






Facebook coding interviews are generally considered to be challenging. Like many other top tech companies, Facebook sets a high bar for technical talent, and their interview process reflects this.
Table of Contents
Cracking the top 40 Facebook coding interview questions
28 mins read
Jun 10, 2026
Share
Landing a job at Facebook is a dream for many developers around the globe. Facebook is one of the top tech companies in the world, with a workforce of over 52,000 strong. Facebook is known for its growth-based company culture, fast promotion tracks, excellent benefits, and top salaries that few companies can match.
But competition is fierce, and with a swell of new hires, Facebook is on the lookout for the top candidates. Facebook focuses on your cultural fit, generalist knowledge, ability to build within constraints, and expert coding skills.
To help you prepare, today I will walk through everything you need to crack an Facebook interview, including coding questions and a step-by-step preparation guide.
Today we will go over:
- Overview of the Facebook coding interview
- Top 40 Facebook coding interview questions
- How to prepare for a Facebook interview
- Wrapping up and resource list
Overview of the Facebook coding interview
To land a software engineering job at Facebook, you need to know what lies ahead. The more prepared you are, the more confident you will be. So, let’s break it down.
For a deeper dive into Facebook’s interview process, check out Coding Interviews’s free Facebook Coding Interview Guide.
- Interview Timeline: From resume submission to job offer, the process lasts 1.5 to 2 months.
- Types of Interviews: The interview process consists of 6 to 7 interviews. This includes 1 pre-screen interview (20 minutes), 1 technical phone interview (50 minutes, 1-2 coding questions), and 4-5 on-site interviews (45 minutes each).
- On-site interviews: Facebook breaks the on-site interviews into three sections. The Ninja portion consists of 2 coding interviews using a whiteboard. The Pirate portion includes 2 system design interviews. The Jedi portion includes 1 cultural/behavioral interview.
-
Coding Questions: Facebook interview questions focus on generalist knowledge on algorithms, data structures, and time complexity. They also test on architecture and system design (even entry level).
-
Hiring Levels: Facebook normally hires at level E3 for entry level software roles with E9 behind the height of levels. E5 is considered an entry-level manager role.
-
Hiring Teams: Central hires for Oculus, Facebook Groups, and WhatsApp.
-
Programming languages: Facebook prefers most standard languages, including Java, C++, Python, Ruby, and Perl.
What’s different about Facebook interviews?#
System design interview:
- At Facebook, you can expect these questions no matter what level you are interviewing for.
Structured interviewing:
- Facebook will pair you with interviewers who have either held the position you’re interviewing for or with individuals who work directly with the position you’re interviewing for.
Core values and your behavioral interview:
- Facebook interviewers will also evaluate your ability to embody their five core values: Move Fast, Be Bold, Focus on Impact, Be Open, and Build Social Value.
Top 40 Facebook coding interview questions#
In this section, we’ll take a deep dive into the top 40 coding interview questions. We will discuss the answers and runtime complexities for the 15 questions you’re bound to see in an interview followed by the definitive list of 25 questions you’ll likely encounter.
As you can see to the right, Facebook focuses mostly on arrays and strings. These are essential skills to master.
Each question will be solved in Python 3. To see these solutions in C++, Ruby, Java, and JavaScript, visit here.
The coding patterns Meta interviewers test most often#
Meta coding interviews rarely test whether you've seen a specific problem before. Instead, they evaluate your ability to recognize underlying patterns and apply them to unfamiliar situations. While interview questions may look different on the surface, many are variations of the same core algorithmic ideas.
This is why strong candidates focus on mastering patterns rather than memorizing solutions. Once you recognize the pattern behind a problem, finding an efficient solution becomes much easier. The good news is that most Meta interview questions fall into a relatively small set of recurring categories.
Pattern overview#
Pattern | Why Meta Uses It | Example Problems |
Hash Maps | Fast lookups | Two Sum, Frequency Counting |
Two Pointers | Efficient array processing | Pair Sum, Valid Palindrome |
Sliding Window | Subarray optimization | Longest Substring Without Repeating Characters |
Trees & DFS | Hierarchical reasoning | Binary Tree Traversals |
Graph Traversal | Social network modeling | Friend Recommendations |
BFS | Shortest paths | Degrees of Separation |
Dynamic Programming | Optimization problems | Coin Change |
Backtracking | Search spaces | Generate Combinations |
Hash maps#
Hash maps are one of the most common tools in Meta interviews because they allow constant-time lookups and efficient data processing.
You'll often encounter this pattern when a problem asks you to:
Find duplicates
Count frequencies
Track previously seen values
Look up complements or matches
How to recognize it: If a brute-force solution requires nested loops, ask yourself whether a hash map can store information and reduce the time complexity.
