AI-powered learning
Save this course
From Pandas to PySpark DataFrame
Gain insights into enhancing Python data processing with PySpark. Delve into reading, transforming, aggregating data, and creating user-defined functions, boosting efficiency with Apache Spark.
4.7
39 Lessons
3h 3min
Join 3 million developers at
Join 3 million developers at
LEARNING OBJECTIVES
- A working knowledge of Apache Spark and the PySpark library for Python
- A strong understanding of the advantages of using PySpark instead of Pandas for processing large datasets
- The ability to calculate some Metrics or produce aggregated analytics reporting solutions
- The ability to write Production Code in PySpark
Learning Roadmap
1.
Introduction
Introduction
Learn how to use PySpark for large-scale data processing and Amazon Review Data analysis.
2.
Data Input/Output
Data Input/Output
Walk through data input/output processes including reading, renaming, selecting, saving, and challenges.
3.
Data Transformation
Data Transformation
16 Lessons
16 Lessons
Work your way through transforming data, handling date-time, imputing, and evaluating reviews using pandas and PySpark.
4.
User Defined Function (UDF)
User Defined Function (UDF)
8 Lessons
8 Lessons
Build a foundation in creating and using UDFs in PySpark for custom transformations.
6.
Appendix
Appendix
2 Lessons
2 Lessons
Focus on the Amazon Review Data (2018) and Pandas vs. PySpark performance.
Certificate of Completion
Showcase your accomplishment by sharing your certificate of completion.
Complete more lessons to unlock your certificate
Developed by MAANG Engineers
ABOUT THIS COURSE
Pandas is a popular Python library used to manipulate data, but it has certain limitations in its ability to process large datasets. The Apache Spark analytics library offers significant performance improvements.
