




Understand the fundamentals of data structures and algorithms, as Amazon interviews often involve complex problem-solving. Practice coding regularly. Check out the previous Amazon coding interview questions and practice well with them.
Table of Contents
Cracking the top Amazon coding interview questions
47 mins read
Apr 30, 2026
Share
Landing a job at Amazon is a dream for many developers around the globe. Amazon is one of the largest companies in the world, with a workforce of over half a million strong.
For you to join them, you’ll need to complete their unique interview that combines technical and leadership knowledge.
Today, we’ll walk you through everything you need to crack the Amazon technical interview, including questions and answers for coding problems and a step-by-step tech interview prep guide.
Amazon Leetcode Questions#
Amazon is a dream company for many developers. To get yourself a job at Amazon, the most important part is to practice your interview skills and apply for the correct position. Make sure you thoroughly look at the job description to ensure that it matches your skill set. The next step is to practice some Amazon Leetcode Questions. Solving Leetcode problems is an exceptional way to practice your coding skills.
Educative has curated a collection of Amazon-specific LeetCode problems to facilitate focused practice. There’s no need to feel overwhelmed by the vast array of over 2000+ LeetCode problems. With this select set, you can practice and develop the logic necessary to tackle all the coding problems typically encountered in Amazon interviews. We’veve also added 40+ commonly asked Amazon coding interview questions for you to practice and improve your skills. For detailed lists of questions curated to help you ace the Amazon coding interviews, Educative-99 and Educative-77 are the perfect places to start.
Top 20 Amazon LeetCode problems you should practice#
Problem name | Difficulty | Key pattern |
Two Sum | Easy | Hash map |
Valid Parentheses | Easy | Stack |
Merge Two Sorted Lists | Easy | Linked list |
Best Time to Buy and Sell Stock | Easy | Greedy |
Maximum Subarray | Easy | Dynamic programming |
Longest Substring Without Repeating Characters | Medium | Sliding window |
Add Two Numbers | Medium | Linked list |
Longest Palindromic Substring | Medium | Two pointers |
Group Anagrams | Medium | Hash map |
Top K Frequent Elements | Medium | Heap |
Kth Largest Element in an Array | Medium | Heap / Quickselect |
Binary Tree Level Order Traversal | Medium | BFS |
Number of Islands | Medium | DFS / BFS |
Course Schedule | Medium | Graph / Topological sort |
Merge Intervals | Medium | Sorting |
LRU Cache | Hard | Hash map + doubly linked list |
Word Ladder | Hard | BFS |
Median of Two Sorted Arrays | Hard | Binary search |
Trapping Rain Water | Hard | Two pointers |
Serialize and Deserialize Binary Tree | Hard | Tree / DFS |
How to use this list effectively#
Focus on patterns, not just memorizing solutions—recognize when to use sliding window, BFS, or dynamic programming
Practice under time constraints to simulate real interview conditions
Revisit problems after a few days to strengthen retention
Group problems by pattern and solve similar ones together
These problems reflect common Amazon interview patterns like graphs, BFS/DFS, sliding window, and heaps—mastering them will give you a strong edge.
Answer any Amazon interview question by learning the patterns behind common questions.#
45 common Amazon technical coding interview questions#
1. Find the missing number in the array#
You are given an array of positive numbers from 1 to n, such that all numbers from 1 to n are present except one number x. You have to find x. The input array is not sorted. Look at the below array and give it a try before checking the solution.
n = 8 missing number = 6
View the find the missing number solution in C++, Java, JavaScript, and Ruby.
A naive solution is to simply search for every integer between 1 and n in the input array, stopping the search as soon as there is a missing number. However we can do better. Here is a linear,
Find the sum
sum_of_elementsof all the numbers in the array.Then, find the sum
actual_sumof the firstnnumbers using the arithmetic series sum formula. The difference between these, i.e.,
actual_sum - sum_of_elements, is the missing number in the array.
Runtime complexity: Linear,
Memory complexity: Constant,
2. Determine if the sum of two integers is equal to the given value#
Given an array of integers and a value, determine if there are any two integers in the array whose sum is equal to the given value. Return true if the sum exists and return false if it does not. Consider this array and the target sums:
sum of two integers
View the sum of two integers solution in C++, Java, JavaScript, and Ruby.
We can use the following algorithm to find a pair that adds up to target.
Scan the whole array once and store visited elements in a hash set.
During the scan, for every element
numin the array, we check iftarget - numis present in the hash set, i.e.,target - numis already visited.If
target - numis found in the hash set, it means there is a pair (num,target - num) in the array whose sum is equal to the giventarget, so we return TRUE.If we have exhausted all elements in the array and found no such pair, the function will return FALSE.
Runtime complexity: Linear,
Memory complexity: Linear,
3. Merge two sorted linked lists#
Given two sorted linked lists, merge them so that the resulting linked list is also sorted. Consider two sorted linked lists and the merged list below them as an example.
Merge two sorted linked lists
View the merge two sorted linked lists solution in C++, Java, JavaScript, and Ruby.
Given that head1 and head2 are pointing to the head nodes of the given linked lists, respectively, if one of them is None, return the other as the merged list. Otherwise, perform the following steps:
Compare the data of the first nodes of both lists and initialize the
merged_headto the smaller of the two nodes. Also, initializemerged_tailasmerged_head. Move the smaller node pointer (head1orhead2) to the next node.Perform the following steps until either
head1orhead2is NULL:Compare the data of the current nodes pointed by
head1andhead2, append the smaller node tomerged_tail, and move the corresponding pointer forward.Update
merged_tailto the appended node.
After exiting the loop, if either list has remaining nodes, append the remaining nodes to the end of the merged list. Do this by updating the
nextpointer ofmerged_tailto point to the remaining nodes.Return
merged_head, which represents the head of the merged list.
Runtime complexity: Linear,
Memory complexity: Constant,
4. Copy linked list with arbitrary pointer#
You are given a linked list where the node has two pointers. The first is the regular next pointer. The second pointer is called arbitrary and it can point to any node in the linked list. Your job is to write code to make a deep copy of the given linked list. Here, deep copy means that any operations on the original list should not affect the copied list.
View the copy linked list solution in C++, Java, JavaScript, and Ruby.
If the given linked list’s head is NULL, return NULL as the copied list.
Initialize a
currentpointer withheadto traverse the original linked list. Also, initializenew_headandnew_prevpointers to NULL to keep track of the copied list. Additionally, create an empty dictionary (hashmap) namedhtto map nodes in the original and copied lists.Traverse the original linked list while creating a copy of each node. For each node:
Create a
new_nodewith the same data as thecurrentnode.Copy the
arbitrarypointer of thecurrentnode to thenew_node. Therefore, for now, we are pointing thearbitrarypointer of thenew_nodeto where it is pointing in the original node.If
new_nodeis the first node in the copied list, setnew_headandnew_prevtonew_node. Otherwise, connect thenew_nodeto the copied list by settingnew_prev.nexttonew_nodeand setnew_prevtonew_node.Store copied node
new_nodein thehtwith the keycurrent. This will help us point thearbitrarypointer of the copied nodes to the correct new nodes in the copied list.