Time complexity benefit: Often improves solutions from O(n²) to O(n).
Common Meta variations:
Two Sum
Group Anagrams
Frequency Counting
Longest Consecutive Sequence
Two pointers#
The two-pointer pattern uses two indices that move through a data structure simultaneously.
It's particularly useful when working with:
Sorted arrays
Palindrome problems
Pair-sum questions
Array partitioning
How to recognize it: If you're searching for pairs, comparing values from opposite ends, or processing a sorted array, two pointers may be the right approach.
Time complexity benefit: Often reduces solutions from O(n²) to O(n).
Common Meta variations:
Valid Palindrome
Container With Most Water
Pair Sum Problems
Removing Duplicates
Sliding window#
Sliding window is a specialized two-pointer technique used for contiguous subarrays and substrings.
Instead of recalculating results repeatedly, you expand and shrink a window while maintaining useful information.
How to recognize it: Look for keywords such as:
Longest
Shortest
Maximum
Minimum
Contiguous subarray
Substring
Time complexity benefit: Typically reduces brute-force O(n²) solutions to O(n).
Common Meta variations:
Longest Substring Without Repeating Characters
Maximum Sum Subarray
Minimum Window Substring
Longest Repeating Character Replacement
Trees and DFS#
Trees appear frequently because they test recursion, traversal techniques, and hierarchical reasoning.
Depth-first search (DFS) is commonly used to explore branches before backtracking.
How to recognize it: Parent-child relationships, hierarchical structures, recursive definitions, and binary trees are strong indicators.
Time complexity benefit: Efficient traversal in O(n) time for many tree problems.
Common Meta variations:
Binary Tree Maximum Depth
Validate Binary Search Tree
Lowest Common Ancestor
Path Sum
Graph traversal#
Graph problems are especially important at Meta because many Meta products are naturally modeled as graphs.
Users, friends, groups, pages, recommendations, and connections can all be represented as nodes and edges.
How to recognize it: If the problem involves relationships, networks, connections, or dependencies, think graph traversal.
Time complexity benefit: Efficient exploration using adjacency lists and graph algorithms.
Common Meta variations:
Clone Graph
Course Schedule
Friend Recommendation Systems
Network Connectivity Problems
Breadth-first search (BFS)#
BFS explores nodes level by level and is commonly used for shortest-path problems in unweighted graphs.
At Meta, BFS frequently appears in social-network scenarios where you need to determine how closely two users are connected.
How to recognize it: Questions involving minimum steps, shortest path, nearest neighbor, or degrees of separation often point to BFS.
Time complexity benefit: Finds shortest paths efficiently without exploring unnecessary routes.
Common Meta variations:
Word Ladder
Degrees of Separation
Social Network Distance
Level Order Traversal
Dynamic programming#
Dynamic programming (DP) solves complex problems by breaking them into overlapping subproblems and storing intermediate results.
Many candidates struggle with DP because pattern recognition is especially important.
How to recognize it: Look for phrases such as:
Maximum profit
Minimum cost
Number of ways
Optimal solution
Time complexity benefit: Can transform exponential-time solutions into polynomial-time solutions.
Common Meta variations:
Coin Change
House Robber
Longest Increasing Subsequence
Edit Distance
Backtracking#
Backtracking explores multiple possibilities while undoing decisions that don't lead to valid solutions.
It's commonly used when generating combinations, permutations, or searching large solution spaces.
How to recognize it: If the problem asks for all possible combinations, subsets, arrangements, or paths, consider backtracking.
Time complexity benefit: While often exponential, backtracking systematically prunes invalid paths.
Common Meta variations:
Generate Parentheses
Subsets
Permutations
N-Queens
Patterns most associated with Meta#
While every major tech company uses a broad range of interview topics, Meta interviews frequently emphasize graph-related thinking.
This makes sense when you consider Meta's products:
Facebook's friend graph
Instagram's follower graph
WhatsApp communication networks
Recommendation systems
Social connections and communities
Because of this, candidates should pay particular attention to:
Graph traversal
BFS
DFS
Tree structures
Relationship modeling problems
Many Meta interview questions are fundamentally about understanding connections between entities and efficiently navigating those relationships.
How to recognize a pattern during an interview#
One of the most valuable interview skills is quickly identifying which pattern applies to a problem.
Fast lookups or duplicate detection | Hash Maps |
Contiguous subarrays or substrings | Sliding Window |
Pair searches in sorted arrays | Two Pointers |
Parent-child relationships | Trees & DFS |
Networks and relationships | Graph Traversal |
Shortest path or minimum steps | BFS |
Optimal solution wording | Dynamic Programming |
All possible combinations | Backtracking |
Rather than asking, "Have I seen this exact problem before?", ask yourself, "Which pattern does this problem resemble?"
