AI-powered learning
Free
Save this course
Using OpenAI API for Natural Language Processing in JavaScript
Learn to integrate the OpenAI API with JavaScript and React for NLP tasks like text generation, classification, moderation, and embeddings in dynamic apps.
5.0
14 Lessons
4h
Updated 5 months ago
Join 3 million developers at
Join 3 million developers at
LEARNING OBJECTIVES
- An understanding of how to use the OpenAI API to perform text generation, classification, and transformation tasks in JavaScript
- The ability to generate, complete, and optimize text using the OpenAI API‘s completions endpoint
- Hands-on experience applying content moderation for safety and utilizing embeddings for advanced text analysis
- The ability to integrate the OpenAI API into React applications for creating interactive and dynamic user interfaces
- Hands-on experience developing real-world applications that leverage the OpenAI API for text generation, classification, and more within modern web frameworks like React
Learning Roadmap
1.
Introduction
Introduction
Get familiar with OpenAI API for NLP in JavaScript, GPT-3 models, and registration steps.
2.
The Completions Endpoint
The Completions Endpoint
Discover the logic behind utilizing the OpenAI API for versatile text tasks and optimizations.
3.
Miscellaneous Endpoints
Miscellaneous Endpoints
2 Lessons
2 Lessons
Go hands-on with OpenAI moderations for content safety and embeddings for text analysis.
Certificate of Completion
Showcase your accomplishment by sharing your certificate of completion.
Complete more lessons to unlock your certificate
Developed by MAANG Engineers
ABOUT THIS COURSE