For now, the
arbitrarypointers in the new nodes point to nodes in the original list. To update them, we traverse the new list usingnew_current, utilize the hashmaphtto find the corresponding copied node for each original node pointed to by thearbitrarypointer, and then update thearbitrarypointer of the current node to point to this copied node.Once all arbitrary pointers are updated, return
new_head, which represents the head of the copied list.
Runtime complexity: Linear,
Memory complexity: Linear,
5. Level order traversal of binary tree#
Given the root of a binary tree, display the node values at each level. Node values for all levels should be displayed on separate lines. Let’s take a look at the below binary tree.
Level order traversal for this tree should look like: 100; 50, 200; 25, 75, 350
View the level order traversal of binary tree solution in C++, Java, JavaScript, and Ruby.
Initialize a queue,
queue, with the root node.Iterate over the
queueuntil it’s empty:For each level, calculate the size (
level_size) of the queue.Initialize an empty list
level_nodes.Iterate
level_sizetimes:Dequeue a node from the
queue.Append the value of the dequeued node in
level_nodes.Enqueue the left child and the right child of the dequeued node in
queue, if they exist.
Convert
level_nodesto a comma-separated string and store it inresult.
Return the
result.
Runtime complexity: Linear,
Memory complexity: Linear,
6. Determine if a binary tree is a binary search tree#
Given a Binary Tree, figure out whether it’s a Binary Search Tree. In a binary search tree, each node’s key value is smaller than the key value of all nodes in the right subtree, and is greater than the key values of all nodes in the left subtree. Below is an example of a binary tree that is a valid BST.
Below is an example of a binary tree that is not a BST.
View the binary tree solution in C++, Java, JavaScript, and Ruby.
We use a recursive method to explore the binary tree while keeping track of the allowed range for each node’s value. At the start, the root node’s value can be any number. As we go down the tree, we adjust this range. For a left child, the value must be smaller than its parent’s value. For a right child, the value must be larger than its parent’s value. By doing this, we make sure that each node’s value is within the acceptable range set by its parent. If we find any node with a value outside this range, it means the tree doesn’t follow the rules of a binary search tree and is not valid as a BST.
Define a recursive function is_bst_rec that takes a node, min_val, and max_val as parameters.
Inside the function:
Check if the node is NULL. If so, return TRUE.
Verify if the current node’s value
node.vallies within the acceptable range defined bymin_val(exclusive) andmax_val(exclusive). If not, return FALSE.Recursively call
is_validfor the left subtree with the updatedmax_valas the current node’s value and for the right subtree with the updatedmin_valas the current node’s value.
Initialize the range by calling is_bst_rec with the root node, setting min_val to negative infinity and max_val to positive infinity.
Runtime complexity: Linear,
Memory complexity: Linear,
7. String segmentation#
You are given a dictionary of words and a large input string. You have to find out whether the input string can be completely segmented into the words of a given dictionary. The following two examples elaborate on the problem further.
Given a dictionary of words.
Input string of “applepie” can be segmented into dictionary words.
Input string “applepeer” cannot be segmented into dictionary words.
View the string segmentation solution in C++, Java, JavaScript, and Ruby.
The algorithm iteratively checks substrings of the input string against the dictionary. Starting with an empty string being segmentable, it gradually builds up segmentability information for larger substrings by considering all possible substrings and checking if they exist in the dictionary. Once we determine that a substring can be segmented into words from the dictionary, we mark the corresponding entry in an array dp array as TRUE. Subsequently, when processing longer substrings, we use dp to check whether shorter substrings within them have already been determined to be segmentable, avoiding recomputations.
Initialize a variable
nwith the length of the input word and create a boolean arraydpwith a size ofn + 1. Initialize all values ofdpto FALSE.Set
dp[0]to TRUE to indicate that the empty string can be segmented.Iterate over the indexes of the word from 1 to
n.For each index
i, iterate over the indexesjfrom 0 toi - 1.Check if
dp[j]is TRUE and if the substringword[j:i]exists in the dictionary.If both conditions are met, set
dp[i]to TRUE.
After completing the iterations, return
dp[n]to indicate whether the entire word can be segmented.
Runtime complexity: Polynomial,
Memory complexity: Linear,
8. Reverse words in a sentence#
Reverse the order of words in a given sentence (a string of words).
View the reverse words in a sentence solution in C++, Java, JavaScript, and Ruby.
The essence of this algorithm is to reverse the words in a string by a two-step method using two pointers, effectively manipulating the string in place. Initially, the entire string is reversed, which correctly repositions the words in reverse order. However, due to this reversal of the string, the corresponding characters of words are also reversed. To correct the order of the characters, iterate through the string, and identify the start and end of each word, considering space as a delimiter between words. Set two pointers at the start and end of the word to reverse the characters within that word. By repeating this process for each word, the method effectively achieves the goal without requiring additional memory.
Convert the string,
sentence, into a list of characters and store it back insentence.Get the length of the
sentenceand store it instr_len.Define a
str_revfunction to reverse the entire list of characterssentence.Set the start pointer
startto 0 and iterate over the range from 0 tostr_len + 1using the pointerend.When encountering a space or reaching the end of a word, reverse the characters of the word using the
str_revfunction withsentence,start, andend - 1as arguments.Update the start pointer
starttoend + 1.
Join the list of characters back into a string using
join(sentence).Return the reversed string.
Runtime complexity: Linear,
Memory complexity: Constant,
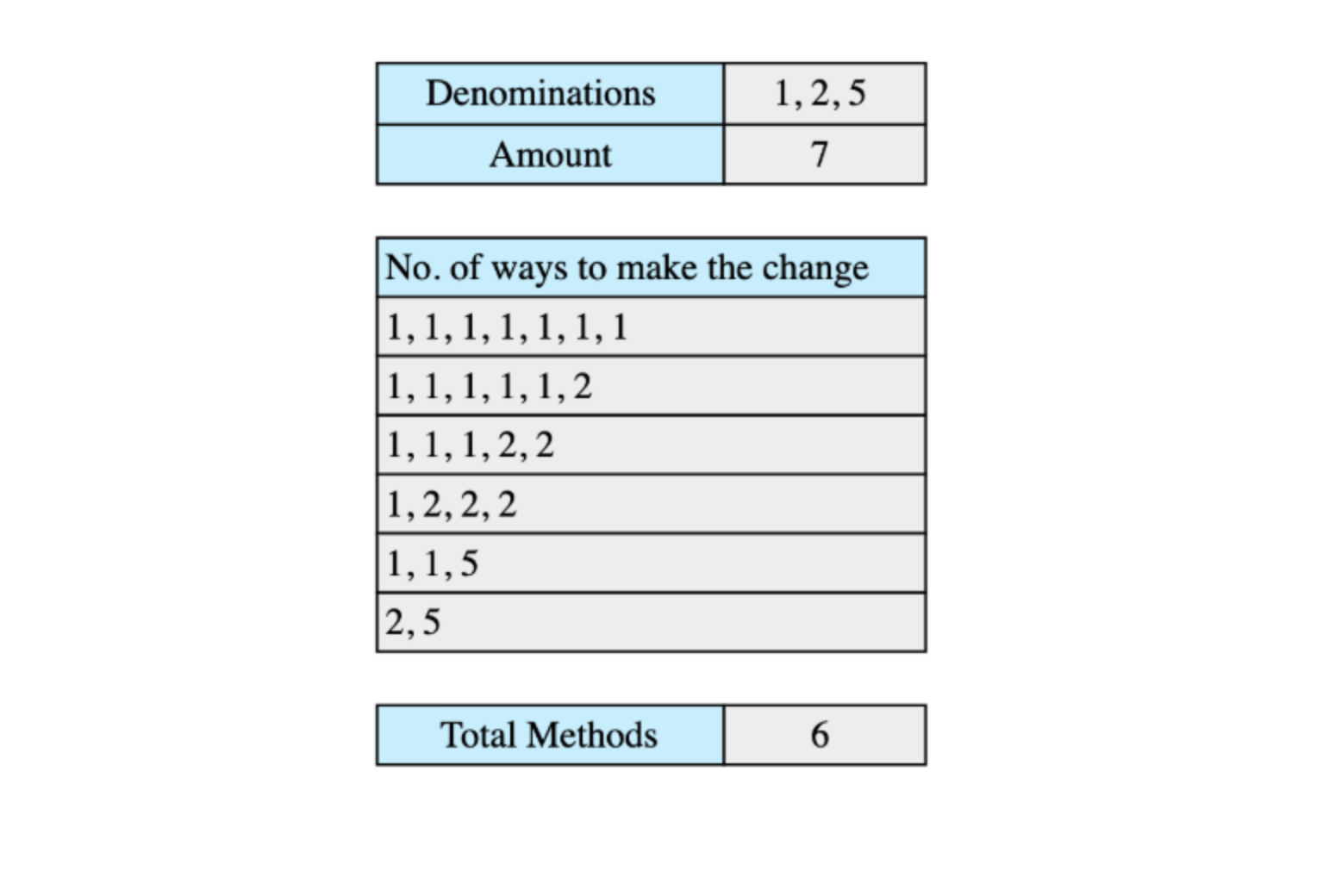
9. How many ways can you make change with coins and a total amount#
Suppose we have coin denominations of [1, 2, 5] and the total amount is 7. We can make changes in the following 6 ways:
View the coin changing problem solution in C++, Java, JavaScript, and Ruby.
