Learn how to use Databricks, PySpark, and Delta Lake to build modern data pipelines. Go from basic setup to creating and analyzing scalable data workflows using the Lakehouse architecture.
4.6
16 Lessons
2h
Updated 2 months ago
Join 3 million developers at
Join 3 million developers at
LEARNING OBJECTIVES
- Understand the Lakehouse architecture and how it improves upon traditional data lakes and warehouses.
- Navigate and use Databricks notebooks to run Python and SQL workflows.
- Create, inspect, and transform data using PySpark DataFrames.
- Work with Delta Lake to write, read, and manage reliable data tables with versioning.
- Build an end-to-end data pipeline from raw data ingestion to final analysis using SQL and PySpark.
Learning Roadmap
1.
Introduction to Databricks and Lakehouse
Introduction to Databricks and Lakehouse
Understand why Databricks is used and explore the Lakehouse architecture for unified data analytics.
2.
Setting Up Databricks
Setting Up Databricks
Learn how to sign up, explore the interface, and create your first notebook.
3.
PySpark Basics in Databricks
PySpark Basics in Databricks
4 Lessons
4 Lessons
Explore DataFrame creation, inspection, transformation, and reading CSVs using PySpark.
4.
Delta Lake Fundamentals
Delta Lake Fundamentals
3 Lessons
3 Lessons
Understand Delta Lake, how to read/write Delta tables, and use time travel features.
5.
SQL in Databricks
SQL in Databricks
2 Lessons
2 Lessons