This course will help improve your Python-based data processing by leveraging Apache Spark’s multithreading capabilities through the PySpark library. You’ll start by reading data into a PySpark DataFrame before performing basic input/output functions, such as renaming attributes, selecting, and writing data. You’ll move onto transformation functions like aggregation, statistical analysis, and joins before creating custom, user-defined functions. At each step, you’ll get a quick Pandas review before being walked through leveraging the more robust PySpark library to unlock Apache Spark.
By the end of this course, you’ll be able to quickly and reliably process large amounts of data, even stored across multiple files, using PySpark.
ABOUT THE AUTHOR

MrDataPsycho
Data science product developer, Cloud Native Data Science advocate and Author.
Trusted by 3 million developers working at companies
A
Anthony Walker
@_webarchitect_
E
Evan Dunbar
ML Engineer
S
Software Developer
Carlos Matias La Borde
S
Souvik Kundu
Front-end Developer
V
Vinay Krishnaiah
Software Developer
Built for 10x Developers
No Passive Learning
Learn by building with project-based lessons and in-browser code editor
Personalized Roadmaps
The platform adapts to your strengths & skills gaps as you go
Future-proof Your Career
Get hands-on with in-demand skills
AI Code Mentor
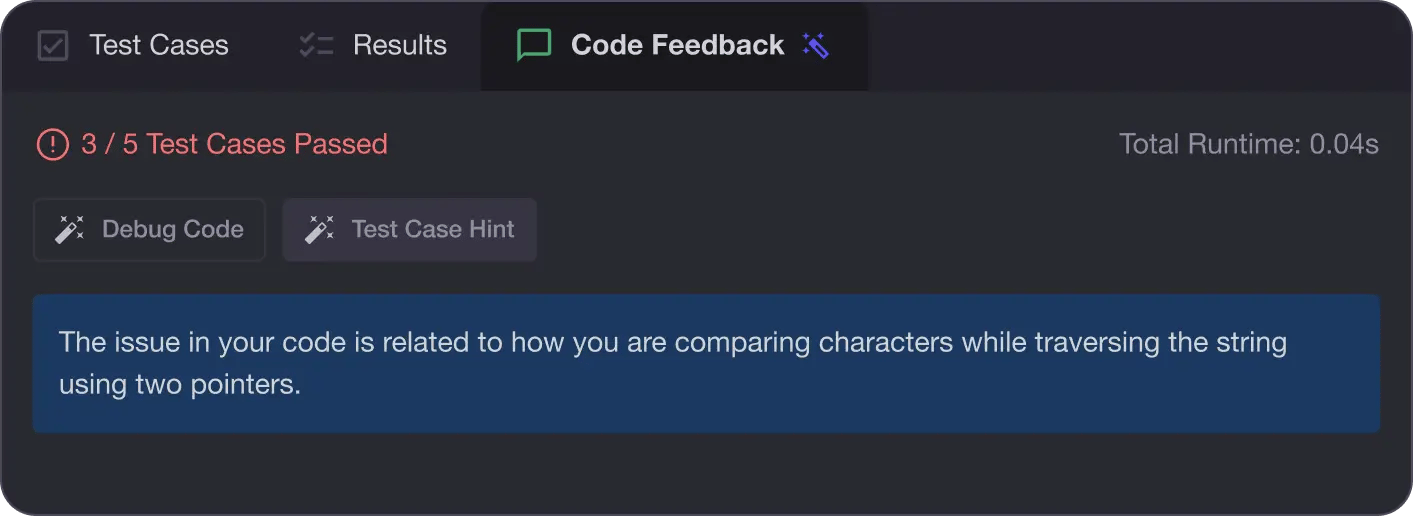
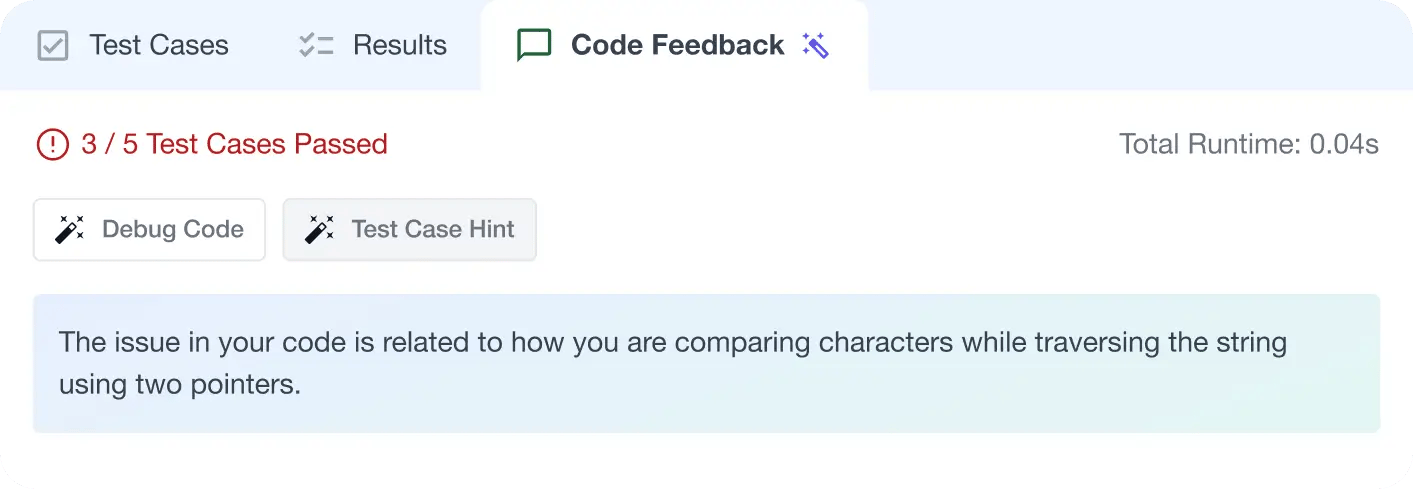
Write better code with AI feedback, smart debugging, and "Ask AI"
MAANG+ Interview Prep
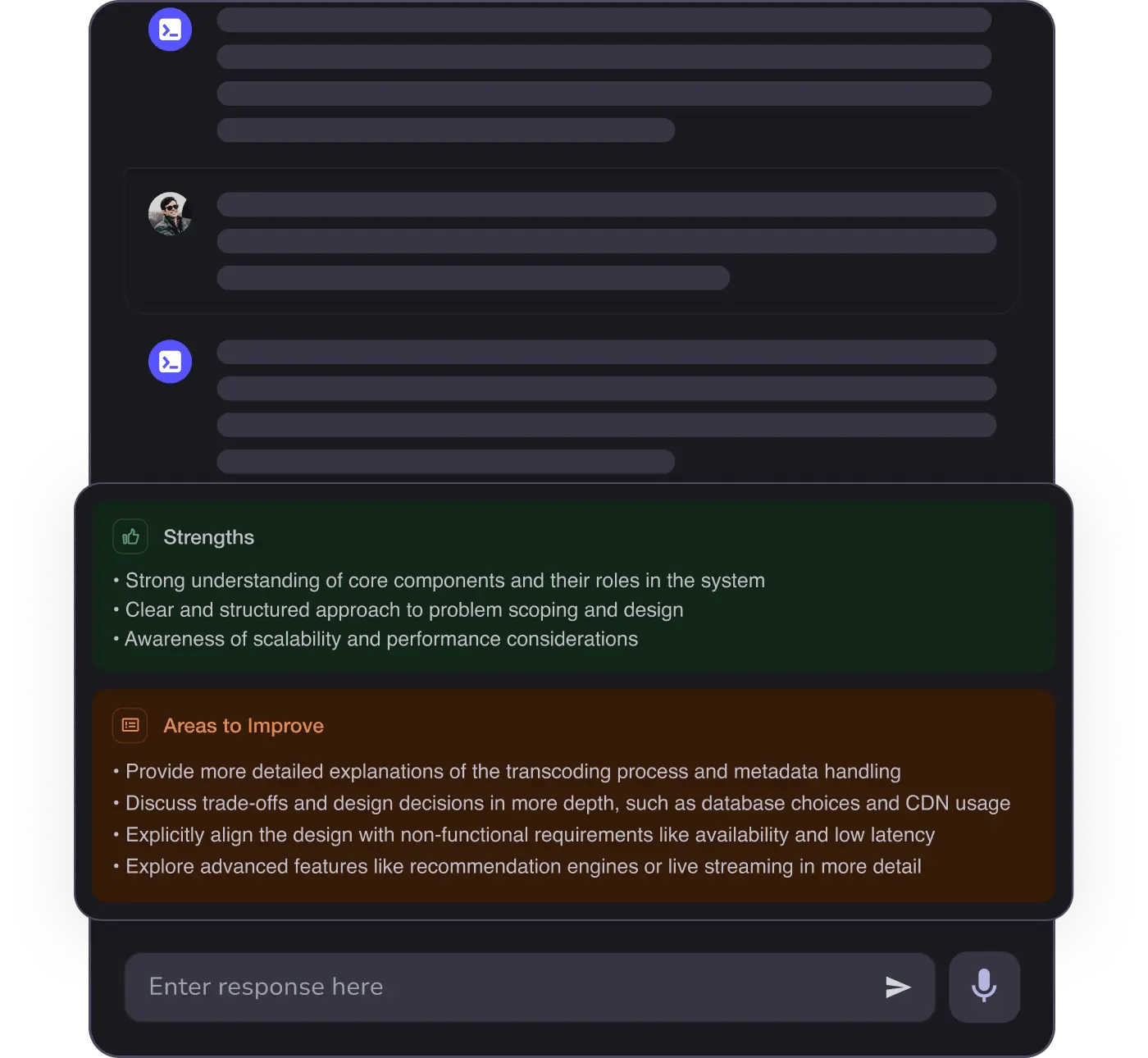
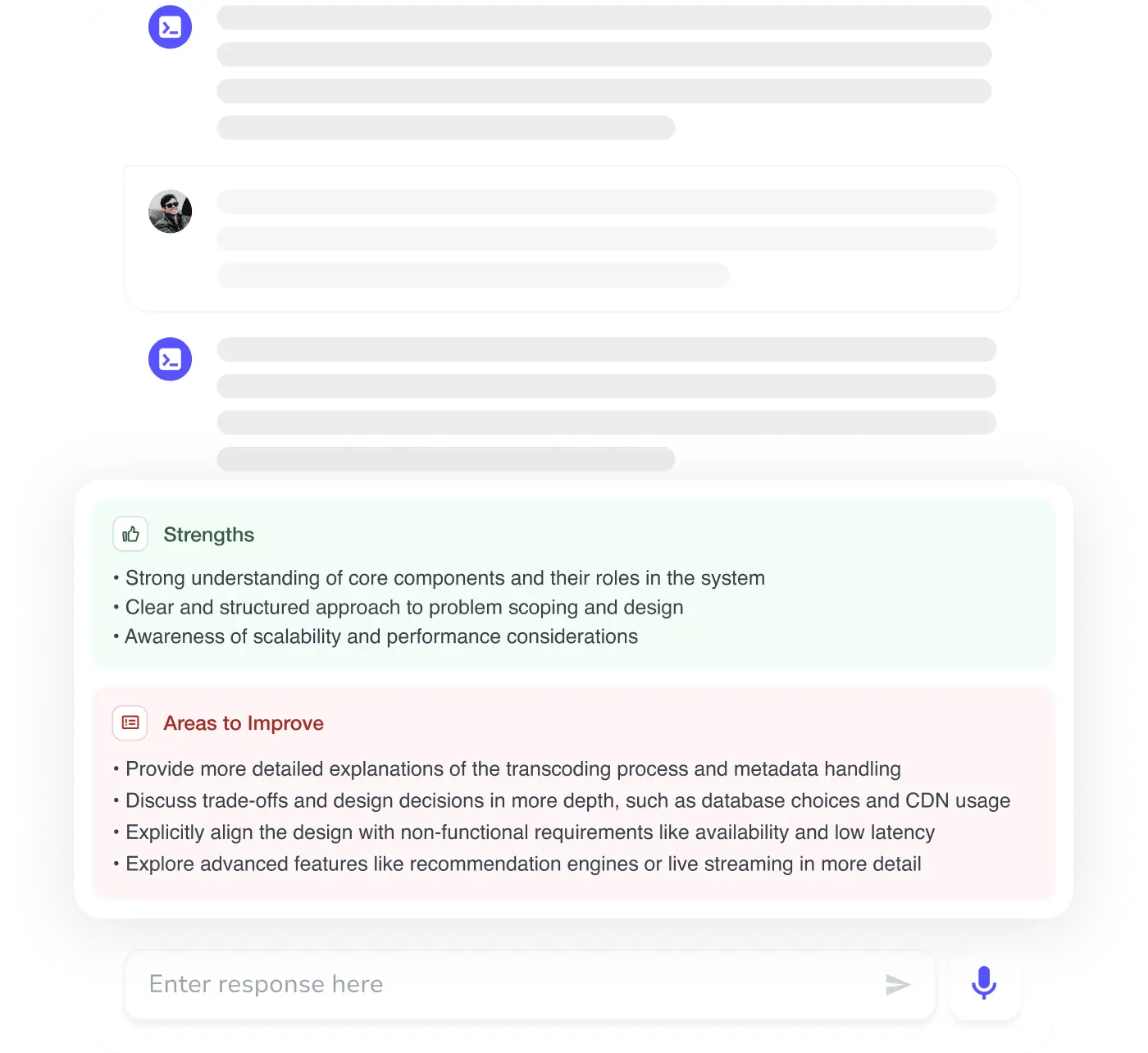
AI Mock Interviews simulate every technical loop at top companies
Free Resources