We can use dynamic programming to build simple coin change solutions, store them, and utilize them in larger coin change amounts. We start by considering the simplest case, which is making change for an amount of zero. At this stage, there’s only one way to make a change, which is by using no coins. Then, we proceed to compute the number of ways to make change for larger amounts by considering each coin denomination one by one. For each denomination, we iterate through the possible amounts starting from the denomination value up to the target amount. At each step, we update the count of ways to make change for the current amount by incorporating the count for smaller amounts. This iterative process ensures that we exhaustively explore all valid combinations of coins, leading to an accurate count of the total number of ways to make change for the target amount.
Initialize an array
dpof size(amount + 1)to track the number of ways to make change.Set
dp[0] = 1to denote the one way to make change for an amount of zero.Iterate through each coin denomination:
For each denomination
den, iterate fromdentoamount.Update
dp[i]by addingdp[i - den]to account for the current denomination.
After processing all denominations and amounts,
dp[amount]holds the total number of ways to make change.
Runtime complexity: Quadratic,
Memory complexity: Linear,
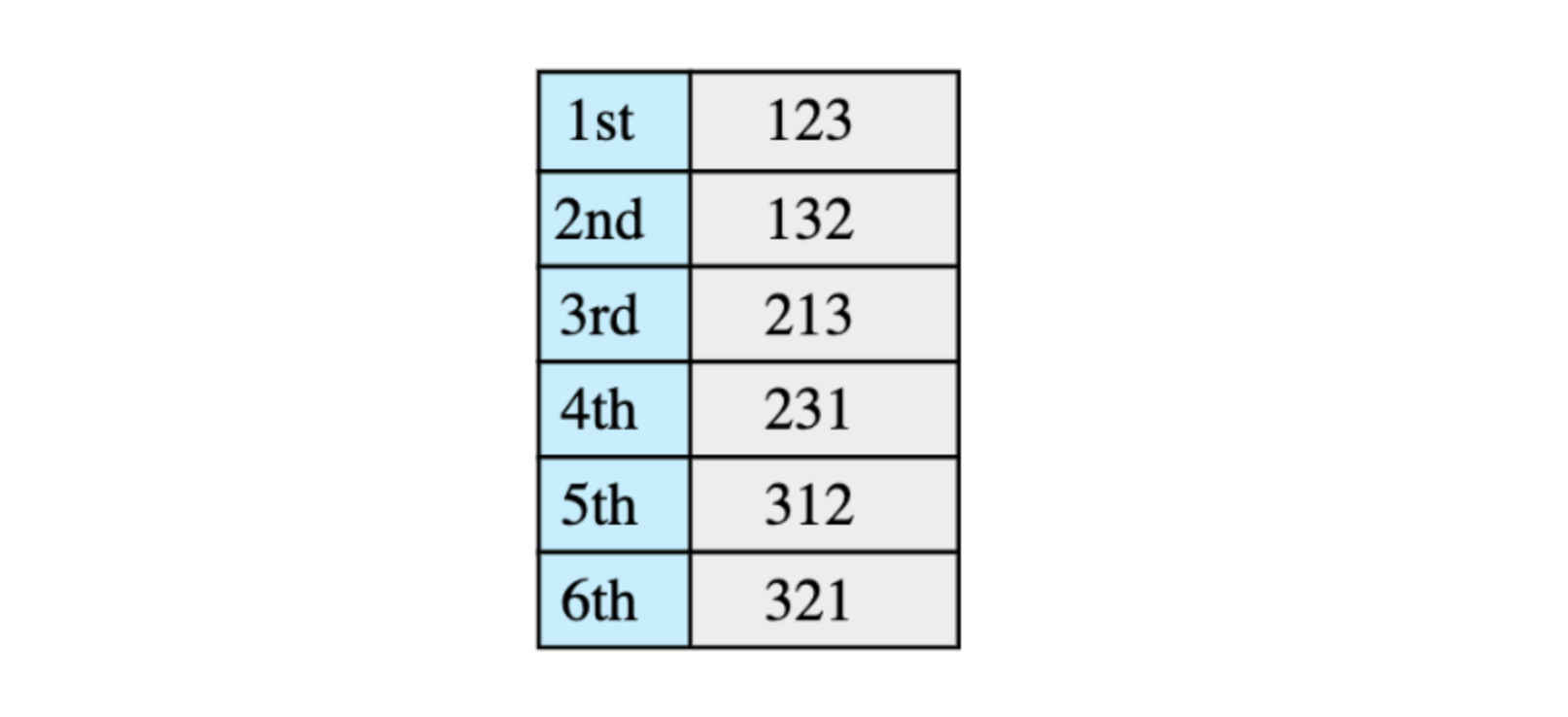
10. Find Kth permutation#
Given a set of ‘n’ elements, find their Kth permutation. Consider the following set of elements:
All permutations of the above elements are (with ordering):
Here we need to find the Kth permutation.
View the find Kth permutation solution in C++, Java, JavaScript, and Ruby.
We can divide all possible permutations into blocks, where each block represents a group of permutations sharing the same first element, and determine which block the target permutation belongs to by dividing the target position by the number of permutations within each block (block size).
Next, we can determine the first element of the permutation, based on the block’s position within all permutations and add it to our result. We also remove the selected element from the original set of elements to prevent duplication in the permutation.