How to prepare effectively#
The most effective preparation strategy is to master patterns one at a time.
A practical order is:
Hash maps
Two pointers
Sliding window
Trees and DFS
BFS and graph traversal
Dynamic programming
Backtracking
As you solve problems, focus on understanding why a pattern works instead of memorizing code templates. Meta interviewers often introduce slight variations that reward reasoning over memorization.
Arrays: move zeros to the left#
Given an integer array, move all elements that are 0 to the left while maintaining the order of other elements in the array. The array has to be modified in-place. Try it yourself before reviewing the solution and explanation.

1 / 2
1. Take this integer array
Runtime complexity: Linear,
Memory Complexity: Constant,
Keep two markers: read_index and write_index and point them to the end of the array. Let’s take a look at an overview of the algorithm.
While moving read_index towards the start of the array:
- If
read_indexpoints to0, skip. - If
read_indexpoints to a non-zero value, write the value atread_indextowrite_indexand decrementwrite_index. - Assign zeros to all the values before the
write_indexand to the current position ofwrite_indexas well.
Arrays: Merge overlapping intervals#
You are given an array (list) of interval pairs as input where each interval has a start and end timestamp. The input array is sorted by starting timestamps. You are required to merge overlapping intervals and return a new output array.
Consider the input array below. Intervals (1, 5), (3, 7), (4, 6), (6, 8) are overlapping so they should be merged to one big interval (1, 8). Similarly, intervals (10, 12) and (12, 15) are also overlapping and should be merged to (10, 15).
Try it yourself before reviewing the solution and explanation.

Merge Intervals
Runtime complexity: Linear,
Memory Complexity: Linear,
This problem can be solved in a simple linear scan algorithm. We know that input is sorted by starting timestamps. Here is the approach we are following:
- List of input intervals is given, and we’ll keep merged intervals in the output list.
- For each interval in the input list:
- If the input interval is overlapping with the last interval in the output list then we’ll merge these two intervals and update the last interval of the output list with the merged interval.
- Otherwise, we’ll add an input interval to the output list.
Trees: Convert binary tree to doubly linked list#
Convert a binary tree to a doubly linked list so that the order of the doubly linked list is the same as an in-order traversal of the binary tree.
After conversion, the left pointer of the node should be pointing to the previous node in the doubly linked list, and the right pointer should be pointing to the next node in the doubly linked list. Try it yourself before reviewing the solution and explanation.
1 / 2
Runtime complexity: Linear,
Memory Complexity: Linear, .
Recursive solution has memory complexity as it will consume memory on the stack up to the height of binary tree
h. It will be for balanced trees and in the worst case can be .
In an in-order traversal, first the left sub-tree is traversed, then the root is visited, and finally the right sub-tree is traversed.
One simple way of solving this problem is to start with an empty doubly linked list. While doing the in-order traversal of the binary tree, keep inserting each element output into the doubly linked list.
But, if we look at the question carefully, the interviewer wants us to convert the binary tree to a doubly linked list in-place i.e. we should not create new nodes for the doubly linked list.
This problem can be solved recursively using a divide and conquer approach. Below is the algorithm specified.
- Start with the root node and solve left and right subtrees recursively
- At each step, once left and right subtrees have been processed:
- Fuse output of left subtree with root to make the intermediate result
- Fuse intermediate result (built in the previous step) with output from the right subtree to make the final result of the current recursive call.
Trees: Level order traversal of binary tree#
Given the root of a binary tree, display the node values at each level. Node values for all levels should be displayed on separate lines. Let’s take a look at the below binary tree.
Level order traversal for this tree should look like:
- 100
- 50, 200
- 25, 75, 350
Runtime complexity: Linear,
Memory Complexity: Linear,
Here, you are using two queues: current_queue and next_queue. You push the nodes in both queues alternately based on the current level number.
You’ll dequeue nodes from the current_queue, print the node’s data, and enqueue the node’s children to the next_queue.
Once the current_queue becomes empty, you have processed all nodes for the current level_number. To indicate the new level, print a line break (\n), swap the two queues, and continue with the above-mentioned logic.
After printing the leaf nodes from the current_queue, swap current_queue and next_queue. Since the current_queue would be empty, you can terminate the loop.
