AI-powered learning
Save this course
Building Scalable Data Pipelines with Kafka
Gain insights into Apache Kafka's role in scalable data pipelines. Explore its theory and practice interactive commands to build efficient and diverse data transmission solutions.
4.6
62 Lessons
3h
Join 3 million developers at
Join 3 million developers at
LEARNING OBJECTIVES
- Learn the theory behind Kafka
- Interact with a Kafka cluster running in the browser-terminal
Learning Roadmap
1.
Basics
Basics
Step through the fundamentals of Kafka, distributed systems, messaging patterns, and core components.
2.
Kafka Producer
Kafka Producer
Unpack the core of Kafka Producers, message sending methods, configurations, and serialization techniques.
3.
Kafka Consumer
Kafka Consumer
9 Lessons
9 Lessons
Go hands-on with Kafka consumers, configurations, offsets, and partition rebalancing techniques.
4.
Kafka Internals
Kafka Internals
7 Lessons
7 Lessons
Break down complex ideas of Kafka's replication, controller, request processing, and reliability.
6.
Appendix
Appendix
3 Lessons
3 Lessons
Activate Zookeeper insights, practical API use, and common distributed system solutions.
7.
Reference: Replication
Reference: Replication
14 Lessons
14 Lessons
Master the principles of replica management, leader-based and leaderless replication strategies, and conflict resolution methods.
8.
Reference: Partitioning
Reference: Partitioning
4 Lessons
4 Lessons
Learn how to use partitioning strategies to enhance scalability and optimize data pipelines.
9.
Reference: Transactions
Reference: Transactions
9 Lessons
9 Lessons
Discover the logic behind managing data transactions, isolation levels, and concurrent write challenges.
10.
Reference: Issues in Distributed Systems
Reference: Issues in Distributed Systems
4 Lessons
4 Lessons
