AI-powered learning
Save this course
Machine Learning System Design
Gain insights into ML system design, state-of-the-art techniques, and best practices for scalable production. Learn from top researchers and stand out in your next ML interview.
4.5
21 Lessons
2h
Updated 4 months ago
Join 3 million developers at
Join 3 million developers at
LEARNING OBJECTIVES
- Design end-to-end ML systems for production environments: feature engineering, training pipelines, inference, and metrics evaluation
- Build a video recommendation system with candidate generation and ranking models
- Optimize feed ranking with personalized models for user engagement
- Design ad click prediction models and recommender system architectures
- Architect Airbnb-style rental search ranking with booking prediction models
- Estimate food delivery times using scalable ML system design principles
Why choose this course?
Start Designing ML Systems at Scale
As machine learning permeates every industry, System Design is a the secret to building scalable AI applications.
Practice with 5 Real-world Case Studies
Master the fundamentals of modern ML System Design from the ground up. Hone your skills through real-world deep-dives, including video recommendation, ad click prediction, and food delivery time estimation.
Playbook Developed by MAANG Engineers
This course delivers the insider expertise from pros who've built scalable systems at Meta, Google, and Microsoft. Test your learning with skill assessments, and AI Mock Interviews for instant, personalized feedback.
Learning Roadmap
1.
Machine Learning Primer
Machine Learning Primer
Get familiar with core machine learning principles, from feature engineering to model deployment.
2.
Video Recommendation
Video Recommendation
Discover the logic behind developing and optimizing scalable video recommendation systems for enhanced user engagement.
3.
Feed Ranking
Feed Ranking
3 Lessons
3 Lessons
Work your way through optimizing feed ranking with personalized models for enhanced user engagement.
4.
Ad Click Prediction
Ad Click Prediction
3 Lessons
3 Lessons
Enhance your skills in designing and optimizing ad click prediction models for better ad performance.
5.
Rental Search Ranking
Rental Search Ranking
3 Lessons
3 Lessons
Take a closer look at designing Airbnb's rental search ranking system with a booking prediction model and performance metrics.
6.
Estimate Food Delivery Time
Estimate Food Delivery Time
3 Lessons
3 Lessons
See how it works to design an accurate, scalable food delivery time estimation system.
Certificate of Completion
Showcase your accomplishment by sharing your certificate of completion.
Complete more lessons to unlock your certificate
Developed by MAANG Engineers
ABOUT THIS COURSE
ML System Design interviews reward candidates who can walk through the full lifecycle of a production ML system, from problem framing and feature engineering through training, inference, and metrics evaluation. This course covers that lifecycle through five real-world systems that reflect the kinds of problems asked at companies like Meta, Snapchat, LinkedIn, and Airbnb.
You'll start with a primer on core ML system design concepts: feature selection and engineering, training pipelines, inference architecture, and how to evaluate models with the right metrics. Then you'll apply those concepts to increasingly complex systems, including video recommendation, feed ranking, ad click prediction, rental search ranking, and food delivery time estimation. Each system follows a consistent structure: define the problem, choose metrics, design the architecture, and discuss tradeoffs.
The course draws directly from hundreds of recent research and industry papers, so the techniques you'll learn reflect how ML systems are actually built at scale today. It is designed to be dense and efficient, ideal if you have an ML System Design interview approaching and want to go deep on production-level thinking quickly. Learners from this course have gone on to receive offers from companies including Snapchat, Meta, Coupang, StitchFix, and LinkedIn.