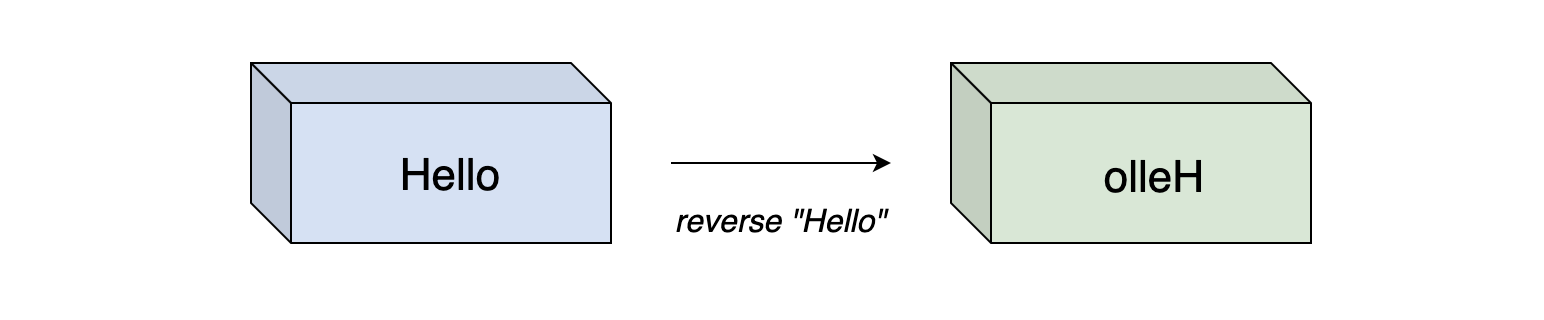
Strings: Reverse words in a sentence#
Reverse the order of words in a given sentence (an array of characters). Take the “Hello World” string for example:
Here is how the solution works:
- Reverse the string.
- Traverse the string and reverse each word in place.
For more on string reversal, read my article Best practices for reversing a string in JavaScript, C++, and Python.
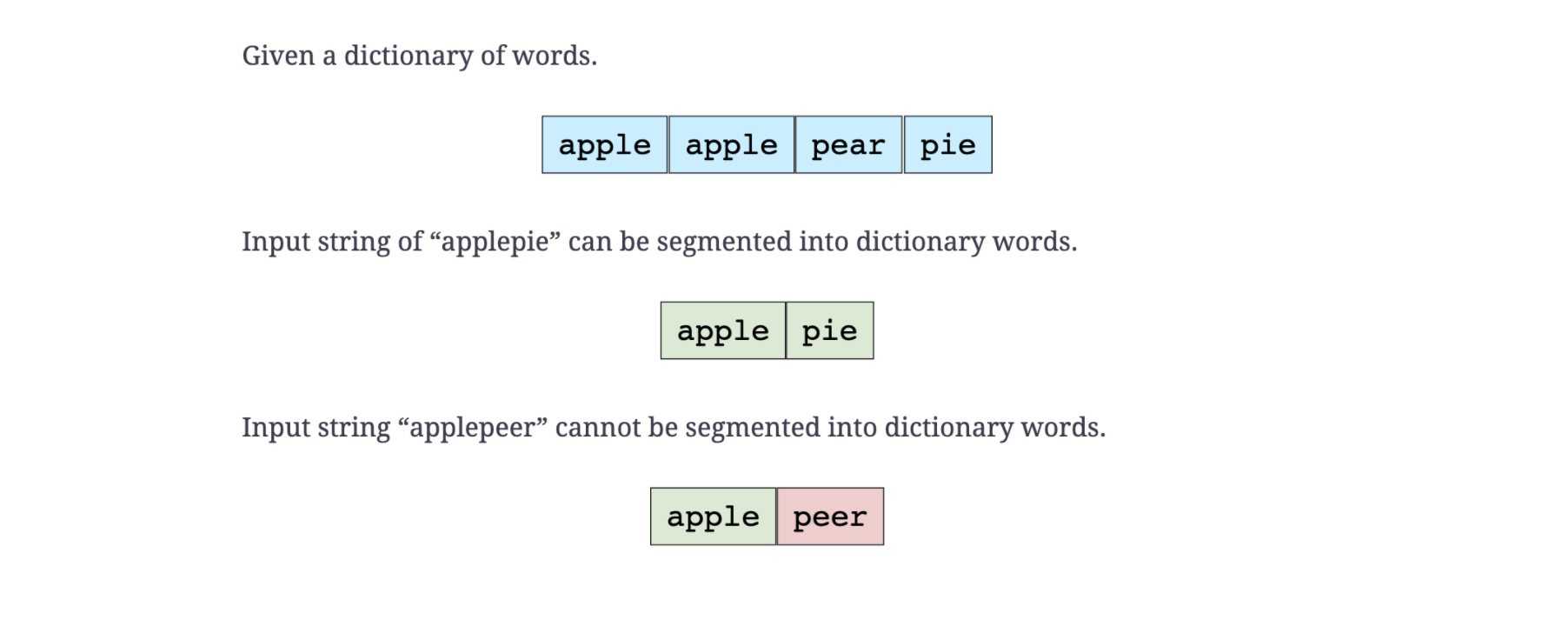
Strings: String segmentation#
You are given a dictionary of words and a large input string. You have to find out whether the input string can be completely segmented into the words of a given dictionary. The following example elaborates on the problem further.
