AI-powered learning
Save this course
Fine-Tuning LLMs Using LoRA and QLoRA
Gain insights into fine-tuning LLMs with LoRA and QLoRA. Explore parameter-efficient methods, LLM quantization, and hands-on exercises to adapt AI models with minimal resources efficiently.
4.6
13 Lessons
2h
Updated 3 months ago
Join 3 million developers at
Join 3 million developers at
LEARNING OBJECTIVES
- A solid foundation in fine-tuning LLMs, including practical techniques for Llama 3 fine-tuning and broader LLM fine-tuning workflows
- Familiarity with LLM quantization methods, such as int8 quantization and bits and bytes quantization, for reducing model size and improving deployment efficiency
- Hands-on experience implementing quantization techniques and optimizing models for performance and efficiency
- An understanding of Low-Rank Adaptation (LoRA) and Quantized Low-Rank Adaptation (QLoRA) as key approaches for parameter-efficient fine-tuning (PEFT)
- Hands-on experience fine-tuning Llama 3 model with custom datasets, using PEFT fine-tuning techniques for real-world applications
Learning Roadmap
2.
Basics of Fine-Tuning
Basics of Fine-Tuning
Look at fine-tuning LLMs, types of fine-tuning, quantization, and hands-on quantization steps.
3.
Exploring LoRA
Exploring LoRA
5 Lessons
5 Lessons
Go hands-on with parameter-efficient fine-tuning techniques like LoRA and QLoRA for LLMs.
4.
Wrap Up
Wrap Up
2 Lessons
2 Lessons
Engage in resource-efficient fine-tuning methods and optimize LLMs for diverse applications.
Certificate of Completion
Showcase your accomplishment by sharing your certificate of completion.
Complete more lessons to unlock your certificate
Developed by MAANG Engineers
ABOUT THIS COURSE