Now, we can repeat the same process to find the remaining elements of the required permutation using the now reduced set of elements. We skipped the k this way and repeat the same process on the updated, smaller block of numbers.
To implement the algorithm:
Start by defining a function called
find_kth_permutation. This takes three parameters:v(the input list),k(the target position), andresult(the result string).Check if
vis empty. If so, return.Calculate the number of permutations starting with the first digit of
vand store it incount. This is done by computing the factorial of(n - 1)using the functionfactorial, wherenis the length ofv.Determine the target block by dividing
k-1by the number of blockscountand save inselected.Add the selected element
v[selected]toresult, and remove it fromv.Update
kto reflect the remaining permutations by subtractingcountmultiplied byselectedfromk.Recursively call the function with the updated parameters until
vis empty orkis 0.
Runtime complexity: Quadratic,
Memory complexity: Linear,
Answer any Amazon interview question by learning the patterns behind common questions.#
11. Find all subsets of a given set of integers#
We are given a set of integers and we have to find all the possible subsets of this set of integers. The following example elaborates on this further.
Given set of integers:
All possile subsets for the given set of integers:
View the find all subsets solution in C++, Java, JavaScript, and Ruby.
Instead of using nested loops to generate all possible combinations, this algorithm employs binary representation to efficiently derive all subsets of a given set. There are
To implement the algorithm:
Calculate the total number of subsets
subsets_count, which is. Iterate through numbers from
0tosubsets_count - 1using aforloop.Inside the loop, create an empty set called
stto store the current subset.Iterate through each index
jof the input listnumsusing anotherforloop.Write and use the function
get_bitto determine whether thejthbit of the current numberiis set to1or0.If the
jthbit ofiis1, add the corresponding element fromnumsto the current subsetst.
After iterating through all indexes of
nums, append the current subsetstto the listsets.
Runtime complexity: Exponential,
Memory complexity: Exponential,
12. Print balanced brace combinations#
Print all braces combinations for a given value n so that they are balanced. For this solution, we will be using recursion.
View the print balanced brace combinations solution in C++, Java, JavaScript, and Ruby.
The algorithm has the following main points:
Adding parentheses:
Determine whether to add a left parenthesis “{” or a right parenthesis “}” based on certain conditions:
If the count of left parentheses (
left_count) is less thann, a left parenthesis can be added to make a valid combination.If the count of right parentheses (
right_count) is less than the count of left parentheses (left_count), a right parenthesis can be added to make a valid combination.
Constructing the result: As the algorithm explores different combinations of parentheses, when
left_countandright_countboth reachn, indicating thatnpairs of parentheses have been added and the combination is complete, it appends the current combination present in theoutputlist to theresultlist.Backtracking:
After exploring a possible path by adding a parenthesis and making recursive calls, the algorithm backtracks to explore other possible combinations.
Backtracking involves removing the last added parenthesis from the
outputlist using thepopoperation.This reverts the
outputlist to its state before the current recursive call, allowing the algorithm to explore other possible combinations without missing any.
To implement the algorithm:
Initialize an empty list
outputto store the current combination and an empty listresultto store all valid combinations.Define a
print_all_braces_recfunction with parametersn(the total number of pairs),left_count,right_count,output, andresult.Inside
print_all_braces_rec:Check if both
left_countandright_countare greater than or equal ton. If TRUE, append a copy ofoutputtoresult.If
left_countis less thann, add a left parenthesis{tooutput, and recursively callprint_all_braces_recwithn,left_count + 1,right_count,output, andresult.After the recursive call, remove (
pop) the last element fromoutputto backtrack.If
right_countis less thanleft_count, add a right parenthesis}tooutput, and recursively callprint_all_braces_recwithn,left_count,right_count + 1,output, andresult.After the recursive call, remove (
pop) the last element fromoutputto backtrack.
Return the
resultlist containing all valid combinations of well-formed parentheses pairs for the givenn.
Runtime complexity: Exponential,
Memory complexity: Linear,
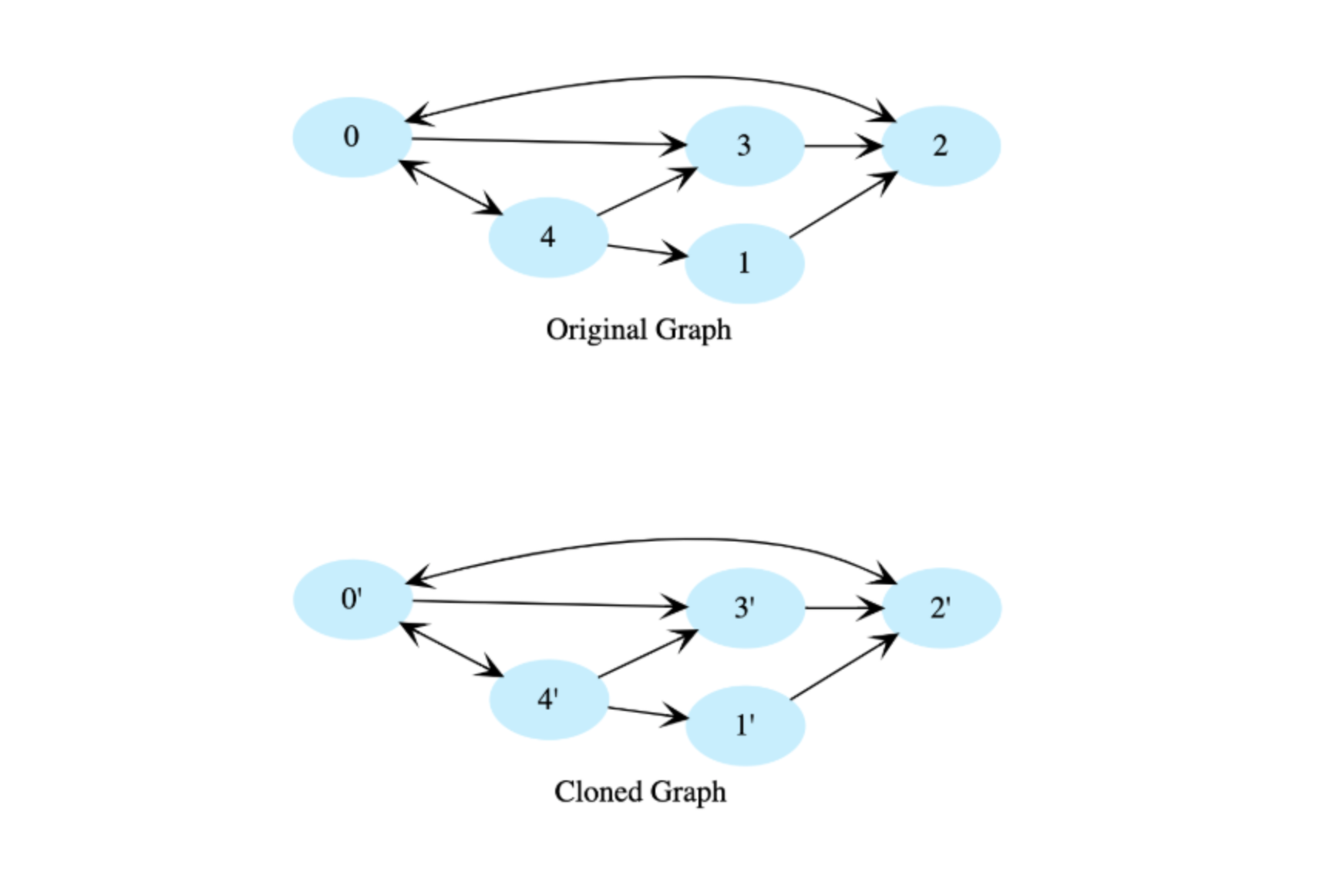
13. Clone a directed graph#
Given the root node of a directed graph, clone this graph by creating its deep copy so that the cloned graph has the same vertices and edges as the original graph.