Runtime complexity: Exponential, , if we only use recursion. With memoization, the runtime complexity of this solution can be improved to be polynomial, .
Memory Complexity: Polynomial,
You can solve this problem by segmenting the large string at each possible position to see if the string can be completely segmented to words in the dictionary. If you write the algorithm in steps it will be as follows:
n = length of input string
for i = 0 to n - 1
first_word = substring (input string from index [0, i] )
second_word = substring (input string from index [i + 1, n - 1] )
if dictionary has first_word
if second_word is in dictionary OR second_word is of zero length, then return true
recursively call this method with second_word as input and return true if it can be segmented
The algorithm will compute two strings from scratch in each iteration of the loop. Worst case scenario, there would be a recursive call of the second_word each time. This shoots the time complexity up to .
You can see that you may be computing the same substring multiple times, even if it doesn’t exist in the dictionary. This redundancy can be fixed by memoization, where you remember which substrings have already been solved.
To achieve memoization, you can store the second string in a new set each time. This will reduce both time and memory complexities.
Dynamic Programming: Find maximum single sell profit#
Given a list of daily stock prices (integers for simplicity), return the buy and sell prices for making the maximum profit.
We need to maximize the single buy/sell profit. If we can’t make any profit, we’ll try to minimize the loss. For the below examples, buy (orange) and sell (green) prices for making a maximum profit are highlighted.
Find maximum single sell profit
Find maximum single sell profit
Runtime complexity: Linear,
Memory Complexity: Constant,
The values in the array represent the cost of a stock each day. As we can buy and sell the stock only once, we need to find the best buy and sell prices for which our profit is maximized (or loss is minimized) over a given span of time.
A naive solution, with runtime complexity of , is to find the maximum gain between each element and its succeeding elements.
There is a tricky linear solution to this problem that requires maintaining current_buy_price (which is the smallest number seen so far), current_profit, and global_profit as we iterate through the entire array of stock prices.
At each iteration, we will compare the current_profit with the global_profit and update the global_profit accordingly.
The basic algorithm is as follows:
current buy = stock_prices[0]
global sell = stock_prices[1]
global profit = global sell - current buy
for i = 1 to stock_prices.length:
current profit = stock_prices[i] - current buy
if current profit is greater than global profit
then update global profit to current profit and update global sell to stock_prices[i]
if stock_prices[i] is less than current buy
then update current buy to stock_prices[i]
return global profit and global sell
Answer any Facebook interview problem by learning the patterns behind common questions.#
Math and Stats: Calculate the power of a number#
Given a double, x, and an integer, n, write a function to calculate x raised to the power n. For example:
power (2, 5) = 32
power (3, 4) = 81
power (1.5, 3) = 3.375
power (2, -2) = 0.25
Runtime complexity: Logarithmic,
Memory Complexity: Logarithmic,
A simple algorithm for this problem is to multiply x by n times. The time complexity of this algorithm would be . We can use the divide and conquer approach to solve this problem more efficiently.
In the dividing step, we keep dividing n by 2 recursively until we reach the base case i.e. n == 1
In the combining step, we get the result, r, of the sub-problem and compute the result of the current problem using the two rules below:
- If is even, the result is (where is the result of sub-problem)
- If is odd, the result is (where is the result of sub-problem).
Backtracking: Find all possible subsets#
We are given a set of integers and we have to find all the possible subsets of this set of integers.
Runtime complexity: Exponential, , where is the number of integers in the given set
Memory Complexity: Constant,
There are several ways to solve this problem. We will discuss the one that is neat and easier to understand. We know that for a set of ‘n’ elements there are subsets. For example, a set with 3 elements will have 8 subsets. Here is the algorithm we will use:
n = size of given integer set
subsets_count = 2^n
for i = 0 to subsets_count
form a subset using the value of 'i' as following:
bits in number 'i' represent index of elements to choose from original set,
if a specific bit is 1 choose that number from original set and add it to current subset,
e.g. if i = 6 i.e 110 in binary means that 1st and 2nd elements in original array need to be picked.
add current subset to list of all subsets
Note that the ordering of bits for picking integers from the set does not matter; picking integers from left to right would produce the same output as picking integers from right to left.