Explore querying and managing Delta tables using SQL.
7.
Wrap Up and Next Steps
Wrap Up and Next Steps
2 Lessons
2 Lessons
Summarize real-world Databricks applications and key takeaways from the course.
Certificate of Completion
Showcase your accomplishment by sharing your certificate of completion.
Complete more lessons to unlock your certificate
Developed by MAANG Engineers
ABOUT THIS COURSE
This course provides a hands-on introduction to modern data engineering using Databricks and the Lakehouse architecture. You’ll start by understanding the limitations of traditional data systems and how Databricks, powered by Apache Spark and Delta Lake, solves these challenges.
As the course progresses, you’ll set up your Databricks environment, learn how to work with notebooks, and build a strong foundation in PySpark DataFrames. You’ll then explore how to read, transform, and analyze data at scale.
A major focus of the course is the Delta Lake, where you’ll learn how to store data reliably using ACID transactions, perform time travel, and work with managed tables. You’ll also use SQL within Databricks to query and analyze data efficiently.
By the end of the course, you’ll complete an end-to-end Lakehouse project, building a real-world data pipeline from raw data ingestion to final analysis. This course prepares you with practical skills used by data engineers and analysts in modern data platforms.
Trusted by 3 million developers working at companies
A
Anthony Walker
@_webarchitect_
E
Evan Dunbar
ML Engineer
S
Software Developer
Carlos Matias La Borde
S
Souvik Kundu
Front-end Developer
V
Vinay Krishnaiah
Software Developer
Built for 10x Developers
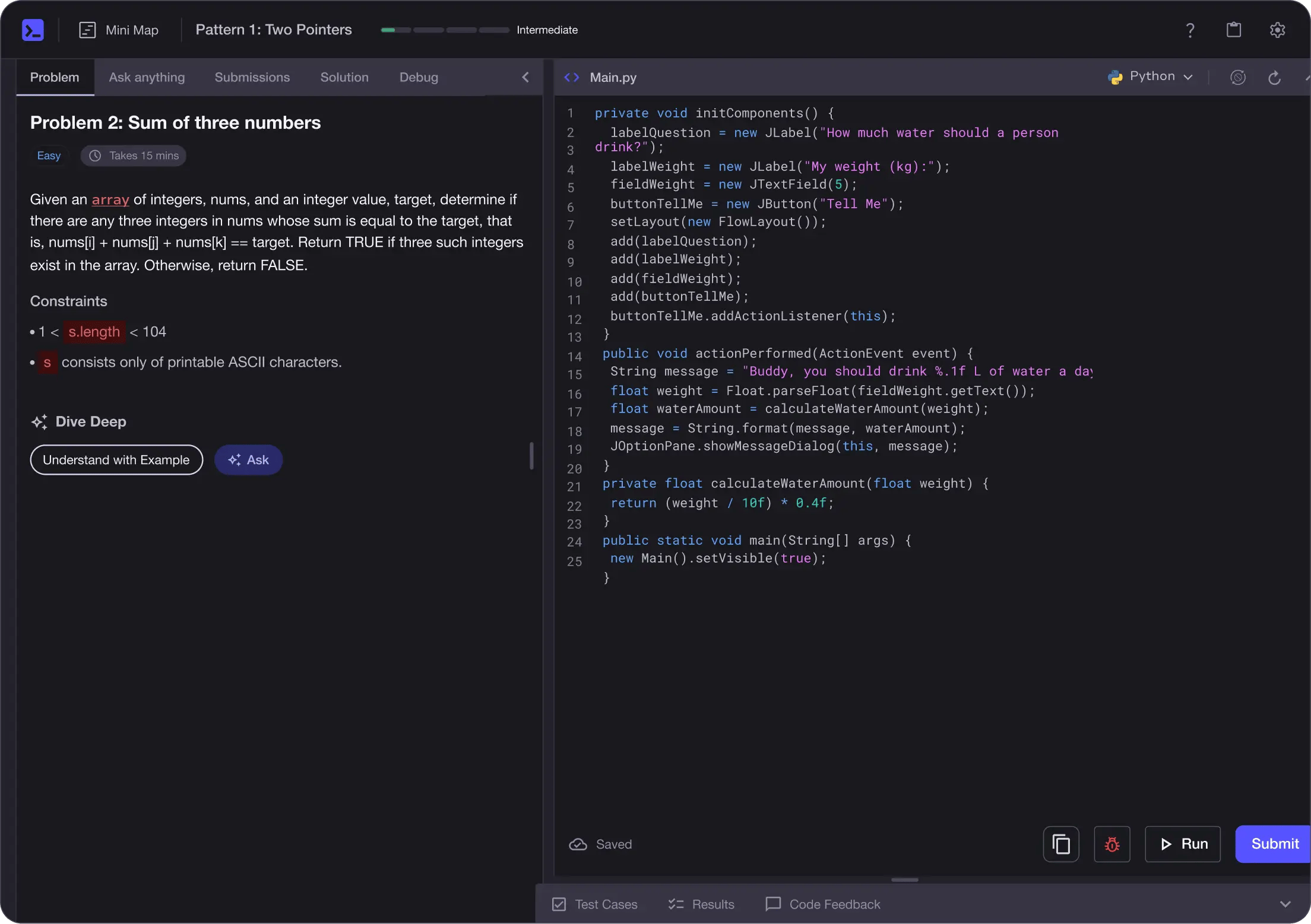
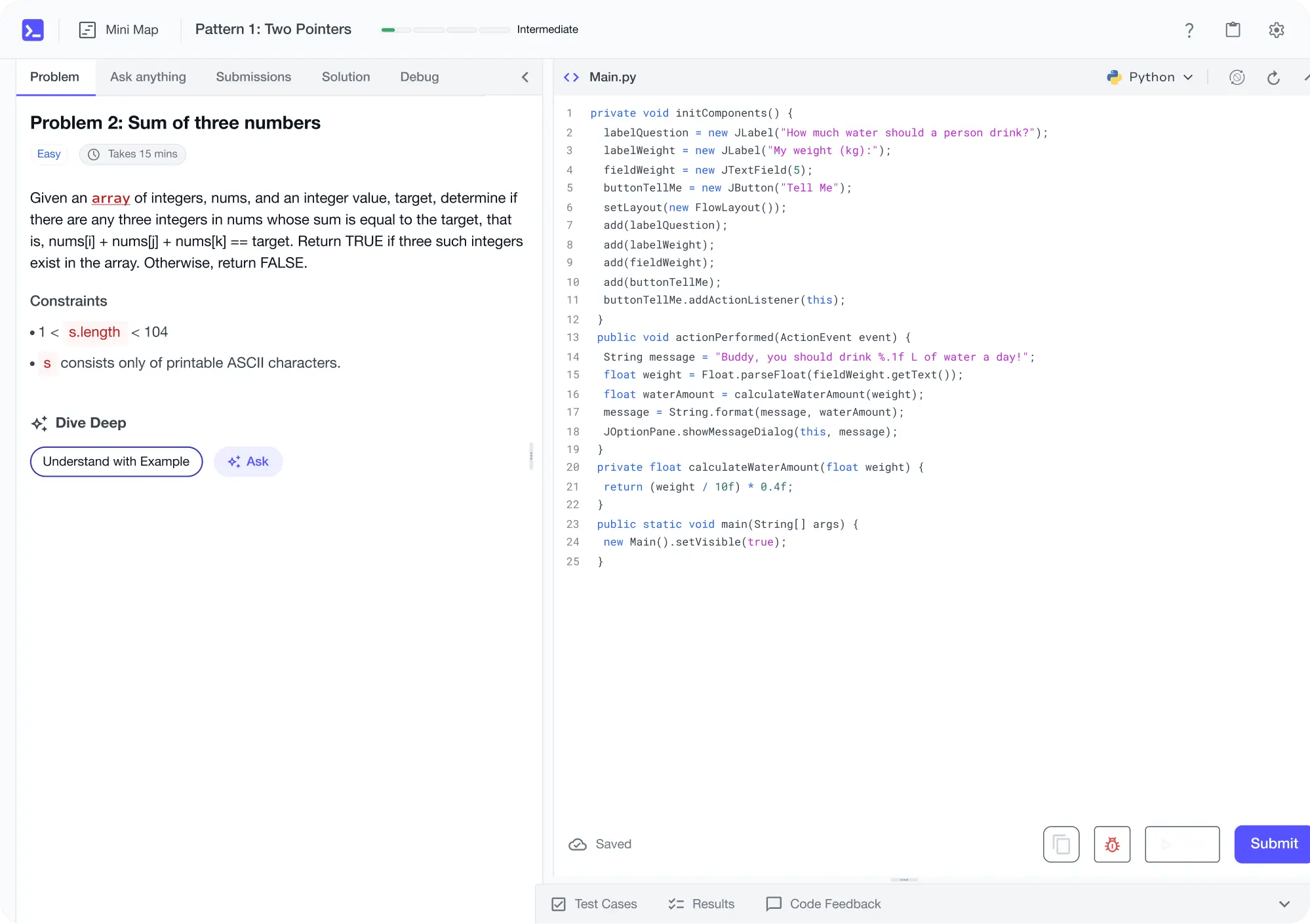
No Passive Learning
Learn by building with project-based lessons and in-browser code editor
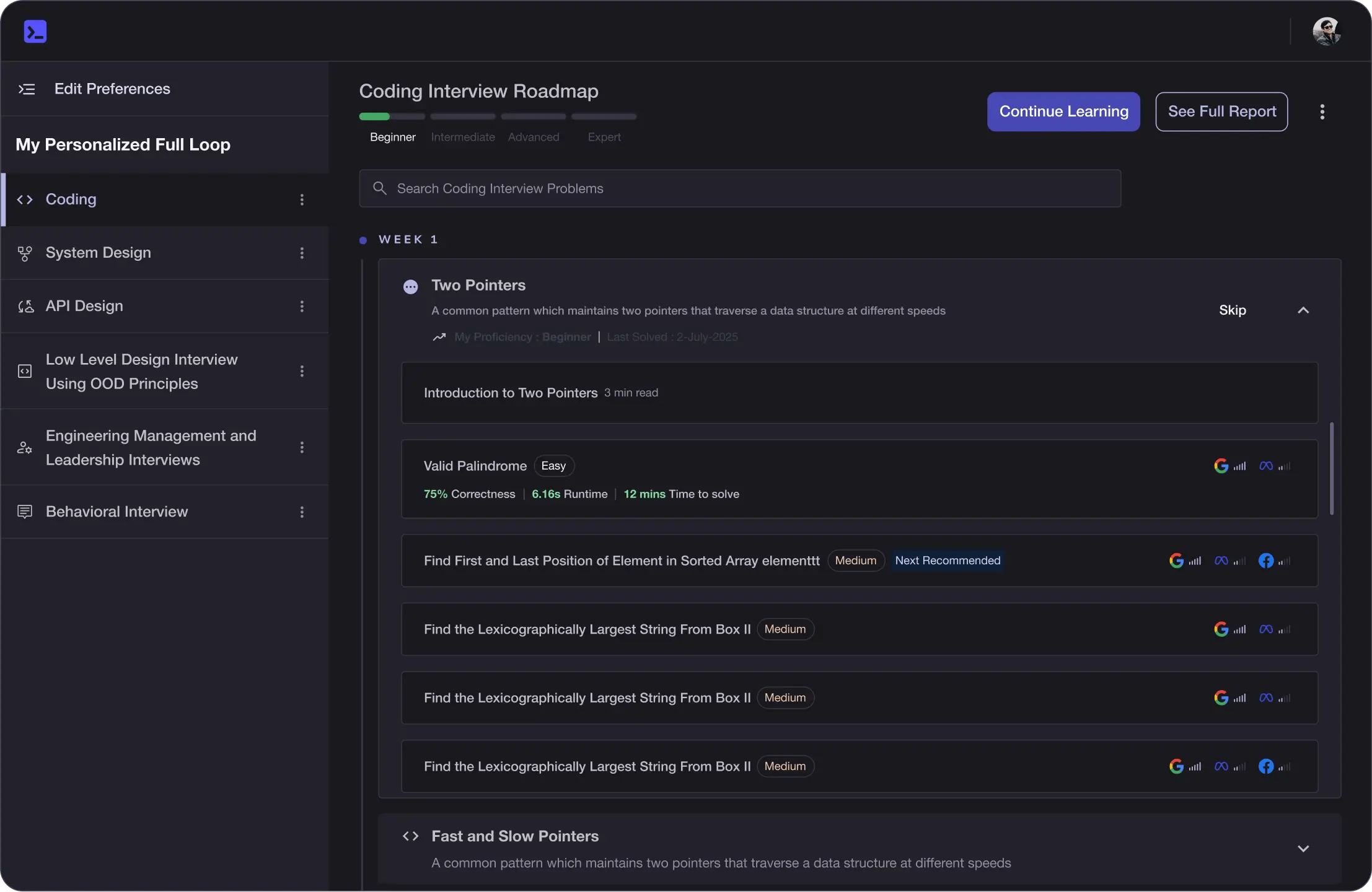
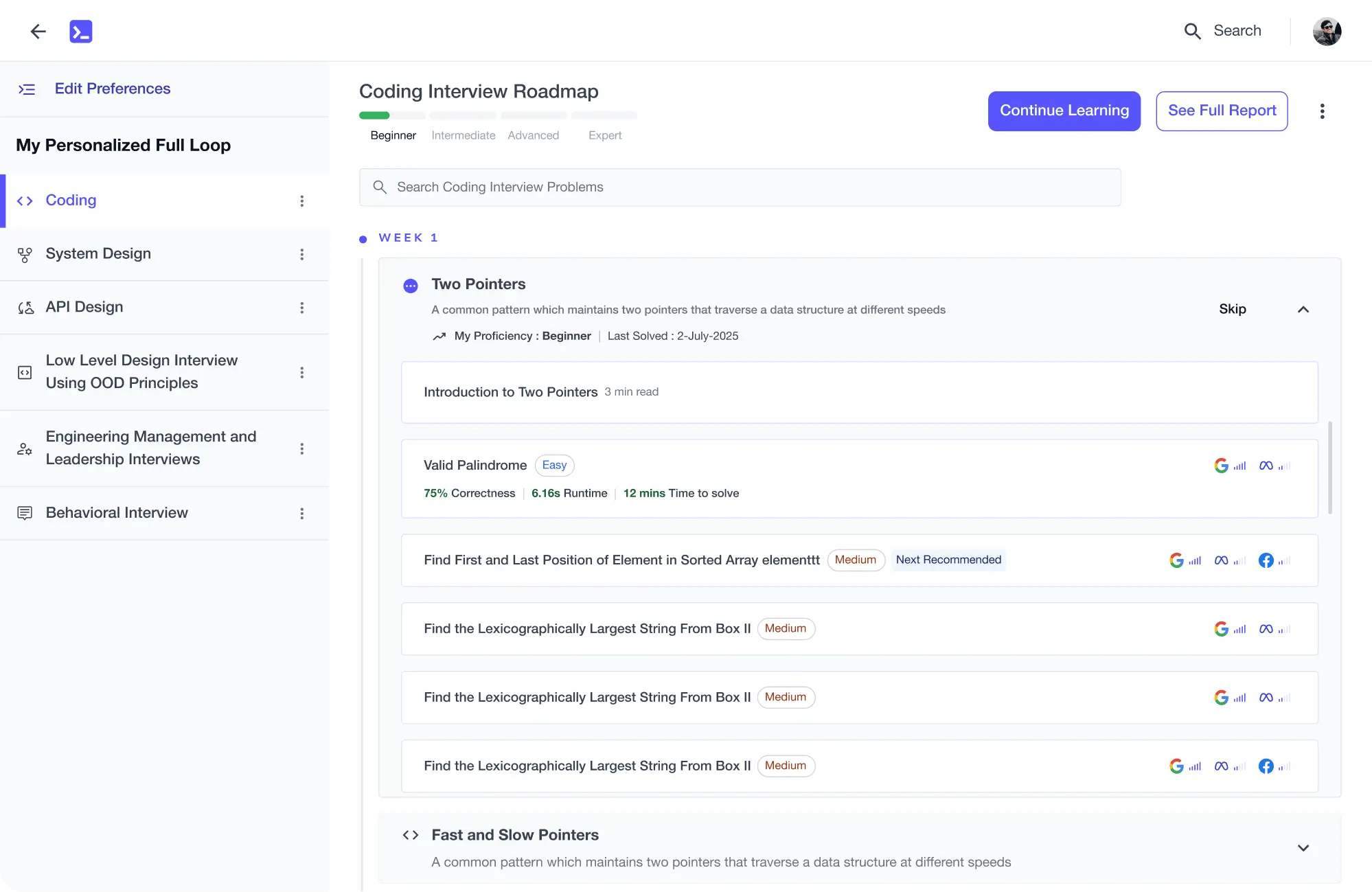