Examine the challenges in developing and maintaining distributed systems, including networking, time synchronization, and handling failures.
Certificate of Completion
Showcase your accomplishment by sharing your certificate of completion.
Complete more lessons to unlock your certificate
Developed by MAANG Engineers
ABOUT THIS COURSE
If you’re interested in Big Data, then Apache Kafka is a must-know tool.
What started as an internal LinkedIn project to streamline data transmission and propagation among services has quickly grown to become a mainstay platform for building highly scalable data pipelines. Meet Apache Kafka - the ubiquitous tool to build pipelines for diverse use cases ranging from chronologically tracking user-activity on a website to implementing publish-subscribe feeds.
This course introduces you to Kafka theory and provides you with a hands-on interactive browser-terminal to execute Kafka commands against a running Kafka broker.
ABOUT THE AUTHOR

DataJek
A bay area tech outfit, throwing lots of good ideas on the wall to see what sticks!
Trusted by 3 million developers working at companies
A
Anthony Walker
@_webarchitect_
E
Evan Dunbar
ML Engineer
S
Software Developer
Carlos Matias La Borde
S
Souvik Kundu
Front-end Developer
V
Vinay Krishnaiah
Software Developer
Built for 10x Developers
No Passive Learning
Learn by building with project-based lessons and in-browser code editor
Personalized Roadmaps
The platform adapts to your strengths & skills gaps as you go
Future-proof Your Career
Get hands-on with in-demand skills
AI Code Mentor
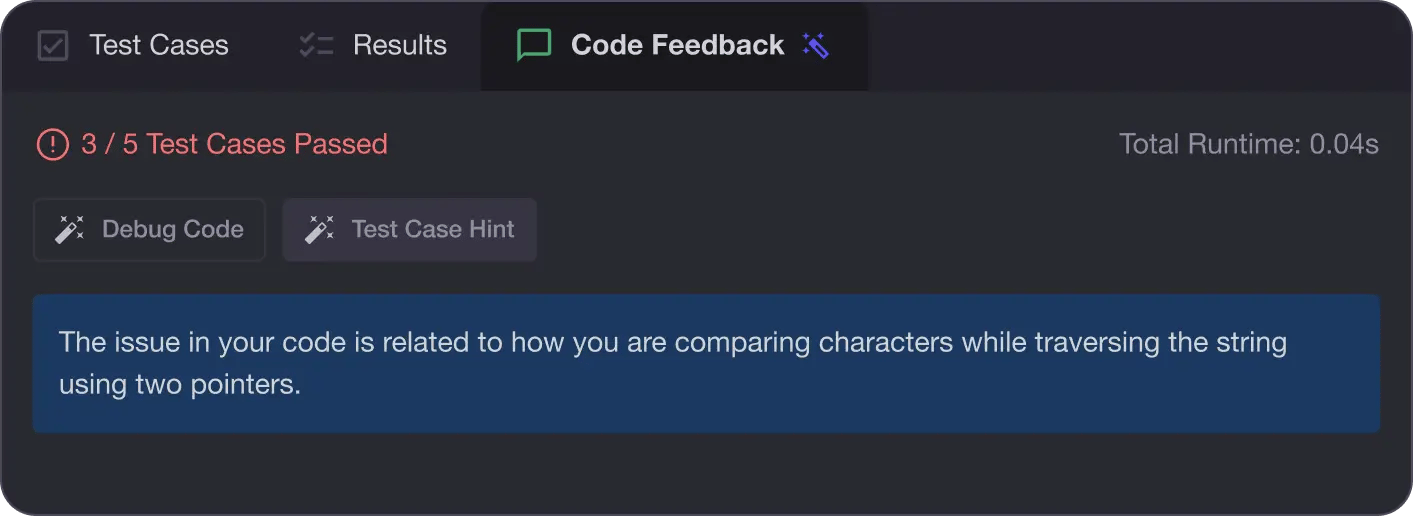
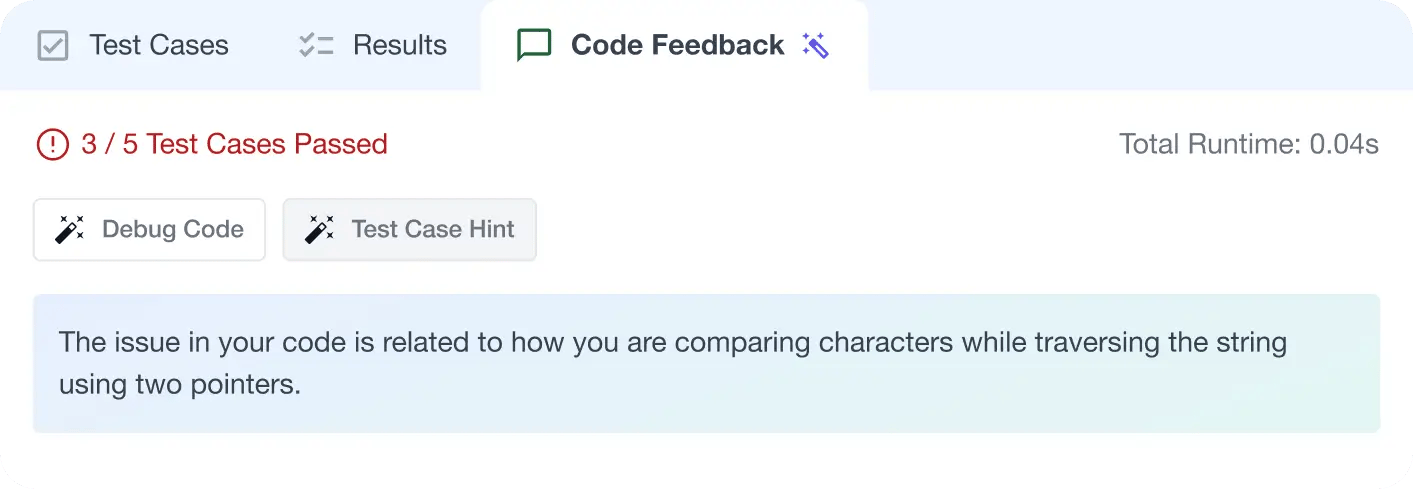
Write better code with AI feedback, smart debugging, and "Ask AI"
MAANG+ Interview Prep
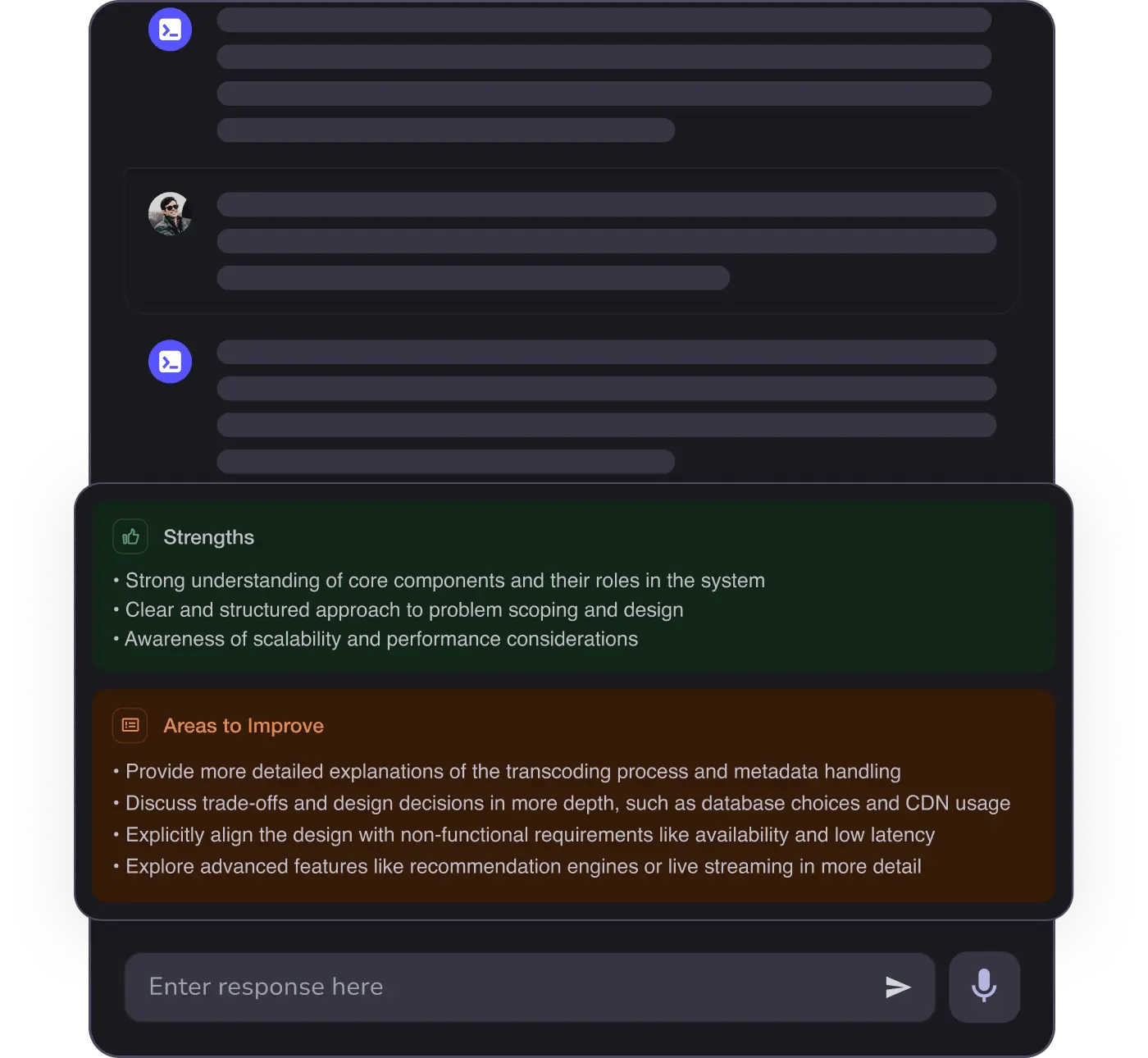
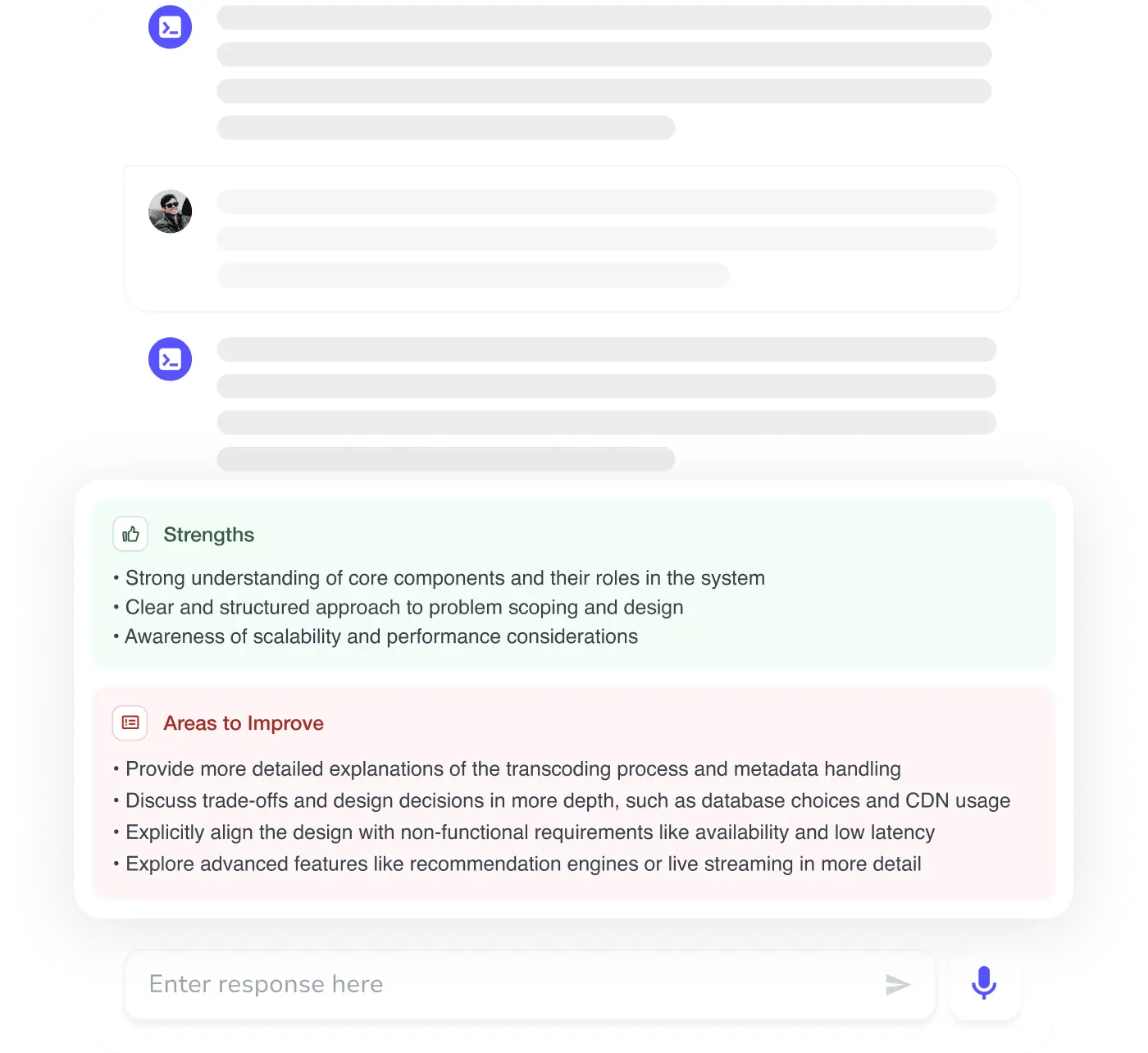
AI Mock Interviews simulate every technical loop at top companies
Free Resources