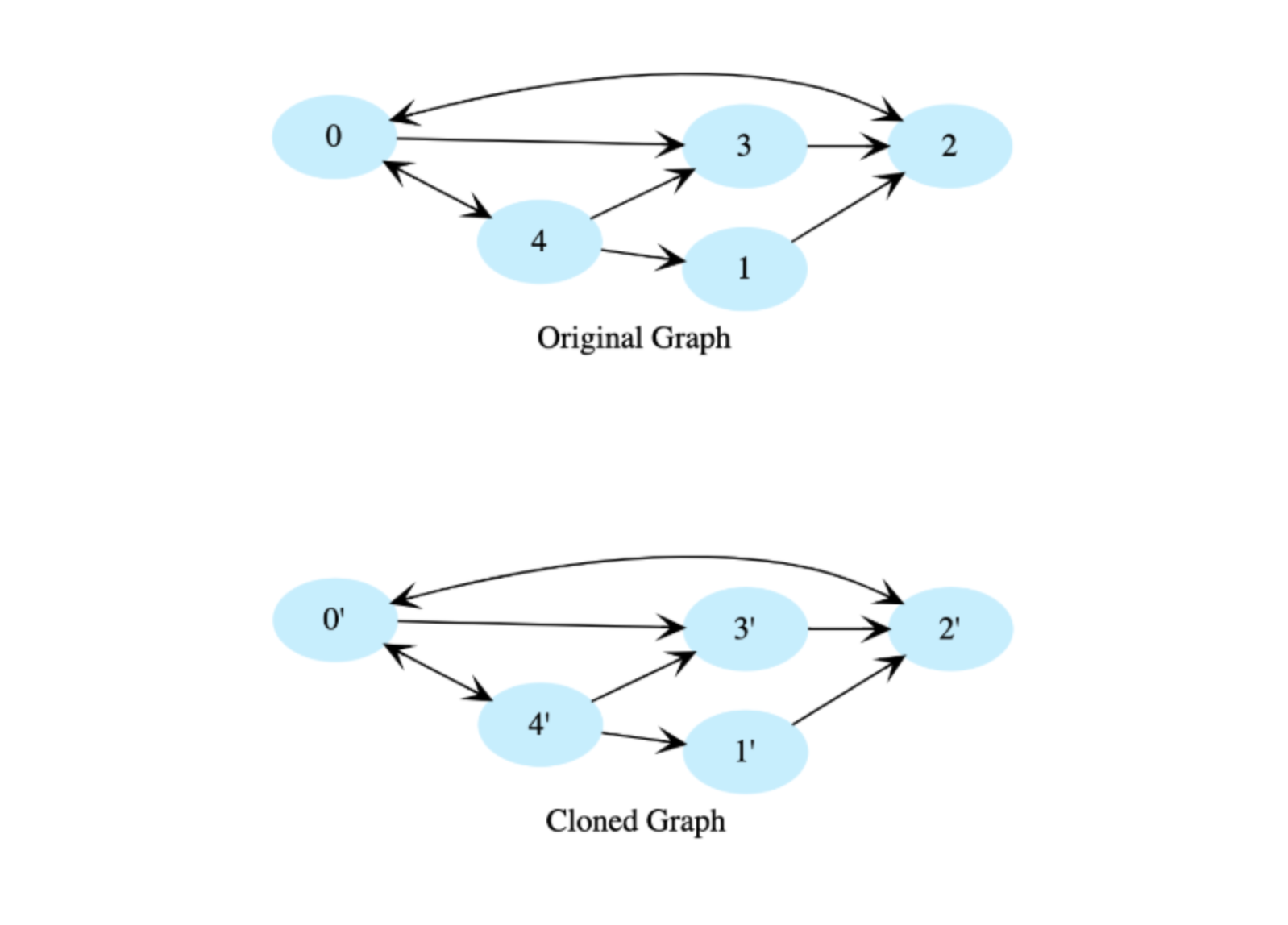
Graphs: Clone a directed graph#
Given the root node of a directed graph, clone this graph by creating its deep copy so that the cloned graph has the same vertices and edges as the original graph.
Let’s look at the below graphs as an example. If the input graph is G = (V, E) where V is set of vertices and E is set of edges, then the output graph (cloned graph) G’ = (V’, E’) such that V = V’ and E = E’.
Note: We are assuming that all vertices are reachable from the root vertex. i.e. we have a connected graph.
Runtime complexity: Linear
Memory Complexity: Logarithmic,
We use depth-first traversal and create a copy of each node while traversing the graph. To avoid getting stuck in cycles, we’ll use a hashtable to store each completed node and will not revisit nodes that exist in the hashtable.
The hashtable key will be a node in the original graph, and its value will be the corresponding node in the cloned graph.
Design: Serialize / deserialize binary tree#
Serialize a binary tree to a file and then deserialize it back to a tree so that the original and the deserialized trees are identical.
- Serialize: write the tree in a file.
- Deserialize: read from a file and reconstruct the tree in memory.