This hands-on course will teach you the art of fine-tuning large language models (LLMs). You will also learn advanced techniques like Low-Rank Adaptation (LoRA) and Quantized Low-Rank Adaptation (QLoRA) to customize models such as Llama 3 for specific tasks. The course begins with fundamentals, exploring fine-tuning, the types of fine-tuning, comparison with pretraining, discussion on retrieval-augmented generation (RAG) vs. fine-tuning, and the importance of quantization for reducing model size while maintaining performance.
Gain practical experience through hands-on exercises using quantization methods like int8 and bits and bytes. Delve into parameter-efficient fine-tuning (PEFT) techniques, focusing on implementing LoRA and QLoRA, which enable efficient fine-tuning using limited computational resources.
After completing this course, you’ll master LLM fine-tuning, PEFT fine-tuning, and advanced quantization parameters, equipping you with the expertise to adapt and optimize LLMs for various applications.
Trusted by 3 million developers working at companies
P
Prathyush Babu
Senior Software Engineer @ PrivateCircle
A
Anthony Walker
@_webarchitect_
E
Evan Dunbar
ML Engineer
Built for 10x Developers
No Passive Learning
Learn by building with project-based lessons and in-browser code editor
Personalized Roadmaps
The platform adapts to your strengths & skills gaps as you go
Future-proof Your Career
Get hands-on with in-demand skills
AI Code Mentor
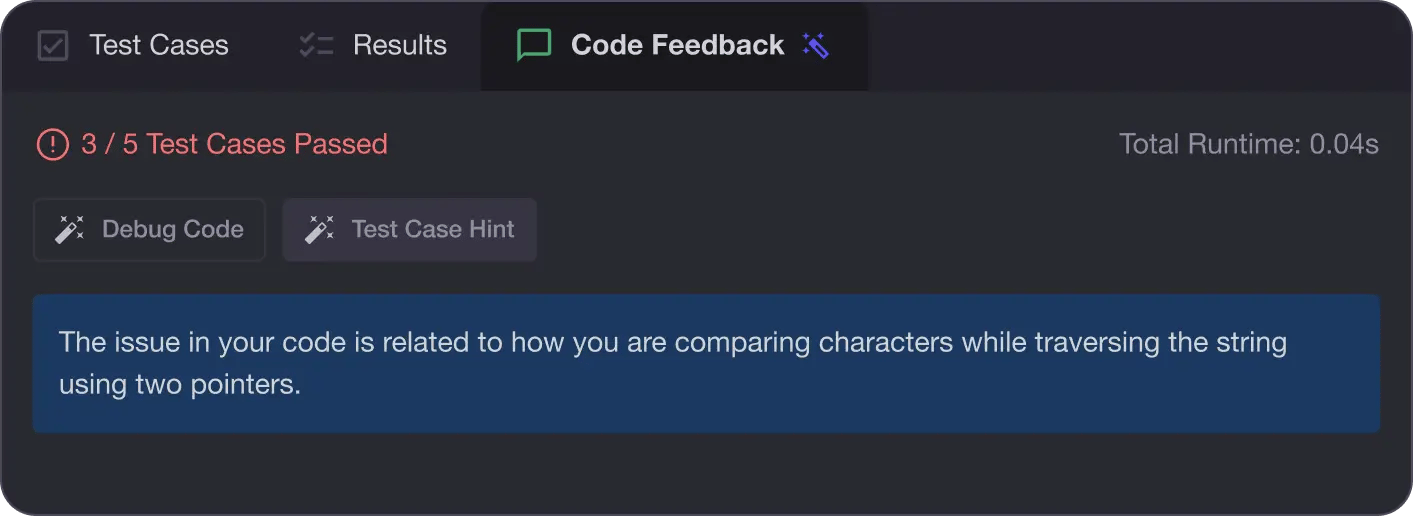
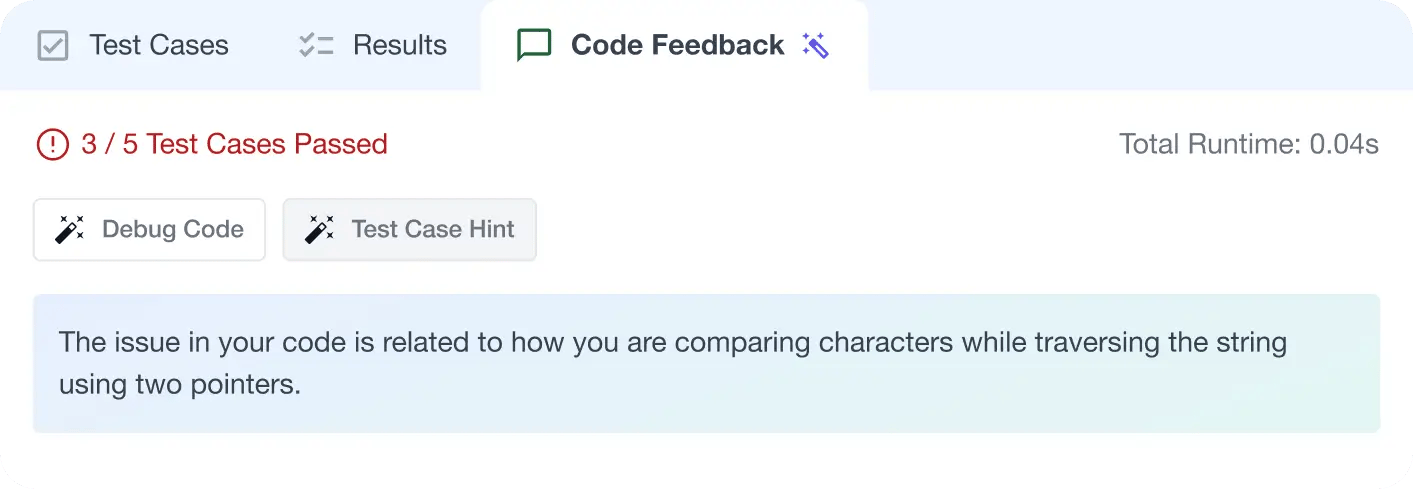
Write better code with AI feedback, smart debugging, and "Ask AI"
MAANG+ Interview Prep
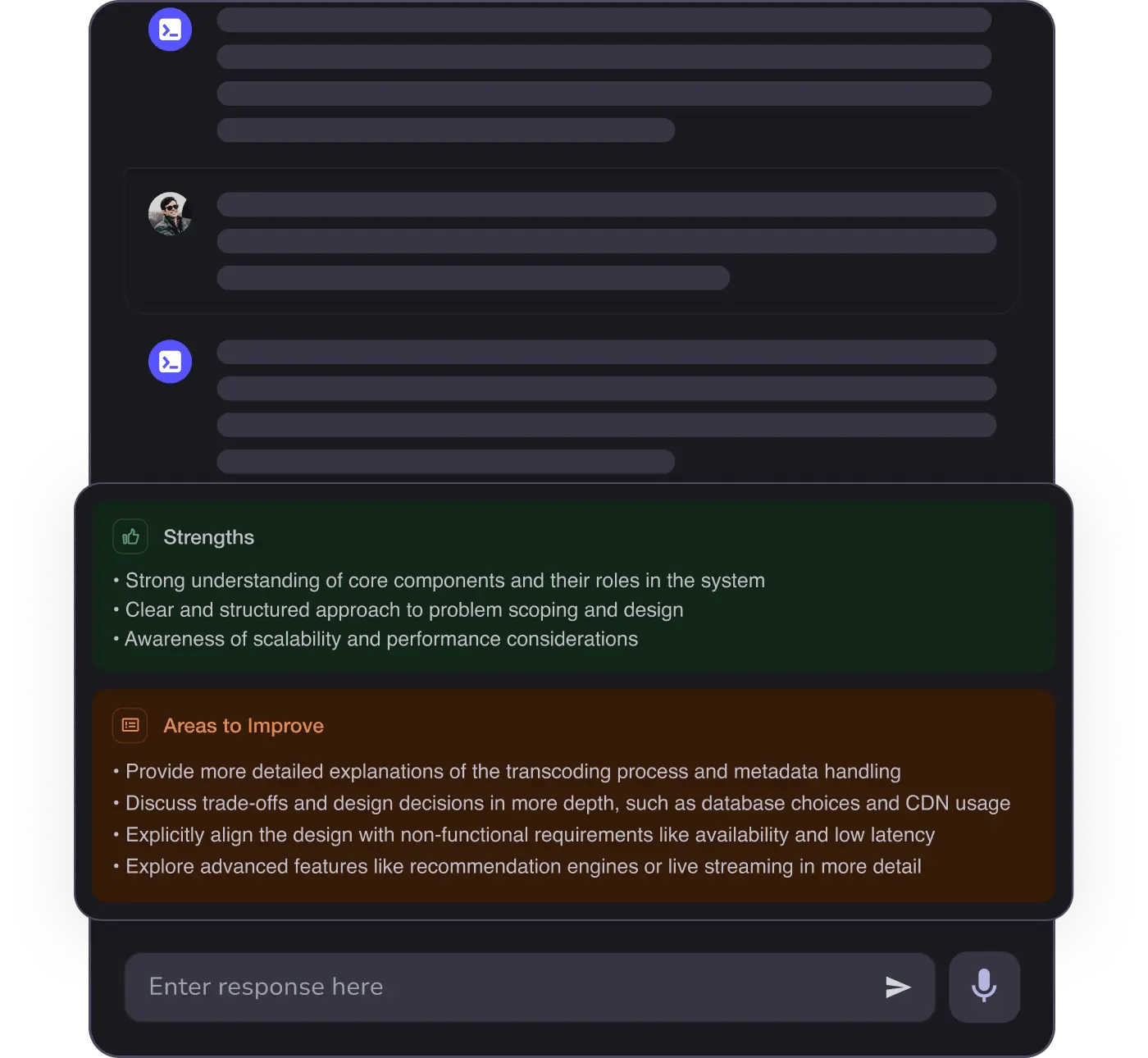
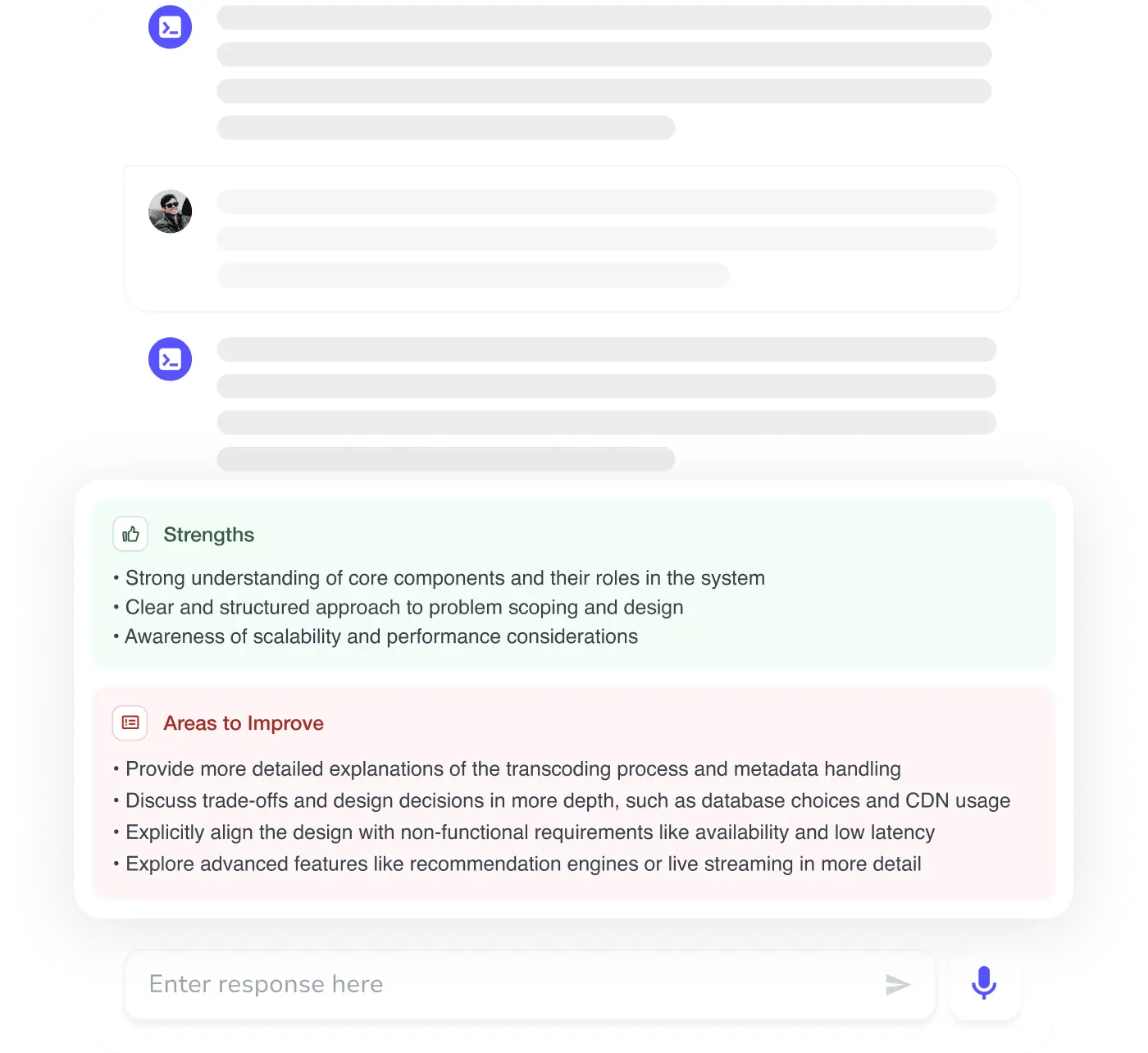
AI Mock Interviews simulate every technical loop at top companies
Free Resources