Let’s look at the below graphs as an example. If the input graph is where V is set of vertices and E is set of edges, then the output graph (cloned graph) G’ = (V’, E’) such that V = V’ and E = E’. We are assuming that all vertices are reachable from the root vertex, i.e. we have a connected graph.
View the clone a directed graph solution in C++, Java, JavaScript, and Ruby.
This algorithm clones a directed graph by traversing it recursively. It creates a new node for each encountered node, replicates its data, and traverses its neighbors. If a neighbor has already been cloned, it uses the existing clone; otherwise, it recursively clones the neighbor. This process continues until all nodes and their relationships are replicated, resulting in a deep copy of the original graph.
To implement the algorithm:
Initialize an empty dictionary called
nodes_completedto keep track of cloned nodes.Write
clone_recfunction, which takesrootnode of the original graph and thenodes_completeddictionary as parameters. Inside the function:If the root node is None, return None.
Otherwise, create a new node
p_newwith the same data as the root and add it to thenodes_completeddictionary to mark it as visited.Iterate through each neighbor
pof the root node:If the neighbor
phas not been cloned yet (i.e., not present innodes_completed), recursively callclone_recwithpandnodes_completed, and add the clone to theneighborslist ofp_new.If the neighbor
phas already been cloned, retrieve the clonexfromnodes_completedand add it to theneighborslist ofp_new.
Call
clone_recand passrootandnodes_completedas parameters. When its recursion completes, return the cloned graph rooted atp_new.
Runtime complexity: Linear,
Memory complexity: Linear,
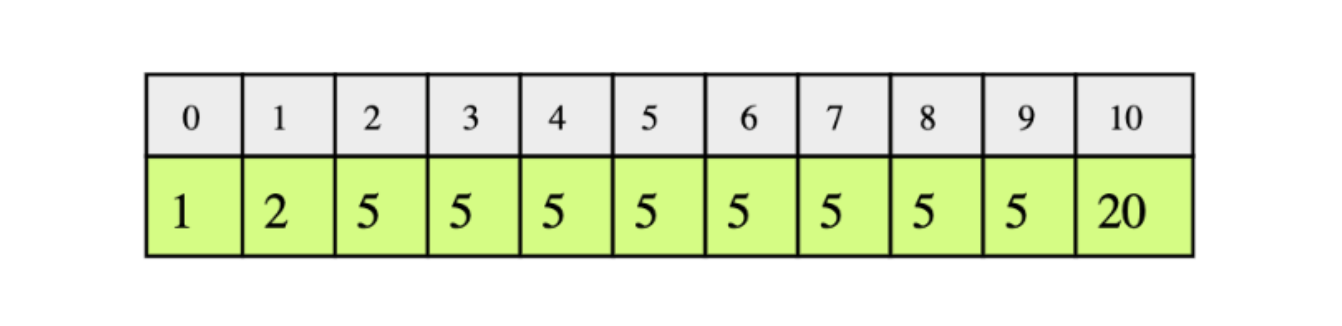
14. Find low/high index#
Given a sorted array of integers, return the low and high index of the given key. You must return -1 if the indexes are not found. The array length can be in the millions with many duplicates.
In the following example, according to the key, the low and high indices would be:
key: 1,low= 0 andhigh= 0key: 2,low= 1 andhigh= 1key: 5,low= 2 andhigh= 9key: 20,low= 10 andhigh= 10
For the testing of your code, the input array will be:
1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 6, 6, 6, 6
View the find low/high index solution in C++, Java, JavaScript, and Ruby.
We can modify the binary search algorithm to find the first occurrence of the key by narrowing down the search range even if the value at the mid is equal to the key. The algorithm is designed to always move to the left whenever it encounters an element that’s equal to or greater than the target. So, when the search range is narrowed down to a single element, and that element matches the target, it means that this is the leftmost occurrence of the target element in the array. Similarly, to find the last occurrence of a key, we adjust the search range toward the right whenever the middle element is less than or equal to the key. This iterative process continues until the search range narrows down to a single element. At this point, either the last occurrence of the key is found, or it confirms the absence of the key in the array.
To implement the algorithm:
Initialize
lowto 0,highto the length of the array minus one, andmidtohigh / 2.Enter a
whileloop that continues whilelowis less than or equal tohigh.Inside the loop, set
mid_elemtoarr[mid]Compare
mid_elemwith the key:If
mid_elemis less than the key, updatelowtomid + 1.Otherwise, update
hightomid - 1.
Update
midtolow + (high - low) / 2.
After the loop, check if
lowis within the bounds of the array and if the element at indexlowequals the key. If so, returnlow. Otherwise, return-1.
Repeat the same steps to find the last occurrence, with the only difference being in the comparison step. If mid_elem is less than or equal to the key, update low to mid + 1; and if it’s greater than the key, update high to mid - 1.
Runtime complexity: Logarithmic,
Memory complexity: Constant,
15. Search rotated array#
Search for a given number in a sorted array, with unique elements, that has been rotated by some arbitrary number. Return -1 if the number does not exist. Assume that the array does not contain duplicates.
View the search rotated array solution in C++, Java, JavaScript, and Ruby.
To tackle rotation in a binary search for a rotated array, we adjust the search range based on the middle element’s comparisons as follows:
If the element at the middle index matches the target, return the index of the middle element, as the target has been found.
If the element at the middle index is greater than or equal to the element at the start index, it implies that the left subarray (from the start to the middle) is sorted:
Now, check if the target falls within the range of elements from the leftmost element to the middle element. If it does, adjust the search range to focus on the left subarray.
Otherwise, adjust the search range to focus on the right subarray.
If the element at the middle index is less than the element at the end index, it indicates that the right subarray (from the middle to the end) is sorted:
Check if the target falls within the range of elements from the middle element to the rightmost element. If it does, adjust the search range to focus on the right subarray.
Otherwise, adjust the search range to focus on the left subarray.
To implement the algorithm:
Initialize
lowto 0 andhighto the length of the array minus one.Enter a
whileloop that continues whilelowis less than or equal tohigh.Inside the loop, calculate
midusing the formulalow + (high - low) // 2.Check if the element at the middle index matches the target. If it does, return the index of the middle element.
If
arr[low]is less than or equal toarr[mid], it implies that the left subarray (from low to mid) is sorted:If the target falls within this range, update the
hightomid - 1. Otherwise, update thelowtomid + 1.
Otherwise, it’s obvious that
arr[low]is greater thanarr[mid], which it indicates that the right subarray (from mid to high) is sorted:If the
targetfalls within this range, update thelowtomid + 1. Otherwise, update thehightomid - 1.