There is no restriction regarding the format of a serialized stream, therefore you can serialize it in any efficient format. However, after deserializing the tree from the stream, it should be exactly like the original tree. Consider the below tree as the input tree.
Binary tree
Runtime complexity: Linear
Memory Complexity: Logarithmic,
There can be multiple approaches to serialize and deserialize the tree. One approach is to perform a depth-first traversal and serialize individual nodes to the stream. We’ll use a pre-order traversal here. We’ll also serialize some markers to represent a null pointer to help deserialize the tree.
Consider the below binary tree as an example. Markers (M*) have been added in this tree to represent null nodes. The number with each marker i.e. 1 in M1, 2 in M2, merely represents the relative position of a marker in the stream.
Deserialize binary tree
The serialized tree (pre-order traversal) from the above example would look like the below list.
Serialize binary tree
When deserializing the tree we’ll again use the pre-order traversal and create a new node for every non-marker node. Encountering a marker indicates that it was a null node.
Sorting and Searching: Find the high and low index#
Given a sorted array of integers, return the low and high index of the given key. You must return -1 if the indexes are not found.
The array length can be in the millions with many duplicates.
In the following example, according to the the key, the low and high indices would be:
key: 1,low= 0 andhigh= 0key: 2,low= 1 andhigh= 1key: 5,low= 2 andhigh= 9key: 20,low= 10 andhigh= 10
For the testing of your code, the input array will be:
1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 6, 6, 6, 6
Runtime complexity: Logarithmic
Memory Complexity: Constant,
Linearly scanning the sorted array for low and high indices are highly inefficient since our array size can be in millions. Instead, we will use a slightly modified binary search to find the low and high indices of a given key.
We need to do binary search twice:
- Once for finding the
lowindex. - Once for finding the
highindex.
Low index#
Let’s look at the algorithm for finding the low index:
- At every step, consider the array between
lowandhighindices and calculate themidindex. - If the element at
midindex is less than thekey,lowbecomesmid + 1(to move towards the start of range). - If the element at mid is greater or equal to the
key, thehighbecomesmid - 1. Index atlowremains the same. - When
lowis greater thanhigh,lowwould be pointing to the first occurrence of thekey. - If the element at
lowdoes not match thekey, return-1.
High index#
Similarly, we can find the high index by slightly modifying the above condition:
- Switch the
lowindex tomid + 1when the element atmidindex is less than or equal to thekey. - Switch the
highindex tomid - 1when the element atmidis greater than thekey.
Sorting and Searching: Search rotated array#
Search for a given number in a sorted array, with unique elements, that has been rotated by some arbitrary number. Return -1 if the number does not exist.
Assume that the array does not contain duplicates
Below is an original array before rotation.
After performing rotation on this array 6 times it changes to:
The task is to find a given number in this array.
Runtime complexity: Logarithmic,
Memory Complexity: Logarithmic,
The solution is essentially a binary search but with some modifications. If we look at the array in the example closely, we notice that at least one half of the array is always sorted. We can use this property to our advantage.
If the number n lies within the sorted half of the array, then our problem is a basic binary search. Otherwise, discard the sorted half and keep examining the unsorted half. Since we are partitioning the array in half at each step, this gives us runtime complexity.
25 more common Facebook coding interview questions#
- Longest increasing subsequence from array of integers (dynamic programming arrays)
- Unique paths in a grid (dynamic programming matrices)
- Add two numbers as a list (lists)
- Design cache (system design)
- Design a highly consistent database (system design)
- Rotate a matrix (arrays)
- Design a URL shortener (system design)
- Design a recommendation system (ML, system design)
- Find nth Fibonacci number (number theory)
- Find the square root of an integer using binary search (math search answer)
- Implement
StrStr(string search) - Minimum appends for Palindrome (strings)
- Find the largest rectangle in a histogram (stacks)
- Substring concatenation (incremental hash)
- Find the least common ancestor (tree search)
- Find largest distance between nodes in a tree (DFS)
- Find all unique triplets in an array, giving sum of zero (array)
- Find maximum path sum in non-empty binary tree (binary tree)
- Find K closest points to origin for a list of points on a plane (search/sort)
- Write a function to compute intersection of arrays (sort/search)
- Design a typehead feature (system design)
- Design Facebook Messenger (system design)
- Group anagrams together in an array of strings (arrays/strings)
- Convert a BST to sorted circular doubly linked list (trees)
- Determine the order of letters in a dictionary (graphs/trees)
How to prepare for a Facebook interview#
Now that you have a sense of what to expect from an interview and know what kinds of questions to expect, let’s learn some preparation strategies based on Facebook’s unique interview process.