ABOUT THE AUTHOR

Khang Pham
I built many online Machine Learning systems that serve 100k RPS. I have 6 years of experience as Machine Learning Engineer. I had offers from Google, Snapchat, Coupang etc. I'm owner of the popular ML interview repo at http://mlengineer.io/
Trusted by 3 million developers working at companies
A
Anthony Walker
@_webarchitect_
E
Evan Dunbar
ML Engineer
S
Software Developer
Carlos Matias La Borde
S
Souvik Kundu
Front-end Developer
V
Vinay Krishnaiah
Software Developer
Built for 10x Developers
No Passive Learning
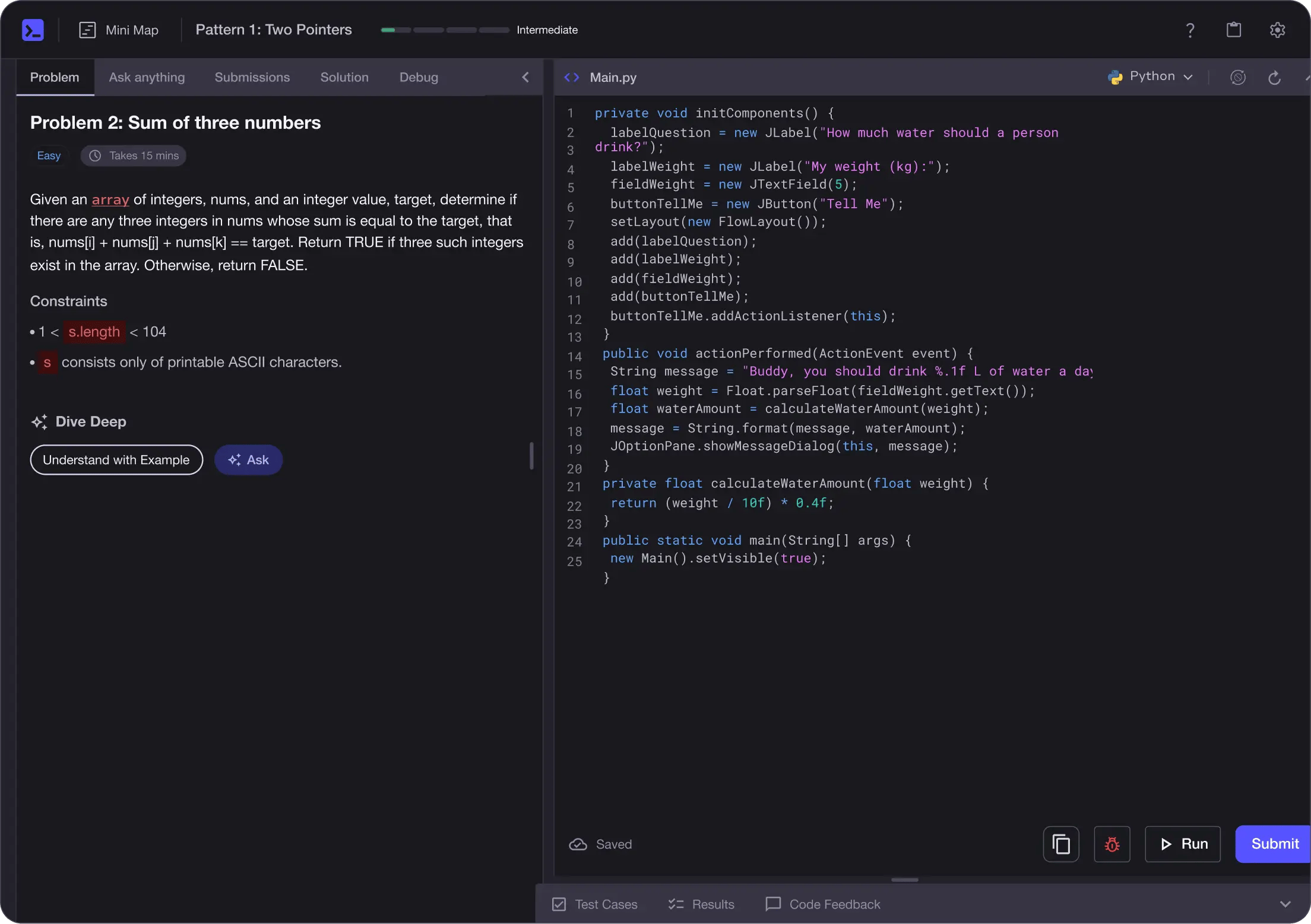
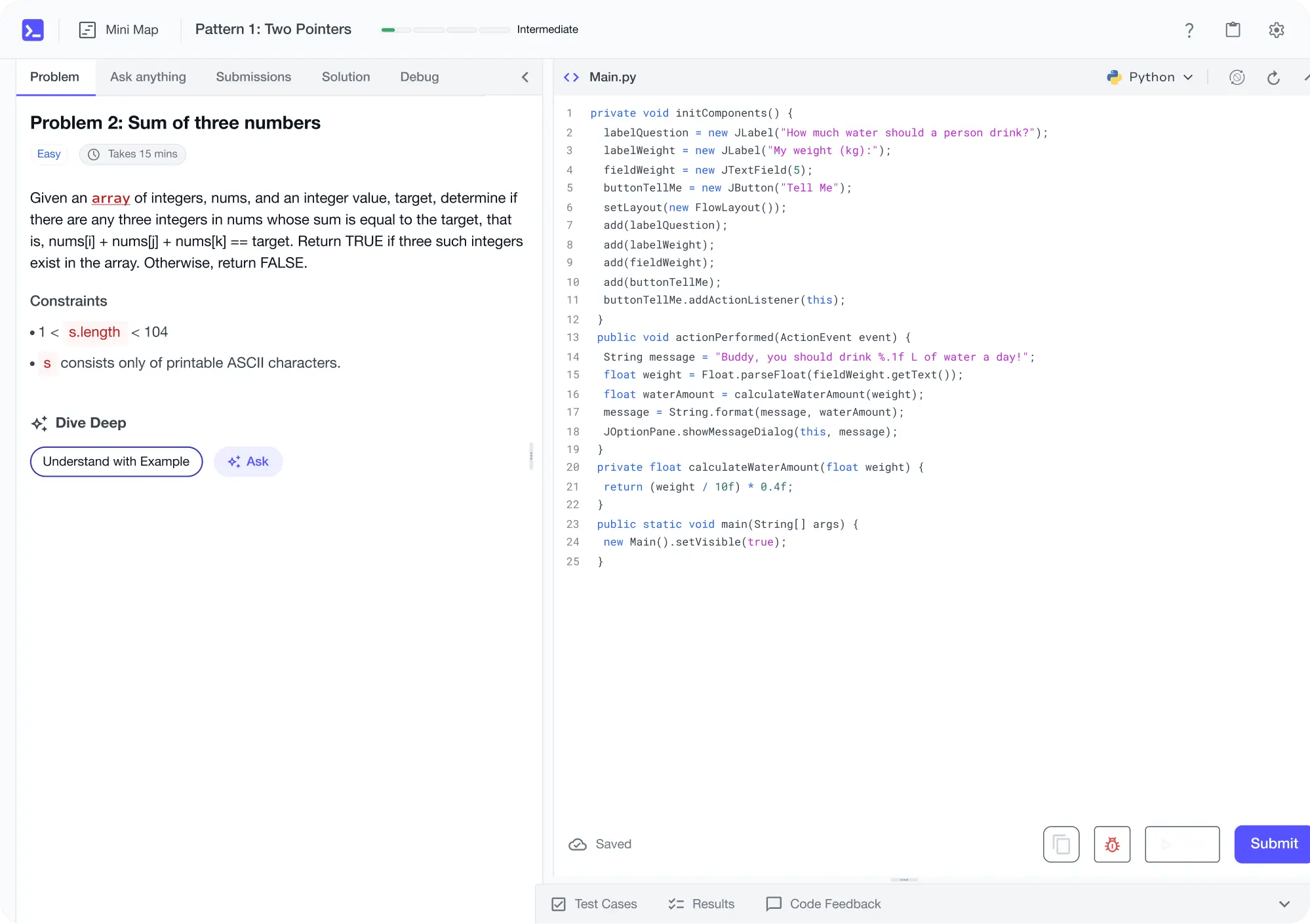
Learn by building with project-based lessons and in-browser code editor
Personalized Roadmaps