If the target is not found after the loop, return
-1to indicate its absence in the array.
Runtime complexity: Logarithmic,
Memory complexity: Constant,
More common Amazon technical coding interview questions#
Klargest elements from an array- Convert a Binary tree to DLL
- Given a binary tree
T, find the maximum path sum. The path may start and end at any node in the tree. - Rotate a matrix by 90 degrees
- Assembly line scheduling with dynamic programming
- Implement a stack with
push(),min(), andpop()in time - How do you rotate an array by K?
- Design Snake Game using Object Oriented Programming analysis and design technique.
- Print all permutations of a given string using recursion
- Implement a queue using a linked list
- Find the longest increasing subsequence of an array
- Lowest common ancestor in a Binary Search Tree and Binary Tree
- Rotate a given list to the right by
kplaces, which is non-negative. - Write a function that counts the total of set bits in a 32-bit integer.
- How do you detect a loop in a singly linked list?
- Reverse an array in groups
- Given a binary tree, check if it’s a mirror of itself
- Josephus problem for recursion
- Zero Sum Subarrays
- Huffman Decoding for greedy algorithms
- Egg Dropping Puzzle for dynamic programming
- N-Queen Problem
- Check if strings are rotations of each other
- 0-1 Knapsack Problem
- Unbounded knapsack problem
- Longest palindromic subsequence
- Print
nthnumber in the Fibonacci series - Longest common substring
- Longest common subsequence
Overview of the Amazon technical coding interview#
To land a software engineering job at Amazon, you need to know what lies ahead. The more prepared you are, the more confident you will be. So, let’s break it down.
-
Interview Timeline: The whole interview process takes 6 to 8 weeks to complete.
-
Types of Interviews: Amazon coding interviews consist of 5 to 7 interviews. This includes 1 assessment for fit and aptitude, 1-2 online tests, and 4-6 on-site interviews, also known as The Loop.
-
The Loop: The onsite interviews include 1 to 3 interviews with hiring managers and 1 bar raiser interview to evaluate Amazon’s 14 leadership principles.
-
Coding Questions: Amazon programming questions focus on algorithms, data structures, puzzles, and more.
-
Hiring Levels: Amazon usually hires at entry-level 4 (out of 12 total), and the average salary for that level ranges from $106,000 to $114,000 yearly.
-
Hiring Teams: Amazon hires based on teams. The most common hiring teams are Alexa and AWS.
-
Programming Languages: Amazon prefers the following programming languages for coding questions: Java, C++, Python, Ruby, and Perl.
Amazon’s 14 leadership principles#
Though coding interviews at Amazon are similar to other big tech companies, there are a few differences in their process, in particular, the Bar Raiser. Amazon brings in an objective third-party interviewer called a Bar Raiser, who evaluates candidates on Amazon’s 14 Leadership Principles. The Bar Raiser has complete veto power over whether or not you will be hired.
It is unlikely that you will know which of your interviewers is the Bar Raiser. The key is to take every part of the interview seriously and always assume you’re being evaluated for cultural fit as well as technical competency.
Below are the 14 values that you will be evaluated on.
- Customer Obsession: Leaders start with the customer and work backwards. They work vigorously to earn and keep customer trust.
- Ownership: Leaders are owners. They think long term and don’t sacrifice long-term value for short-term results. They act on behalf of the entire company. They never say “that’s not my job."
- Invent and Simplify: Leaders expect and require innovation and invention from their teams and always find ways to simplify. They are externally aware, look for new ideas from everywhere, and are not limited by “not invented here."
- Are Right, A Lot: Leaders are right a lot. They have strong judgment and good instincts. They seek diverse perspectives and work to disconfirm their beliefs.
- Learn and Be Curious: Leaders are never done learning and always seek to improve themselves.
- Hire and Develop the Best: Leaders raise the performance bar with every hire and promotion. They recognize exceptional talent, and willingly move them throughout the organization.
- Insist on the Highest Standards: Leaders have relentlessly high standards — many people may think these standards are unreasonably high. Leaders are continually raising the bar.
- Think Big: Thinking small is a self-fulfilling prophecy. Leaders create and communicate a bold direction that inspires results.
- Bias for Action: Speed matters in business. Many decisions and actions are reversible and do not need extensive study. We value calculated risk taking.
- Frugality: Accomplish more with less. Constraints breed resourcefulness, self-sufficiency, and invention.
- Earn Trust: Leaders listen attentively, speak candidly, and treat others respectfully. They are vocally self-critical, even when doing so is awkward or embarrassing.
- Dive Deep: Leaders operate at all levels, stay connected to the details, audit frequently, and are skeptical when metrics differ. No task is beneath them.
- Have Backbone; Disagree and Commit: Leaders are obligated to respectfully challenge decisions when they disagree, even when doing so is uncomfortable or exhausting.
- Deliver Results: Leaders focus on the key inputs for their business and deliver them with the right quality and in a timely fashion. Despite setbacks, they rise to the occasion and never settle.
Amazon Leadership Principles (with STAR method examples)#
Amazon interviews are heavily driven by its Leadership Principles. You’re not just expected to know them—you’re expected to demonstrate them through real experiences using the STAR method (Situation, Task, Action, Result). If you prepare well, the same story can often map to multiple principles.
Customer Obsession#
Customer Obsession means you start with the customer and work backward. In practice, this shows up when you prioritize user experience, even if it requires extra effort or trade-offs. As an engineer, this often means optimizing performance, fixing edge cases, or advocating for better UX.
Amazon looks for candidates who consistently prioritize customer impact over convenience.
Example question: Tell me about a time you improved the customer experience.
STAR example:
While working on an e-commerce platform, I noticed users were abandoning carts due to slow checkout times. My task was to improve the checkout experience without changing core business logic. I profiled the system, identified redundant API calls, and implemented request batching and caching. As a result, checkout time dropped by 35%, and conversion rates increased by 12%.
Ownership#
Ownership means thinking long-term and taking responsibility beyond your assigned tasks. Engineers show ownership when they fix issues proactively, maintain systems, and step in even when something isn’t “their job.”
Amazon looks for people who act like owners, not just contributors.
Example question: Tell me about a time you took ownership of a problem.
STAR example:
A production service I depended on had frequent outages, but no clear owner. I took responsibility to stabilize it by adding monitoring, alerting, and retry logic. I also documented the system and shared improvements with the team. Over time, system reliability improved, and outages dropped by 50%.
Invent and Simplify#
This principle is about finding smarter, simpler ways to solve problems. In engineering, this often means reducing complexity, automating workflows, or removing unnecessary components.
Amazon looks for people who innovate but also reduce long-term maintenance cost.
Example question: Describe a time you simplified a complex system.
STAR example:
Our deployment process required multiple manual steps across teams, causing delays. I was tasked with improving deployment efficiency. I built a CI/CD pipeline that automated testing and deployment with rollback support. This reduced deployment time from 2 hours to 10 minutes and eliminated manual errors.
Are Right, A Lot#
Being right a lot means making good decisions based on data, experience, and judgment. It also means being open to changing your mind when presented with better information.
Amazon looks for strong decision-makers who balance intuition with data.
Example question: Tell me about a time you made a tough decision.
