Atomic operation↓Shared state updated safely
The primary goals are:
Reduce thread contention
Avoid blocking
Improve scalability
Increase throughput on multicore systems
Lock-free programming is particularly useful in systems where even small delays can impact performance.
Why locks can be expensive#
Mutexes are extremely useful, but they are not free.
When many threads compete for the same lock, several costs appear:
Thread contention
Context switching
Blocking
Cache synchronization overhead
Reduced scalability
Mutex-protected counter#
#include <iostream>#include <thread>#include <mutex>int counter = 0;std::mutex mtx;void increment() {for (int i = 0; i < 100000; i++) {std::lock_guard<std::mutex> lock(mtx);counter++;}}
This code is correct, but every increment requires acquiring and releasing the mutex.
As the number of threads grows, the lock can become a bottleneck because only one thread can modify the counter at a time.
Introducing std::atomic#
The C++ standard library provides std::atomic, which allows certain operations to be performed atomically.
Atomic operations are indivisible from the perspective of other threads.
Example 1: Atomic counter#
#include <atomic>#include <thread>#include <iostream>std::atomic<int> counter{0};void increment() {for (int i = 0; i < 100000; i++) {counter++;}}int main() {std::thread t1(increment);std::thread t2(increment);t1.join();t2.join();std::cout << counter << '\n';}
#include <atomic>#include <thread>#include <iostream>std::atomic<bool> ready{false};void worker() {while (!ready.load()) {// Wait}std::cout << "Started!\n";}int main() {std::thread t(worker);ready.store(true);t.join();}
#include <atomic>#include <iostream>int main() {std::atomic<int> value{10};int expected = 10;if (value.compare_exchange_strong(expected, 20)) {std::cout << "Update successful\n";}}
Feature | std::atomic | std::mutex |
Blocking behavior | Non-blocking | Blocking |
Performance | Often faster for simple operations | Higher overhead |
Ease of use | More difficult | Easier |
Complexity | Higher | Lower |
Suitable workloads | Counters, flags, lock-free structures | Complex shared state |
Scalability | Excellent for simple shared data | Can degrade under contention |
Key takeaway#
Atomics excel when:
Only a few shared values exist
Operations are simple
Throughput matters
Mutexes excel when:
Multiple variables must remain consistent
Shared objects are complex
Code maintainability is important
Real-world lock-free applications#
Lock-free programming is commonly used in systems where performance and latency are critical.
High-frequency trading systems#
Financial platforms often process millions of events per second.
Even tiny synchronization delays can impact profitability.
Game engines#
Modern game engines coordinate rendering, physics, audio, and networking across multiple CPU cores.
Lock-free queues are frequently used for communication between subsystems.
Networking systems#
High-performance servers often rely on lock-free structures to process network events efficiently.
Databases#
Database engines use atomic operations for:
Reference counting
Internal synchronization
Transaction coordination
Message queues#
Distributed systems frequently implement lock-free queues to move messages between worker threads.
Operating system kernels#
Many kernel-level synchronization mechanisms rely heavily on atomic instructions rather than traditional locks.
Common lock-free interview questions#
What is lock-free programming?#
Lock-free programming allows multiple threads to coordinate access to shared data without using blocking locks such as mutexes.
What is std::atomic?#
std::atomic provides thread-safe atomic operations on shared variables and prevents data races.
Atomic vs mutex?#
Atomics work best for simple shared values. Mutexes are usually better for protecting complex shared state.
What is compare-and-swap?#
Compare-and-swap (CAS) updates a value only if it still matches an expected value. It is a fundamental building block for many lock-free algorithms.
Why aren't atomics used everywhere?#
Because lock-free programming is significantly more complex. Many problems are easier, safer, and more maintainable when solved with mutexes.
Challenges of lock-free programming#
Lock-free programming offers impressive performance benefits, but it comes with trade-offs.
Increased complexity#
Correct lock-free algorithms are much harder to design and reason about than mutex-based solutions.
Memory ordering issues#
Developers must understand the C++ memory model and visibility guarantees.
Incorrect memory ordering can introduce subtle bugs.
Difficult debugging#
Race conditions and timing-related bugs can be extremely difficult to reproduce.
ABA problem#
A classic lock-free issue occurs when:
Value = A↓Changed to B↓Changed back to A
A compare-and-swap operation may incorrectly assume nothing changed.
Many advanced lock-free structures must explicitly address this problem.
Best practices#
When working with lock-free programming:
Start with mutexes unless performance requirements justify lock-free solutions.