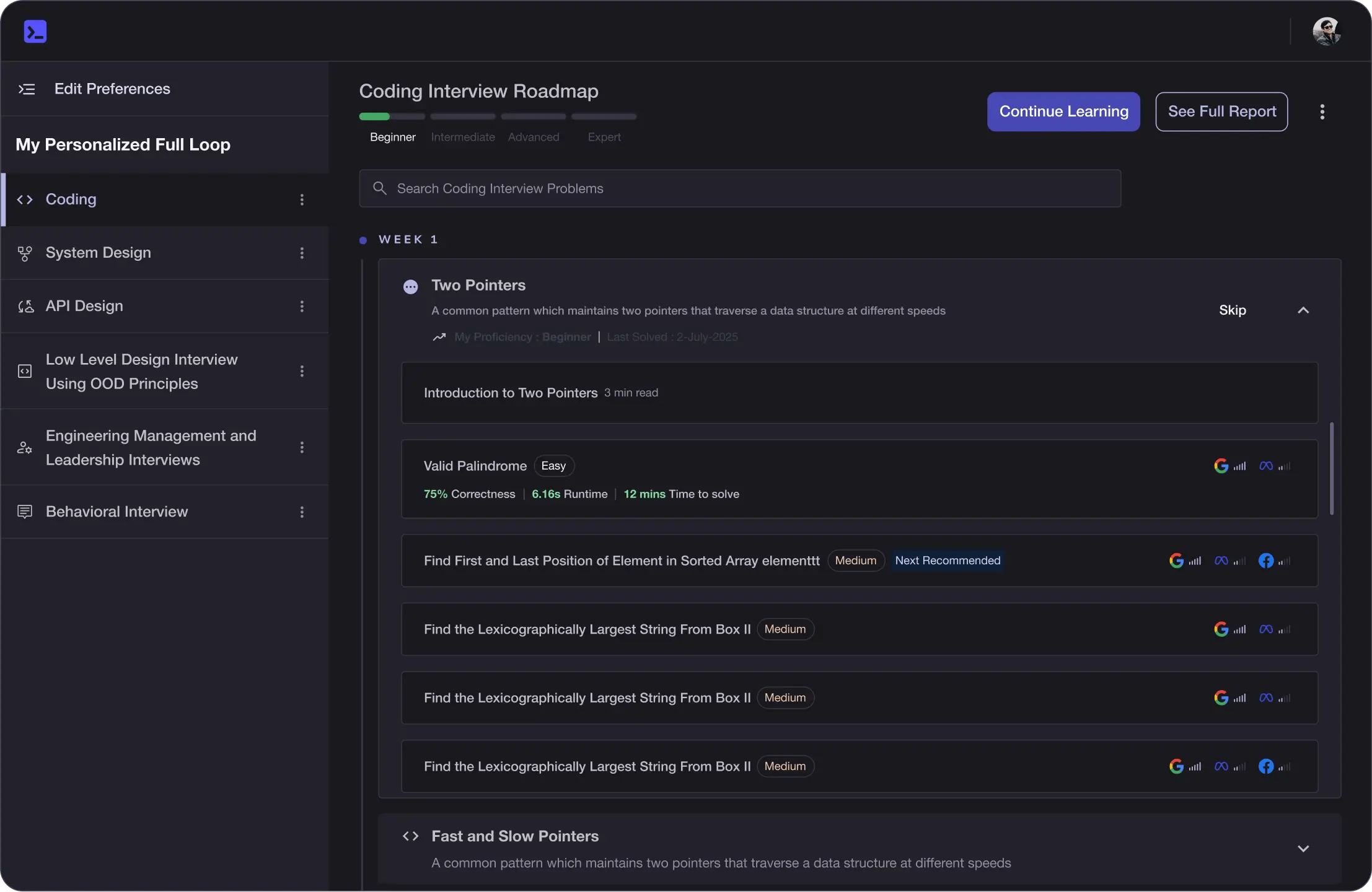
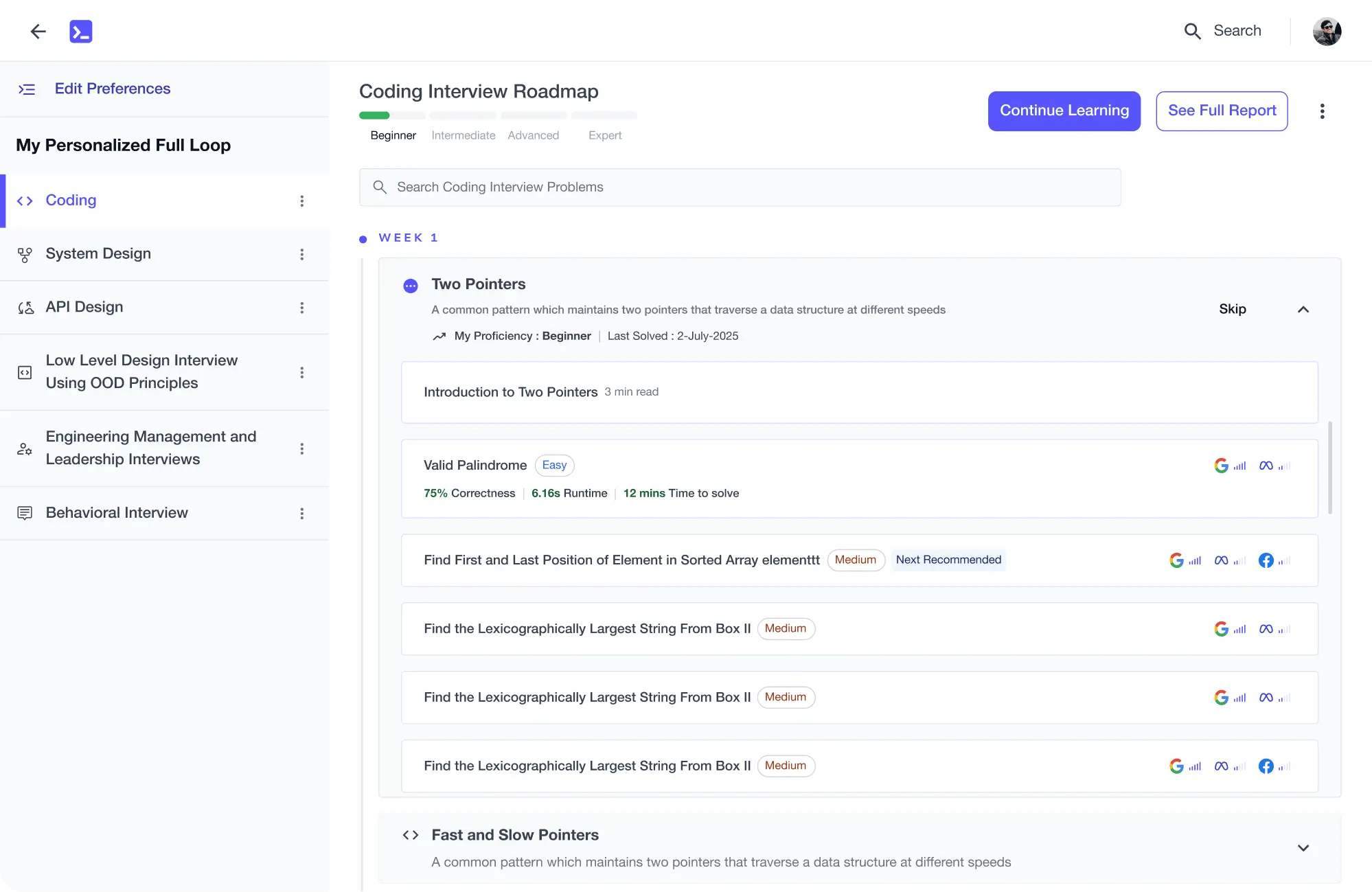
The platform adapts to your strengths & skills gaps as you go
Future-proof Your Career
Get hands-on with in-demand skills