STAR example:
We had to choose between two database designs for scalability. I analyzed usage patterns, ran benchmarks, and consulted teammates. I recommended a partitioned design, even though it required more initial work. The system later handled 3× traffic without performance issues.
Learn and Be Curious#
Amazon values continuous learning and curiosity. Engineers are expected to explore new tools, improve their skills, and stay updated with industry trends.
Amazon looks for people who proactively grow and adapt.
Example question: What’s something new you’ve learned recently?
STAR example:
I noticed performance bottlenecks in our system and decided to learn Redis for caching. After implementing it, I reduced database load by 40% and improved response times significantly. This also helped me guide the team in future optimizations.
Hire and Develop the Best#
This principle focuses on raising the bar by mentoring others and contributing to hiring. Engineers demonstrate this by helping teammates grow and improving team quality.
Amazon looks for people who elevate others, not just themselves.
Example question: Tell me about a time you helped someone improve.
STAR example:
A junior engineer on my team struggled with debugging distributed systems. I mentored them through pair programming and weekly sessions. Over time, they became confident and successfully handled a critical production issue independently.
Insist on the Highest Standards#
This means refusing to accept low-quality work and continuously improving systems. In engineering, it shows up as clean code, testing, and attention to detail.
Amazon looks for people who raise quality standards consistently.
Example question: Describe a time you improved quality.
STAR example:
We had frequent production bugs due to weak testing. I introduced automated unit and integration tests and enforced code review guidelines. Within two months, production issues dropped by 30%, improving overall system stability.
Think Big#
Thinking big means going beyond incremental improvements and proposing bold ideas. Engineers demonstrate this by designing scalable systems and anticipating future needs.
Amazon looks for vision and long-term thinking.
Example question: Tell me about a big idea you proposed.
STAR example:
Our system struggled to handle growing traffic. I proposed migrating to a microservices architecture. After leading the transition, we scaled to handle 2× traffic and reduced deployment dependencies across teams.
Bias for Action#
Bias for Action is about moving quickly and making decisions without overthinking. Engineers show this when they act decisively during incidents or unblock progress.
Amazon looks for speed and calculated risk-taking.
Example question: Describe a time you acted quickly.
STAR example:
During a production outage, I quickly identified a faulty release and rolled it back while preparing a fix. Service was restored within 15 minutes, minimizing customer impact.
Frugality#
Frugality means achieving more with fewer resources. Engineers demonstrate this by optimizing costs and avoiding unnecessary complexity.
Amazon looks for resourcefulness and efficiency.
Example question: Tell me about a time you reduced costs.
STAR example:
Our cloud costs were increasing due to unused resources. I analyzed usage and shut down idle instances while optimizing workloads. This reduced monthly costs by 20% without affecting performance.
Earn Trust#
Trust is built through honesty, transparency, and consistent delivery. Engineers earn trust by communicating clearly and delivering reliable results.
Amazon looks for strong communicators who build credibility.
Example question: How do you build trust with your team?
STAR example:
Our stakeholders were frustrated with missed deadlines. I improved communication by setting realistic timelines and providing regular updates. Over time, confidence in our team improved, and delivery expectations became more predictable.
Dive Deep#
This principle is about understanding the details and not relying on assumptions. Engineers demonstrate this by debugging deeply and analyzing systems thoroughly.
Amazon looks for people who investigate problems at the root level.
Example question: Tell me about a time you found a root cause.
STAR example:
We experienced unexplained latency spikes. I analyzed logs and traced the issue to an inefficient database query. After optimizing it, response times improved by 25%.
Have Backbone; Disagree and Commit#
You’re expected to challenge decisions respectfully and commit once a direction is chosen. Engineers show this when they speak up but still support the team.
Amazon looks for strong opinions balanced with teamwork.
Example question: Describe a time you disagreed with a decision.
STAR example:
I disagreed with a design choice that wouldn’t scale well. I presented data and alternatives, but the team chose another path. I committed fully to implementation and ensured the system worked smoothly.
Deliver Results#
This principle is about achieving outcomes, especially under constraints. Engineers demonstrate this by meeting deadlines and solving problems effectively.
Amazon looks for reliability and execution.
Example question: Tell me about a time you delivered under pressure.
STAR example:
We had a tight deadline for a feature launch. I prioritized critical tasks and coordinated closely with the team. We delivered on time with no major issues, meeting all requirements.
Strive to be Earth’s Best Employer#
This principle focuses on creating a supportive and inclusive work environment. Engineers contribute by supporting teammates and promoting well-being.
Amazon looks for empathy and team awareness.
Example question: How do you support your team?
STAR example:
During a stressful release cycle, I noticed team burnout. I encouraged better workload distribution and helped teammates when needed. This improved morale and productivity.
Success and Scale Bring Broad Responsibility#
As systems grow, so does responsibility. Engineers must consider security, privacy, and societal impact.
Amazon looks for ethical and long-term thinking.
Example question: Tell me about a decision with broader impact.
STAR example:
We were building a feature involving user data. I ensured proper data handling and added safeguards for privacy. This helped us stay compliant and maintain user trust.
Prepare your own STAR stories#
Focus on preparing a small set of strong stories rather than memorizing answers for every question. Aim for 6–8 experiences that demonstrate impact, ownership, and decision-making. Always include measurable results, keep your stories concise, and practice explaining them clearly. If you can map each story to multiple principles, you’ll be much more flexible during the interview.
How to prepare for an Amazon coding interview#
Now that you have a sense of what to expect from an interview and know what kinds of questions to expect, let’s learn some preparation strategies based on Amazon’s unique interview process.
Updating your resume#
Make sure you’ve updated your resume and LinkedIn profile. Always use deliverables and metrics when you can as they are concrete examples of what you’ve accomplished. Typically recruiters will browse LinkedIn for candidates.
If an Amazon recruiter believes that you are a good match they will reach out to you (via email or LinkedIn) to set up a time to chat. Even if you don’t land the job this time, chatting with them is a great chance to network
Prepare for coding assessment#
It’s up to you to come to a coding interview fully prepared for technical assessment. I recommend at least three months of self-study to be successful. This includes choosing a programming language, reviewing the basics, and studying algorithms, data structures, system design, object-oriented programming, OS, and concurrency concepts.
You’ll also want to prepare for behavioral interviews.
It’s best to create a roadmap for your coding interview to keep yourself on track.
Prescreen with a recruiter#
Expect a light 15-30 minute call where the recruiter will gauge your interest level and determine if you’re a good fit. The recruiter may touch on a few technical aspects. They just want to get an idea of your skills. Typical questions might include your past work experiences, your knowledge of the company/position, salary, and other logistical questions.
It’s important to have around 7-10 of your own questions ready to ask the interviewer. Asking questions at an early stage shows investment and interest in the role.
Online Coding Assessment#
Once you complete the call with the recruiter, they’ll administer an online coding test, a debugging test, and an aptitude test. The debugging section will have around 6-7 questions, which you have 30 minutes to solve. The aptitude section will have around 14 multiple-choice questions, dealing with concepts like basic permutation combination and probabilities.
The coding test consists of two questions. You’ll have about 1.5 hours to complete it. Expect the test to be conducted through Codility, HackerRank, or another site. Expect some easy to medium questions that are typically algorithm related. Examples include:
- Reverse the second half of a linked list
- Find all anagrams in a string
- Merge overlapping intervals
Tips to crack Amazon online coding assessment:#
Here are a few easily implemented tips to make the Amazon coding assessment more manageable for yourself:
-
Use your own preferred editor
- It is best to take the assessment in a familiar environment.