Personalized Roadmaps
The platform adapts to your strengths & skills gaps as you go
Future-proof Your Career
Get hands-on with in-demand skills
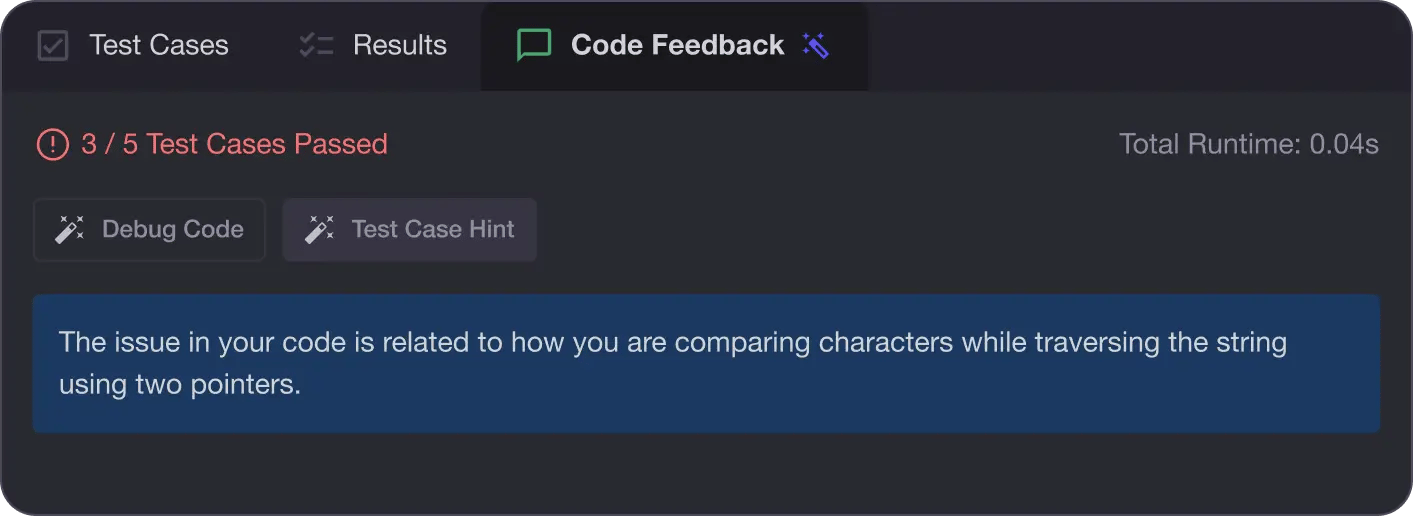
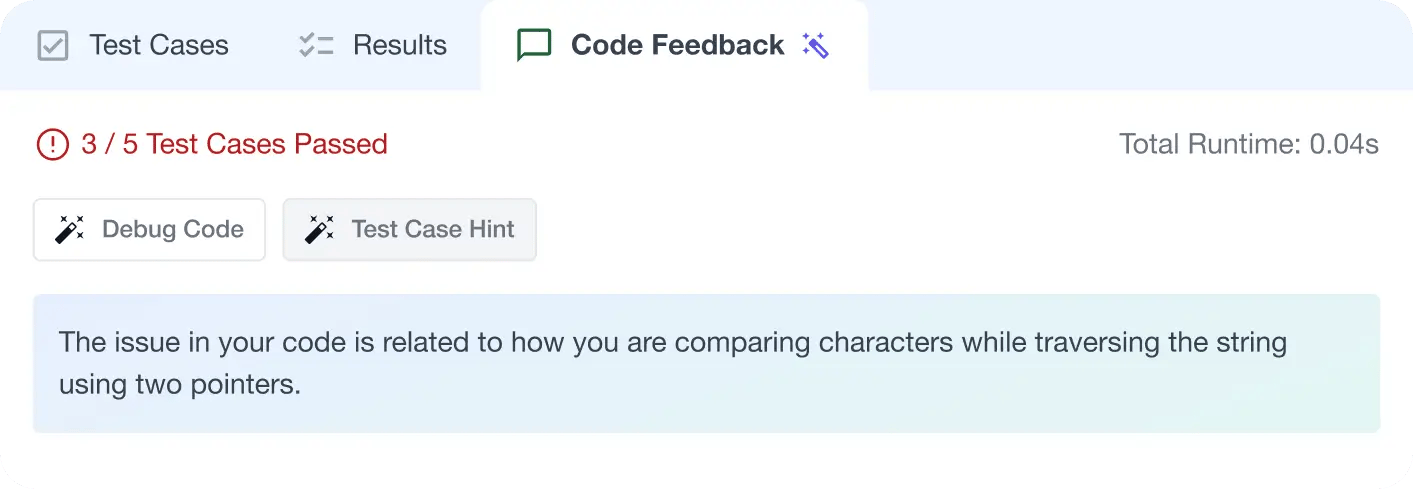
AI Code Mentor
Write better code with AI feedback, smart debugging, and "Ask AI"
MAANG+ Interview Prep
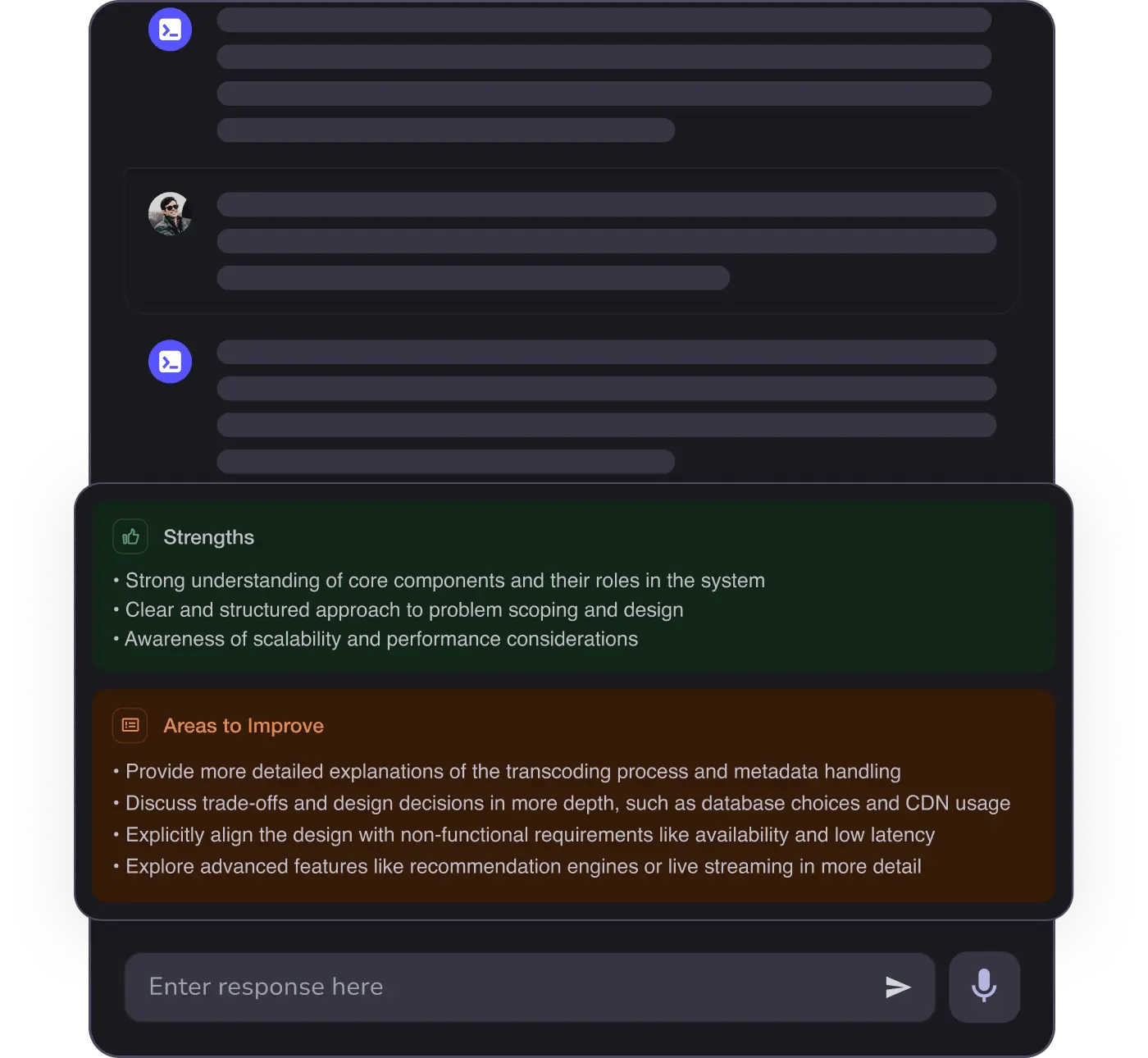
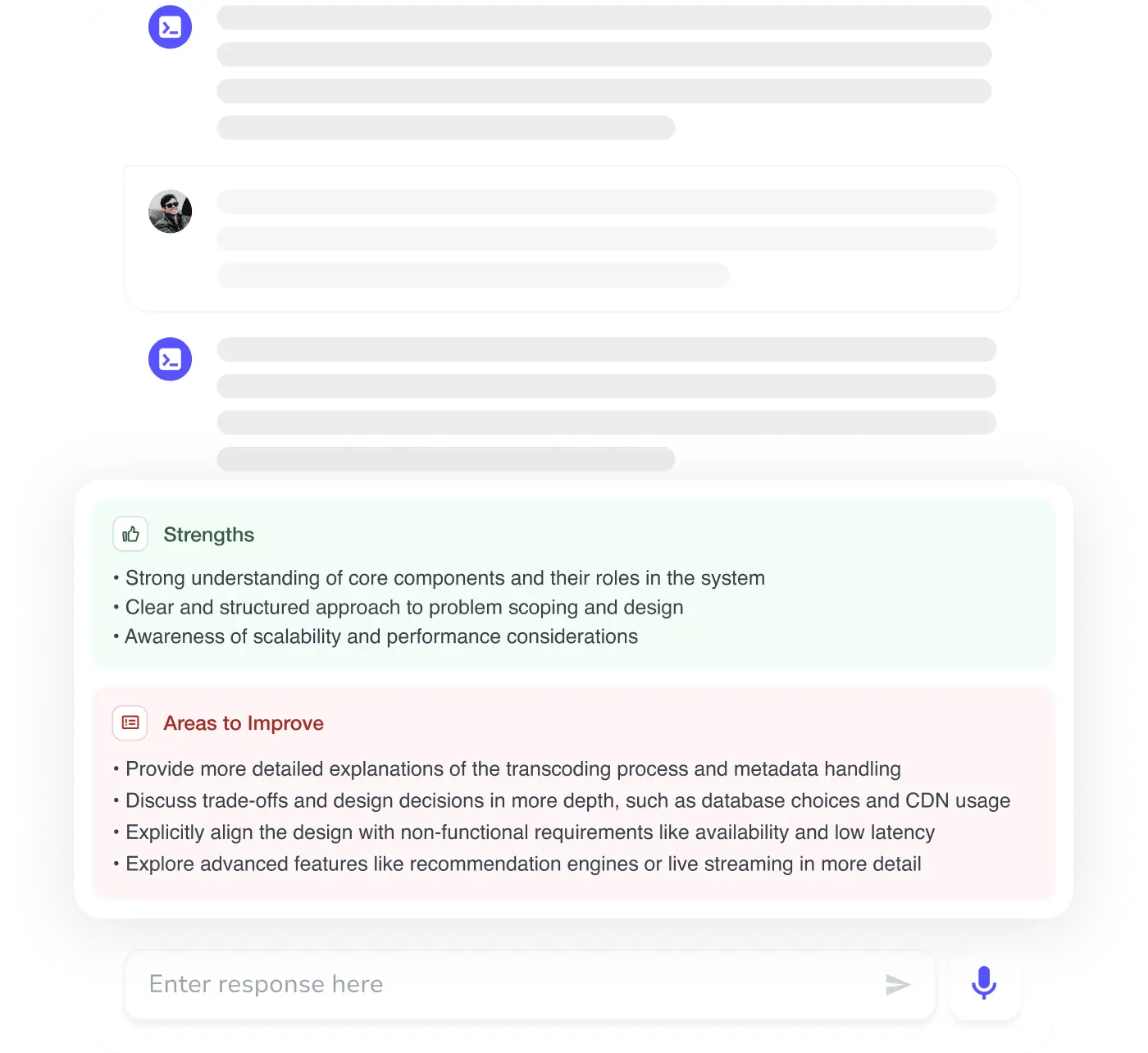
AI Mock Interviews simulate every technical loop at top companies
Free Resources