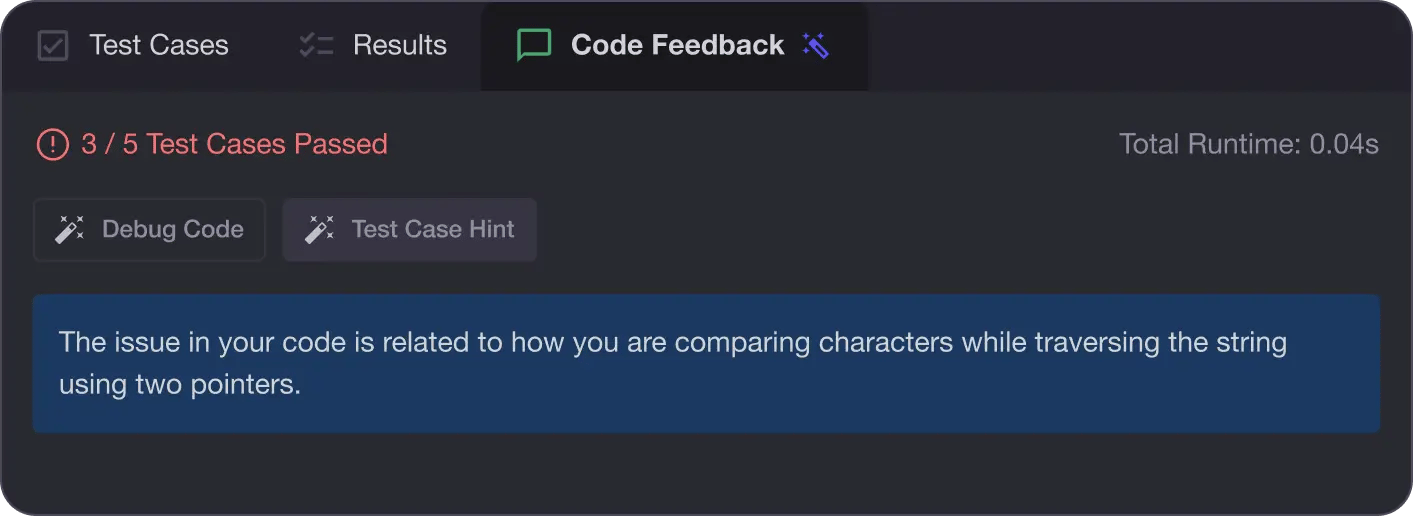
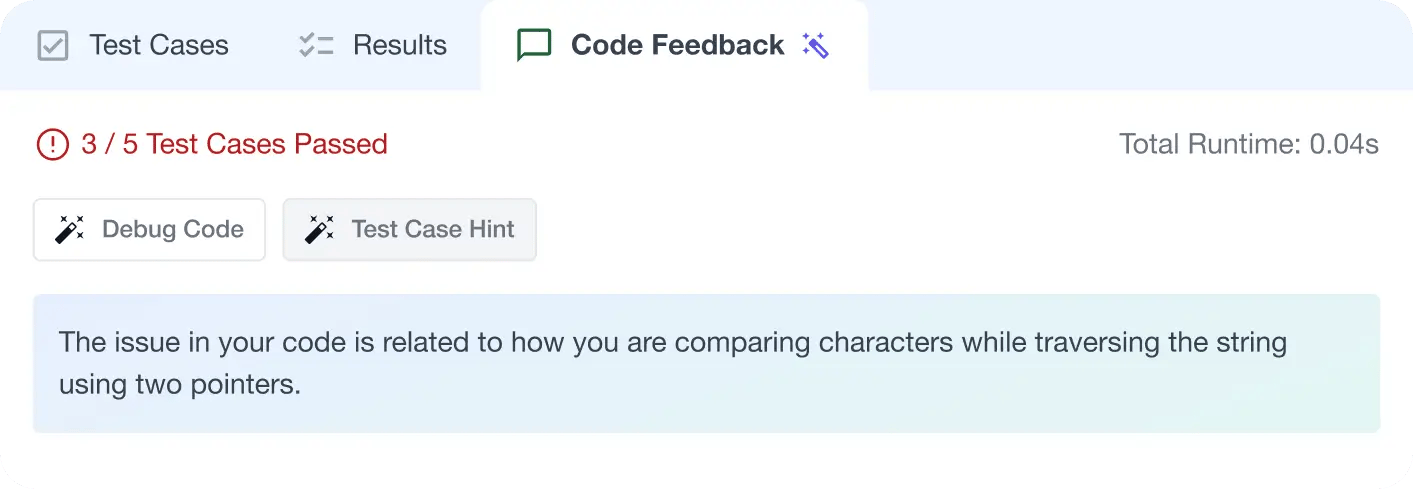
AI Code Mentor
Write better code with AI feedback, smart debugging, and "Ask AI"