Prepare your resume.#
The first thing you should do is update your resume to be metrics/deliverables driven. It’s also a good idea to show how the work you’ve done can translate into their five core values: Move fast, Be bold, Focus on impact, Be open, and Build social value.
Practice generalist coding questions#
I recommend at least three months of self-study to be successful. This includes choosing a programming language, reviewing the basics, and studying algorithms, data structures, system design, object-oriented programming, and more.
It’s important to practice coding using different tools:
- Simple Text Editor (like CoderPad)
- By hand (on a whiteboard or paper)
- Your preferred style of coding
For a robust, 12-week interview guide, check out our article, the 3 Month Coding Interview Preparation Bootcamp
Prepare for the system design interview#
The design interview usually doesn’t involve any coding, so you’ll need to learn how to answer these questions. This will be done on a whiteboard during the interview, so practice your designs by hand. Study up on system design and product design.
The best way to master system design questions is not by memorizing answers but by learning the anatomy of a system design question. You need to train yourself to think from the ground up while also considering scaling and requirements.
Pro tip: If you want to stand out in the system design interview, you’ll need to discuss how Machine Learning can be implemented in your design.
Facebook wants next-gen engineers, and they focus heavily on artificial intelligence. Consider brushing up on ML concepts and ML system design principles.
Master the best practices#
Once you get the basics down and progress through the interview prep roadmap, master the best practices.
When you practice, learn how to articulate your process out loud. Facebook cares a lot about how you think. When you code, explain your thought process as if another person were in the room.
You also want to start timing yourself to learn how to manage your time effectively. It’s always better to take time planning your answer than to just jump it with brute force.
Prepare for behavioral interviews#
Facebook cares that you fit with their company, so you need to be prepared to talk about yourself. For each of Facebook’s values, brainstorm how you fit and why these values matter to you.
You should also think about your 2 to 4 year career aspirations, interests, and strengths as an engineer, as they will likely come up in the interview.
To learn how to prepare, check out my article Behavioral Interviews: how to prepare and ace interview questions
Prepare questions for your interviewers#
Facebook values self-starters, so it’s important that you come prepared with questions for your interviewers. You’ll have time during every interview to ask your own questions. This is also an opportunity to determine if Facebook is a good fit for your lifestyle and needs.
Facebook Software Engineer Interview#
Getting hired at Facebook is a dream come true for most software engineers. But it’s a hard nut to crack. The Facebook software-engineer interview process is a 5-6 step procedure that includes multiple technical and behavioral interviews.
If you’re preparing for Facebook software engineer interviews, you must have an in-depth knowledge of data structures, algorithms, network and APIs, and system design. Questions mentioned above — such as those involving backtracking, arrays, and dynamic programming — commonly appear in Facebook software engineer interviews. To excel, candidates should consistently practice coding problems, refine their understanding of core computer science principles, and engage in mock interviews simulating the Facebook environment.
Along with testing technical acumen, the interviews also assess cultural fit, problem-solving abilities, and communication skills. While technical proficiency is vital, Facebook equally values a candidate’s cultural fit, problem-solving prowess, and communication aptitude. Proper preparation, including practicing coding problems and understanding the company’s core values, is paramount to success. It is crucial to prepare properly, including practicing coding problems and understanding the company’s core values.
Wrap up and resource list#
Cracking the Facebook coding interview comes down to the time you spend preparing, such as practicing coding questions, studying behavioral interviews, and understanding Facebook’s company culture.
There is no golden ticket, but more preparation will surely make you a more confident and desirable candidate. The essential resources below will help you prepare and build confidence for Facebook interviews.
Keep learning and studying!
Learn the patterns behind common interview questions#
- Grokking Coding Interview Patterns in Python
- Grokking Coding Interview Patterns in JavaScript
- Grokking Coding Interview Patterns in Java
- Grokking Coding Interview Patterns in Go
- Grokking Coding Interview Patterns in C++
Continue reading about coding interviews#
Frequently Asked Questions
How hard are Facebook coding interviews?
How hard are Facebook coding interviews?
Written By:
Amanda Fawcett
Related Courses
Grokking the Coding Interview Patterns in C#Grokking the Coding Interview Patterns in JavaScriptGrokking the Coding Interview Patterns in C++Grokking the Coding Interview PatternsGrokking the Coding Interview Patterns in GoGrokking the Coding Interview Patterns in PythonAlgorithms for Coding Interviews in C++Binary Search for Coding InterviewsCoderust: Hacking the Coding InterviewRecursion for Coding Interviews in PythonRecursion for Coding Interviews in JavaRecursion for Coding Interviews in C++JavaScript Design Patterns for Coding InterviewsStep Up Your JS: A Comprehensive Guide to Intermediate JavaScriptCompetitive Programming - Crack Your Coding Interview, C++