-
Read each prompt multiple times through
- Sometimes, they may try and trick you with the wording. Make sure that you’re meeting all of the stated requirements before diving in.
-
Practice with less time than you’re given in the actual assessment
- Time-sensitive tests can be stressful for many people. Help to relieve some of this stress by learning to work faster and more efficiently than you need to be.
Phone Interviews#
Once you’ve made it past the prescreen and online assessment, the recruiter will schedule your video/phone interviews, likely with a hiring manager or a manager from the team you’re looking to join. At this stage in the process, there will be one to three more interviews.
This is where they’ll ask you questions directly related to your resume, as well as data structures, algorithms, and other various coding questions that apply to the position. You can expect to write code, review code, and demonstrate your technical knowledge.
On-Site Interviews: The Loop#
If you have successfully made it through the series of phone interviews, you’ll be invited for an on-site visit. This full day of on-site interviews is referred to as the “The Loop”. Throughout the day, you’ll meet with 4-6 people. Expect half of these interviews to be technical and the other half to assess soft skills. Be prepared to work through questions on a whiteboard and discuss your thought process.
Concepts that Amazon loves to test on are data structures algorithms. It’s important to know the runtimes, theoretical limitations, and basic implementation strategies of different classes of algorithms.
-
Data structures you should know: Arrays, Stacks, Queues, Linked lists, Trees, Graphs, Hash tables
-
Algorithms you should know: Breadth First Search, Depth First Search, Binary Search, Quicksort, Mergesort, Dynamic programming, Divide and Conquer
The Offer / No Offer#
Generally, you’ll hear back from a recruiter within a week after your interviews. If you didn’t get an offer, Amazon will give you a call. You’ll likely have to wait another six months to re-apply. Judging that your on-site interviews went well, they’ll reach out to you, at which point they’ll make you an offer, send you documents to sign, and discuss any further questions you have.
Amazon Software Engineer Interview#
Amazon is one of the top tech companies worldwide, and the company focuses on hiring only the best talent. Securing a software engineer position at Amazon is not a piece of cake, but with the right guidance, content, and practice questions, you can ace the Amazon software engineer interview.
Amazon software engineer interviews consist of four rounds. A major part of these four interview rounds involves technical interview questions. That is why having a solid grasp of computing fundamentals is crucial. Questions related to arrays, linked lists, strings, dynamic programming, and system design are common. We have mentioned some of the commonly asked questions above, so have a look and practice them thoroughly. For more interview prep questions, you can try Educative-99, created to help software engineers secure a job at top tech companies.
Besides technical questions, Amazon software engineer interviews also include behavioral questions. Amazon ensures that candidates are the right fit for the company culture, which is why you’ll be asked several behavioral questions as well. The cornerstone of Amazon’s culture is its 14 Leadership Principles. These principles, which include notions like “Customer Obsession,” “Ownership,” and “Bias for Action,” guide every decision the company makes, from high-level strategies to everyday interactions.
This dual approach to assessing candidates ensures that Amazon software engineers can solve complex technical challenges, collaborate effectively, handle difficult situations, and adapt to the company’s fast-paced environment. Hence, candidates must prepare themselves for both technical and behavioral challenges.
Preparing for Amazon in four weeks is intense—but completely doable if you stay focused and consistent. The key is to balance coding practice, system thinking, and behavioral prep without burning out. Aim for 2–4 hours per day, and focus on patterns over volume.
Week 1: Foundations + core patterns#
This week is about building momentum. You’ll focus on the most common problem types and start getting comfortable with Amazon-style questions. At the same time, begin lightly exploring Leadership Principles.
Daily breakdown:
Solve 2–3 Easy → Medium problems
Review solutions and patterns
Spend 20–30 minutes reading Leadership Principles
Revisit 1 problem from the previous day
Key topics to cover:
Arrays and strings
Hash maps
Sliding window
Two pointers
Suggested practice:
LeetCode (pattern-based practice)
Watch solution explanations for weak areas
Start noting patterns in a notebook
Week 2: Data structures + intermediate patterns#
Now you build depth. You’ll move into core data structures that show up frequently in interviews and start thinking more structurally. This is also the right time to begin mock interviews and STAR story prep.
Daily breakdown:
Solve 2 Medium problems
1 timed problem (30–40 minutes)
30 minutes STAR story drafting
1 mock interview (every 2–3 days)
Key topics to cover:
Linked lists
Stacks and queues
Trees (DFS, BFS)
Recursion basics
Suggested practice:
LeetCode Medium problems
Mock interviews (peer or platform)
Write 4–5 STAR stories mapped to Leadership Principles
Week 3: Advanced topics + system thinking#
This week is where things get more challenging. You’ll tackle harder problems and start thinking about scalability and design—especially important for mid-level and senior roles. Behavioral prep also becomes more structured.
Daily breakdown:
Solve 1 Medium + 1 Hard problem
1 timed mock interview (every other day)
30–45 minutes behavioral prep
30 minutes system design basics
Key topics to cover:
Graphs (BFS, DFS, topological sort)
Dynamic programming
System design fundamentals (APIs, scaling, caching)
Leadership Principles deep dive
Suggested practice:
LeetCode Medium → Hard
Mock interviews (coding + behavioral)
Practice explaining solutions out loud
Week 4: Interview simulation + refinement#
This is your polishing phase. You’re no longer learning new topics—you’re refining what you already know. Focus on consistency, communication, and confidence.
Daily breakdown:
1–2 timed mock interviews
Re-solve previously missed problems
Practice STAR answers out loud
Review notes and weak areas
Key topics to cover:
Weak areas from previous weeks
Common Amazon problem patterns
Behavioral storytelling (clarity + structure)
Resume and communication
Suggested practice:
Full-length mock interviews
Behavioral interview practice
Revisit top 20 Amazon problems
If you have more time#
If you can extend beyond four weeks, slow down the pace and spend more time on deep understanding, system design, and mock interviews. Depth beats speed in the long run.
Quick checklist#
You can solve Medium problems in ~30 minutes
You recognize common patterns (sliding window, BFS, DP)
You have 6–8 strong STAR stories ready
You’ve done at least 5–10 mock interviews
You can clearly explain your thought process
Stay consistent, don’t try to do everything at once, and focus on improving a little every day. That’s what actually moves the needle.
Wrapping up and resources#
Cracking the Amazon coding interview comes down to the time you spend preparing, such as practicing coding questions, studying behavioral interview questions, and understanding Amazon’s company culture. There is no golden ticket, but more preparation will surely make you a more confident and desirable candidate.
To help you prepare for interviews, Educative has created several unique language-specific courses:
Available in multiple languages, these courses teach you the underlying patterns for any coding interview question.
This is coding interview prep reimagined, with your needs in mind.
Happy learning
Continue reading about coding interview prep and interview tips#
Frequently Asked Questions
How to crack Amazon Interview?
How to crack Amazon Interview?
Is Amazon coding interview hard?
Is Amazon coding interview hard?
What are the different rounds of the Amazon interview?
What are the different rounds of the Amazon interview?
Written By:
Amanda Fawcett
Related Courses