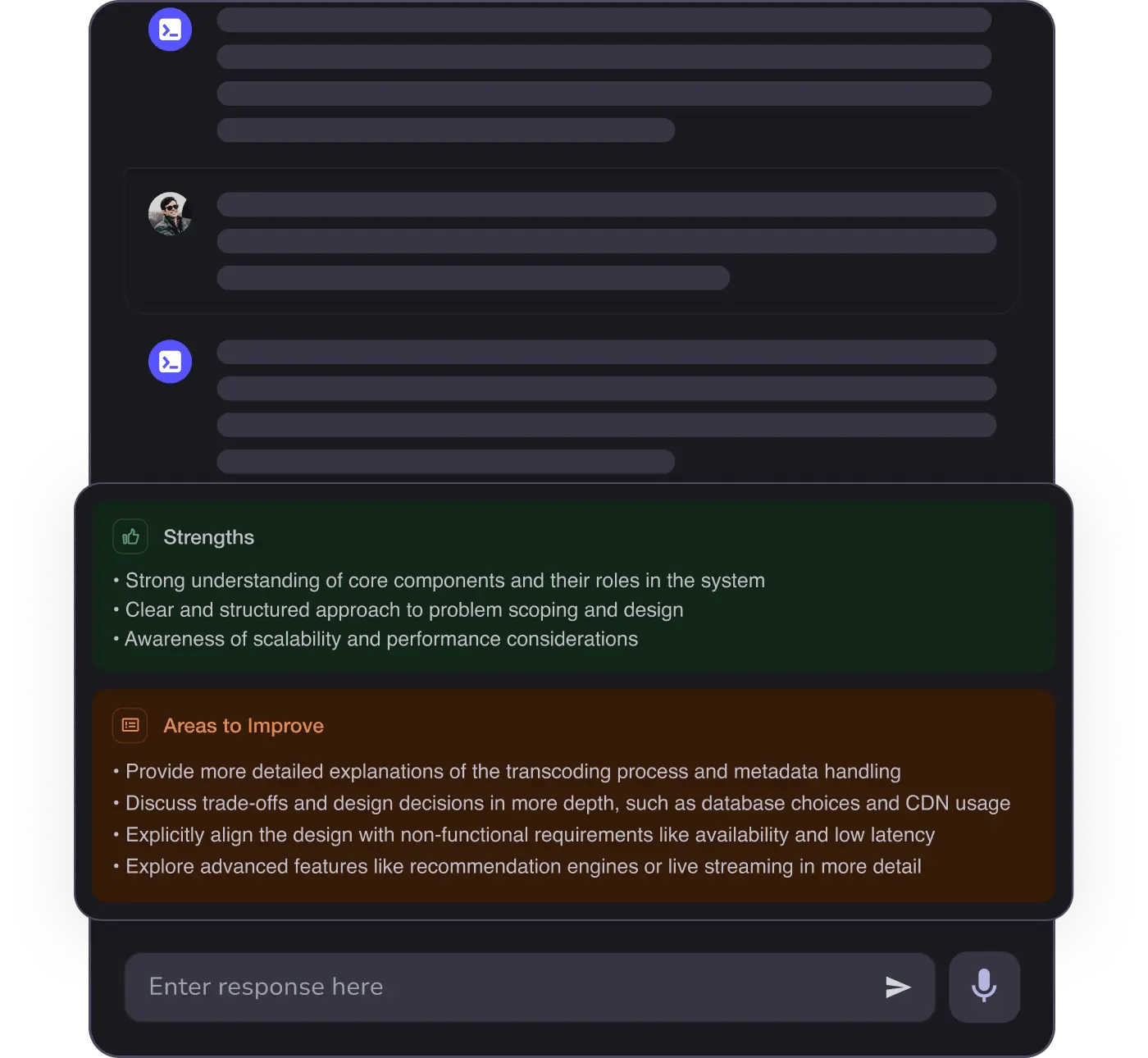
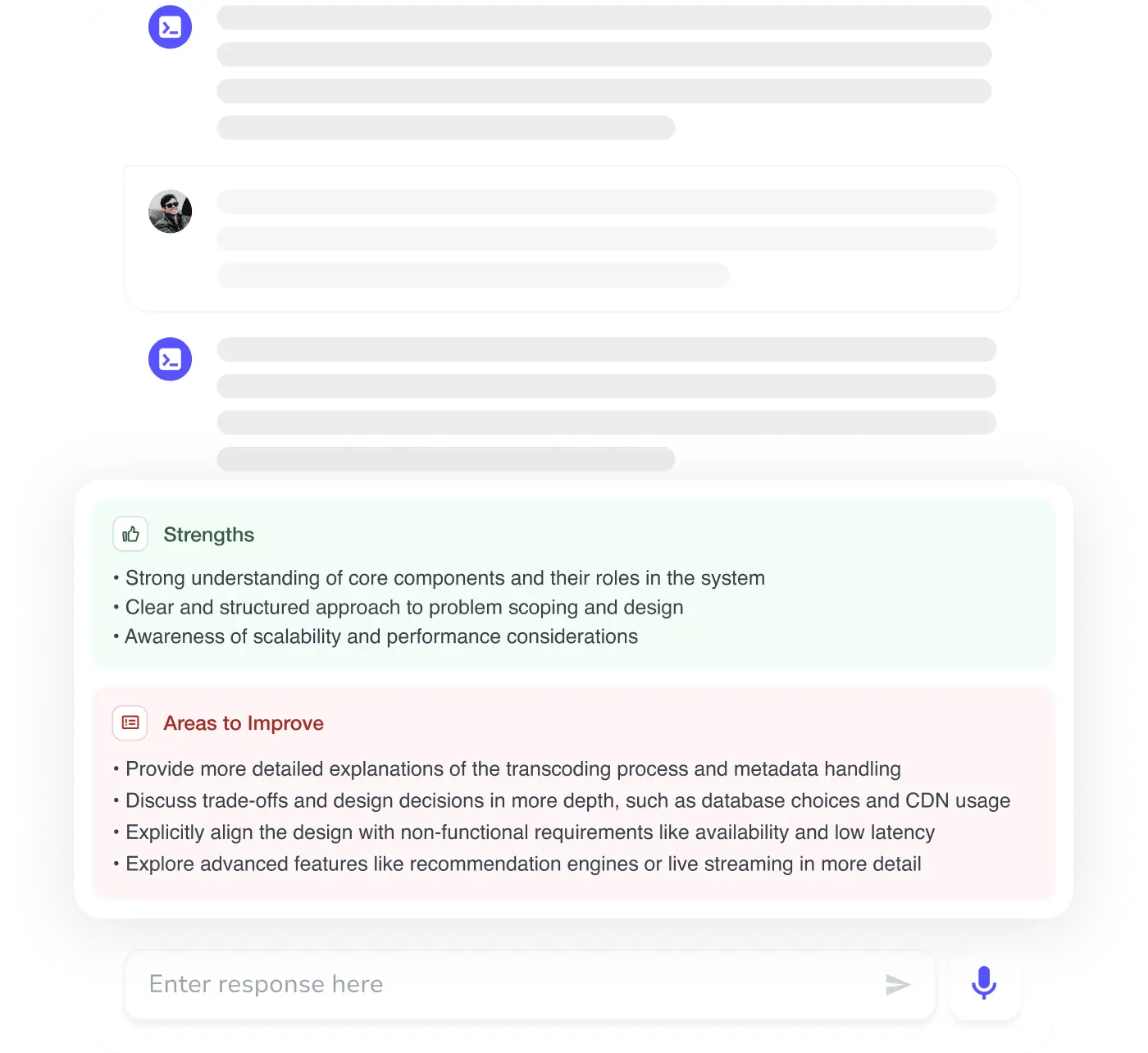
MAANG+ Interview Prep
AI Mock Interviews simulate every technical loop at top companies
Free Resources