This course will teach you how to use the OpenAI API for natural language processing (NLP) in JavaScript, specifically focusing on the powerful GPT-3 models. You’ll begin by getting familiar with the registration process and OpenAI API overview, laying the foundation for deeper exploration into text generation and manipulation tasks.
Next, you’ll explore the core API functionality, including the completions endpoint, which performs various NLP tasks, such as text classification, transformation, and completing incomplete content. You’ll also gain hands-on experience using the moderation endpoint for content safety and embeddings for advanced text analysis.
Finally, you’ll develop your skills by integrating the OpenAI API into React, creating dynamic and interactive web applications. After completing this course, you’ll have the practical knowledge to build AI-driven applications to generate, analyze, and safely manage text-based data in real-world projects.
Trusted by 3 million developers working at companies
A
Anthony Walker
@_webarchitect_
E
Evan Dunbar
ML Engineer
S
Software Developer
Carlos Matias La Borde
S
Souvik Kundu
Front-end Developer
V
Vinay Krishnaiah
Software Developer
Built for 10x Developers
No Passive Learning
Learn by building with project-based lessons and in-browser code editor
Personalized Roadmaps
The platform adapts to your strengths & skills gaps as you go
Future-proof Your Career
Get hands-on with in-demand skills
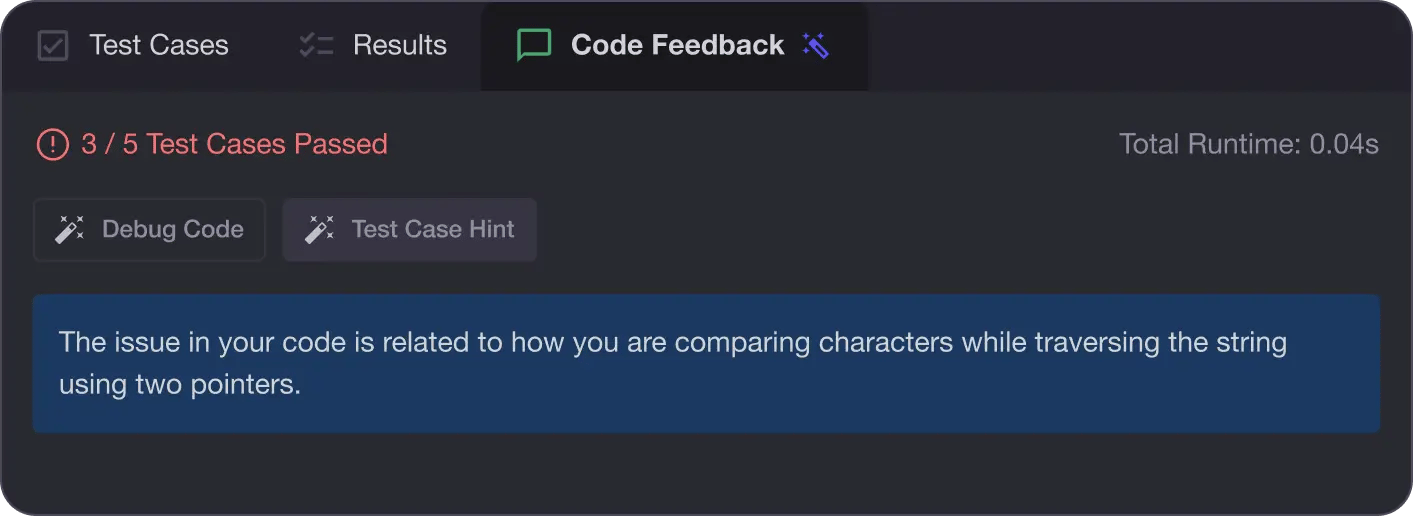
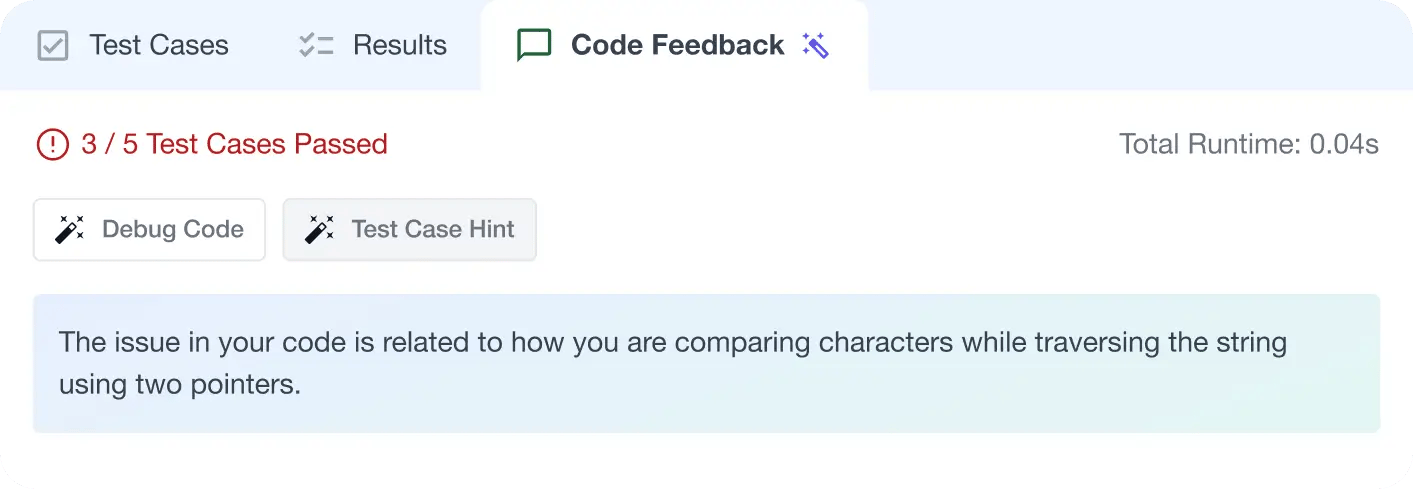
AI Code Mentor
Write better code with AI feedback, smart debugging, and "Ask AI"
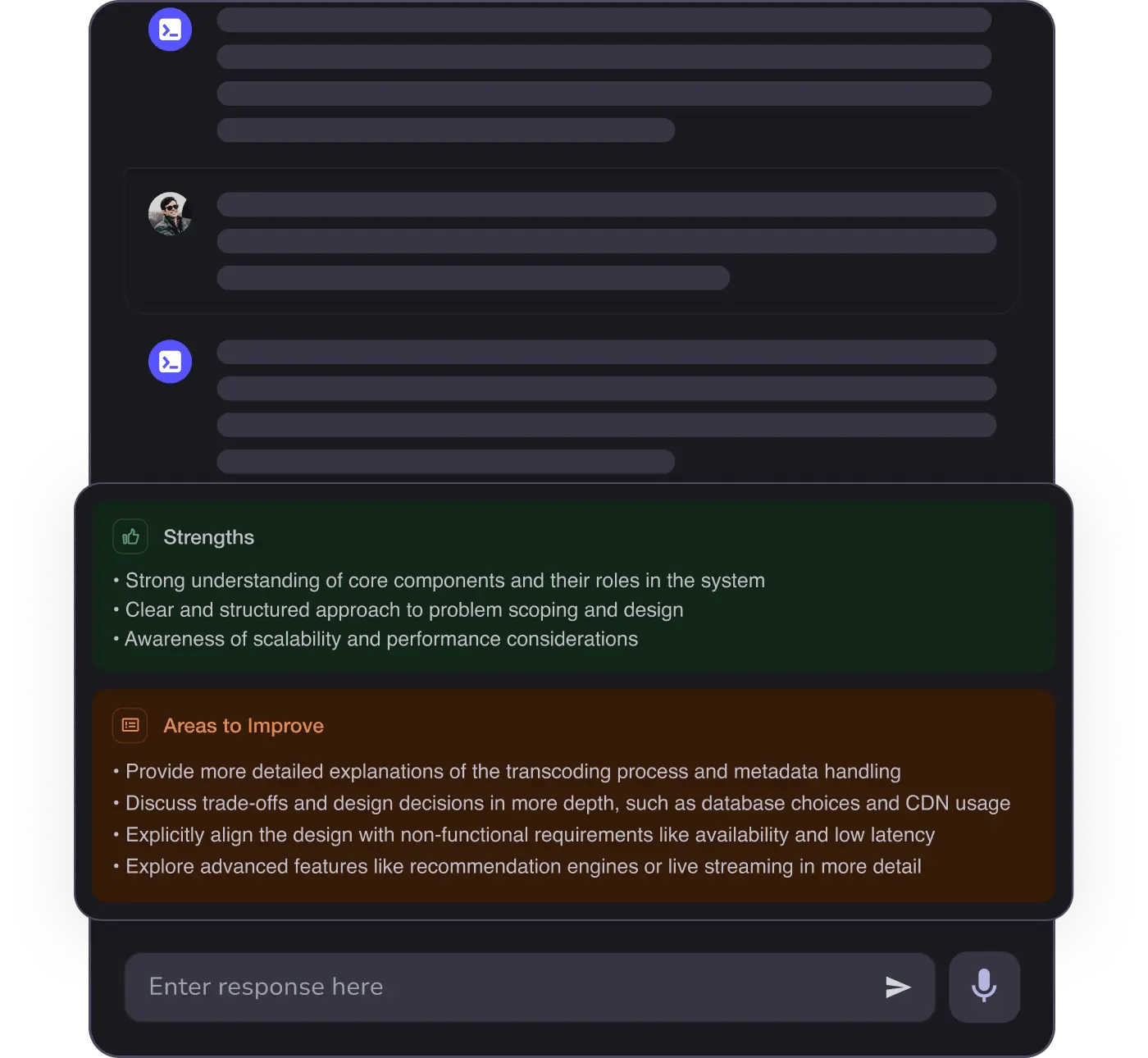
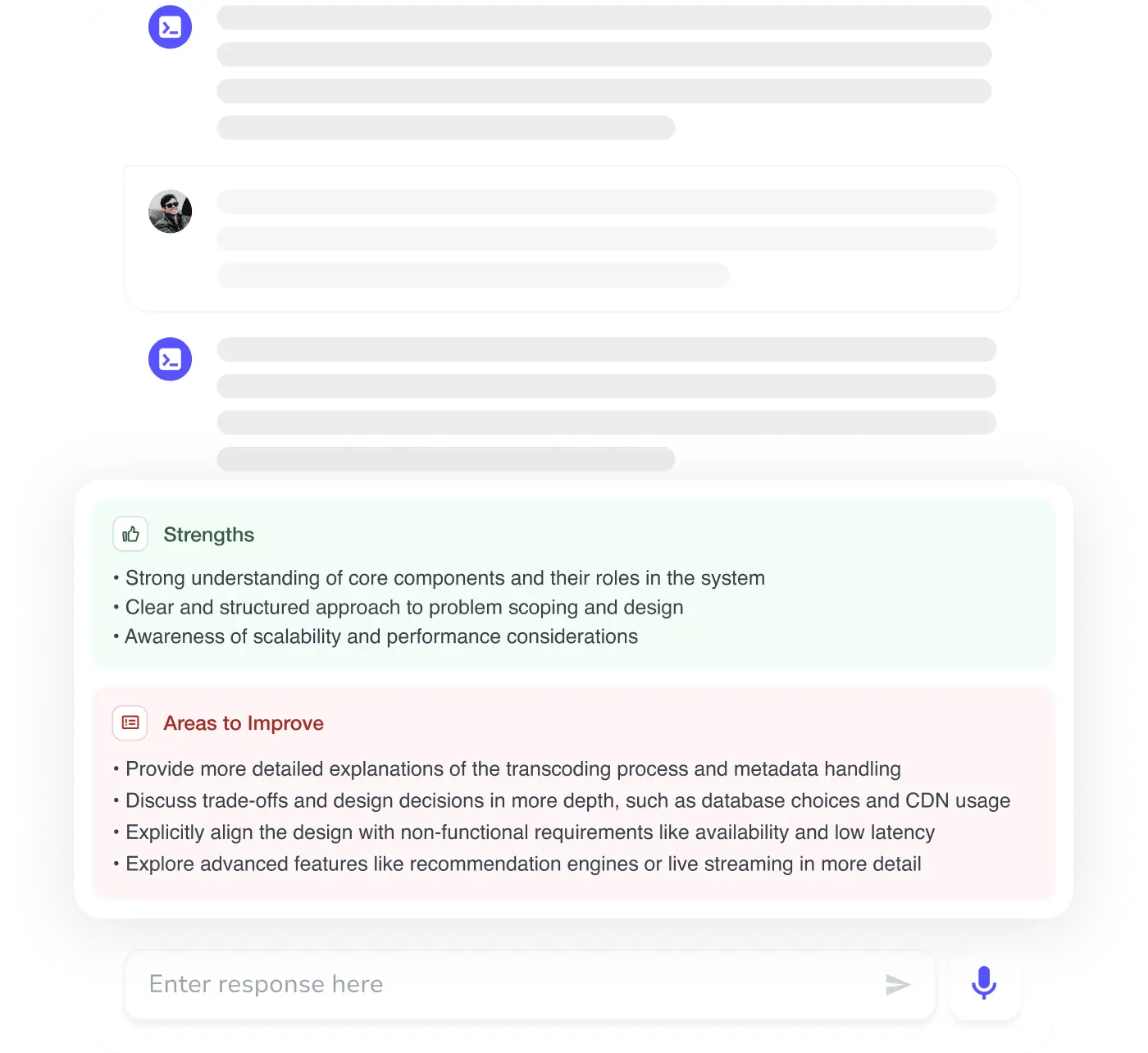
MAANG+ Interview Prep
AI Mock Interviews simulate every technical loop at top companies
Free Resources