Use
std::atomicfor simple shared variables such as counters and flags.Measure before optimizing.
Favor correctness over micro-optimizations.
Understand the C++ memory model before writing lock-free code.
Keep lock-free algorithms as simple as possible.
Use profiling and benchmarking to validate improvements.
A common engineering rule is:
If a mutex meets your performance goals, use the mutex.
Lock-free programming is an advanced optimization technique that helps high-performance systems scale under heavy concurrency. Rather than relying on blocking locks, it uses atomic operations to coordinate threads safely and efficiently.
std::atomic provides the foundation for lock-free programming in modern C++, enabling atomic reads, writes, increments, and compare-and-swap operations. While lock-free techniques can deliver significant performance benefits, they also introduce additional complexity.
In practice, most production systems combine atomics, mutexes, and higher-level synchronization primitives, choosing the right tool for each problem rather than trying to make everything lock-free.
Multithreading Examples #
In the following examples, we’ll look at some simple multithreaded programs designed to use a print function which we declare at the beginning.
Simple One-Thread example#
Since all threads must be given a function to complete at their creation, we first must declare a function for it to be given. We’ll name this function print, and will design it to take int and string arguments when called. When executed, this code will simply report the data values passed in.
void print(int n, const std::string &str) {
std::cout << "Printing integer: " << n << std::endl;
std::cout << "Printing string: " << str << std::endl;
}
In the next section, we’ll initialize a thread and have it execute the above function. To do this, we’ll have the main function, the default executor present in all C++ applications, initialize the thread for the print function.
After that, we use another handy multithreading command, join(), pausing the main function’s thread until the specified thread, in this case t1, has finished its task. Without join() here, the main thread would finish its task before t1 would complete print, resulting in an error.
int main() {
std::thread t1(print, 10, "Educative.blog");
t1.join();
return 0;
}
Multi-Thread Example#
While the outcome of the single thread example above could easily be replicated without using multithreaded code, we can truly see concurrency’s benefits when we attempt to complete print multiple times with different sets of data. Without multithreading, this would be done by simply having the main thread repeat print one at a time until completion.
To do this with concurrency in mind, we instead use a for loop to initialize multiple threads, pass them the print function and arguments, which they then complete concurrently. This multithreading option would be faster one using only the main thread as more of the total CPU is being used.
Runtime difference between multithreading and non-multithreading solutions increasing as more print executions are needed.
Let’s see what a many-thread version of the above code would look like:
C++ concurrency in action: real-world applications #
Multithreading programs and multithreaded applications are common in modern business systems, in fact, you likely use some more complex versions of the above programs in your everyday life.
Example 1: Email Server#
One example could be an email server, returning mailbox contents when requested by a user. With this program, we have no way of knowing how many people will be requesting their mail at any given time.
By using a thread pool, the program can process as many user requests as possible without risking an overload.
As above, each thread would execute a defined function, such as receiving the mailbox of the identifier passed in, void request_mail (string user_name).
Example 2: Web Crawler#
Another example could be a web crawler, which downloads pages across the web. By using multithreading, the developer would ensure that the web crawler is using as much of the hardware’s capability as possible to download and index multiple pages at once.
Based on just these two examples, we can see the breadth of functions in which concurrency can be advantageous. With the number of CPU cores in each computer increasing by the year, concurrency is certain to remain an invaluable asset in the arsenal of the modern developer.
Steps Forward and Resources #
In this article, we merely scratched the surface of what’s possible with multithreading and concurrency in C++.
To help you continue your concurrency journey, Educative has created the course Modern C++ Concurrency.
This course is full of insider tips, case studies, extensive sample code. By the end, you’ll have hands-on experience with concurrency projects on shared data, optimization, resolving data races, and more.
Continue reading about concurrency#
Frequently Asked Questions
What are the threading models in C++?
What are the threading models in C++?
Written By:
Ryan Thelin
Related Courses
Learn C++: The Complete Course for BeginnersC++20 STL CookbookC++ Fundamentals for ProfessionalsCompetitive Programming in C++: The Keys to SuccessC++ Programming for Experienced EngineersLearn to Code: C++ for Absolute BeginnersData Structures for Coding Interviews in C++Modern CMake for C++Learning OpenCV from Scratch with C++Data Structures with Generic Types in C++Mastering Algorithms for Problem Solving in C++Beginner to Advanced Computing and Logic BuildingDecode the Coding Interview in C++: Real-World ExamplesCompetitive Programming - Crack Your Coding Interview, C++Implementing an Advanced Huge Integer Class
