AI-powered learning
Save this course
Deal with Mislabeled and Imbalanced Machine Learning Datasets
Gain insights into dealing with mislabeled and imbalanced machine learning datasets. Learn to analyze effects, measure and recover from noise, and interpret results to avoid bias.
28 Lessons
3 Projects
5h
Join 3 million developers at
Join 3 million developers at
LEARNING OBJECTIVES
- The ability to analyze the impact of mislabeled datasets on ML model performance
- An understanding of techniques to deal with imbalanced datasets
- The ability to evaluate the importance of quality data over big data
Learning Roadmap
1.
Introduction to the Course
Introduction to the Course
Get familiar with handling mislabeled and imbalanced data in machine learning models.
2.
Getting Started
Getting Started
Look at AI, ML, supervised/unsupervised learning, image classification, Python programming, and data types.
3.
Understanding Noisy Data, Label Noise, and Its Types
Understanding Noisy Data, Label Noise, and Its Types
4 Lessons
4 Lessons
Examine noisy data, simulate and visualize unbiased and biased mislabeling with Python.
4.
Introduction to Convolutional Neural Network (CNN)
Introduction to Convolutional Neural Network (CNN)
5 Lessons
5 Lessons
Grasp the fundamentals of CNNs, their architecture, layers, pooling, and hyperparameter tuning.
5.
Performance Comparison of Mislabeled and Clean Dataset
Performance Comparison of Mislabeled and Clean Dataset
5 Lessons
5 Lessons
Take a closer look at comparing CNN performance on clean vs. mislabeled datasets.
6.
Dealing with Imbalance Dataset
Dealing with Imbalance Dataset
4 Lessons
4 Lessons
Focus on addressing class imbalance in datasets, transforming techniques, and practical Python applications.
Certificate of Completion
Showcase your accomplishment by sharing your certificate of completion.
Complete more lessons to unlock your certificate
Developed by MAANG Engineers
ABOUT THIS COURSE
Machine learning models depend thoroughly on the dataset quality they are trained on. The model’s performance deteriorates significantly due to noisy datasets. One primary source of noise is mislabeling. Labeling is a costly, time-consuming, and error-prone stage in the machine learning pipeline. Data, if not correctly labeled, can introduce bias and inaccuracies into machine learning models.
This course offers hands-on experience in analyzing the effects of mislabeled datasets on machine learning models, especially convolutional neural networks. It emphasizes the modern data-centric perspective in machine learning. Eventually, it teaches how to measure and recover from noisy datasets.
After completing this course, you will be skilled at handling imbalanced datasets and be able to interpret results fairly to avoid bias toward minority classes. Having such skills is vital in machine learning and important for both industry and academia.
ABOUT THE AUTHOR
Dr. Gul Sher Baloch
Experienced senior data professional with 12+ years of leadership. Led 15+ successful projects, securing funding for 7+ and 200+ citations. Holds MIT AI/ML and Google data analytics certifications.
Trusted by 3 million developers working at companies
A
Anthony Walker
@_webarchitect_
E
Evan Dunbar
ML Engineer
S
Software Developer
Carlos Matias La Borde
S
Souvik Kundu
Front-end Developer
V
Vinay Krishnaiah
Software Developer
Built for 10x Developers
No Passive Learning
Learn by building with project-based lessons and in-browser code editor
Personalized Roadmaps
The platform adapts to your strengths & skills gaps as you go
Future-proof Your Career
Get hands-on with in-demand skills
AI Code Mentor
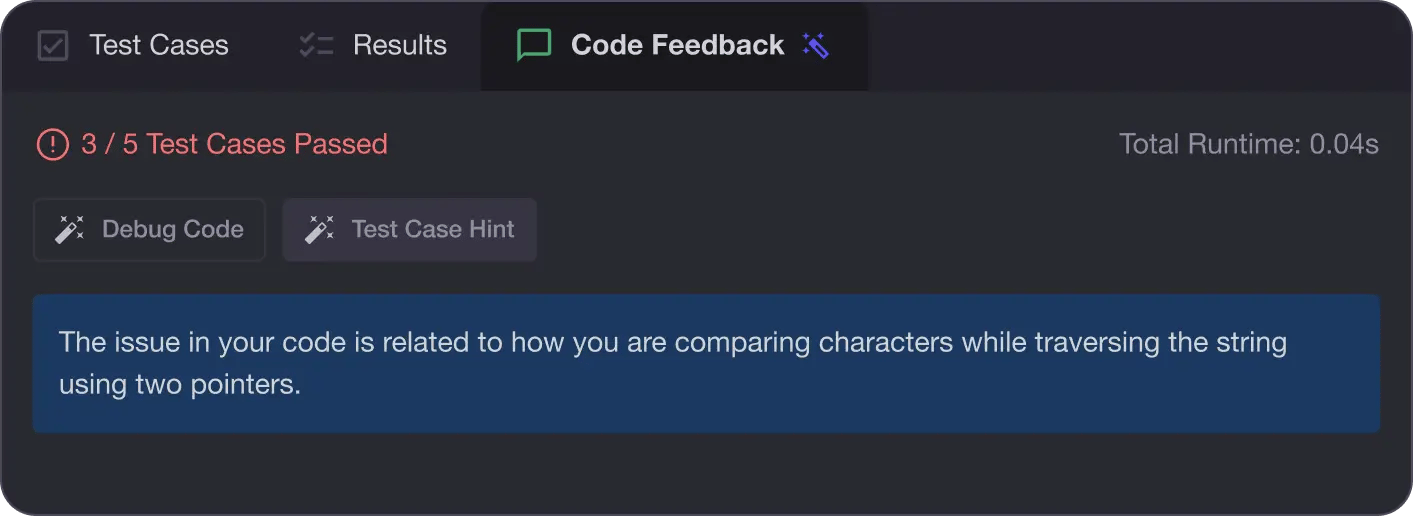
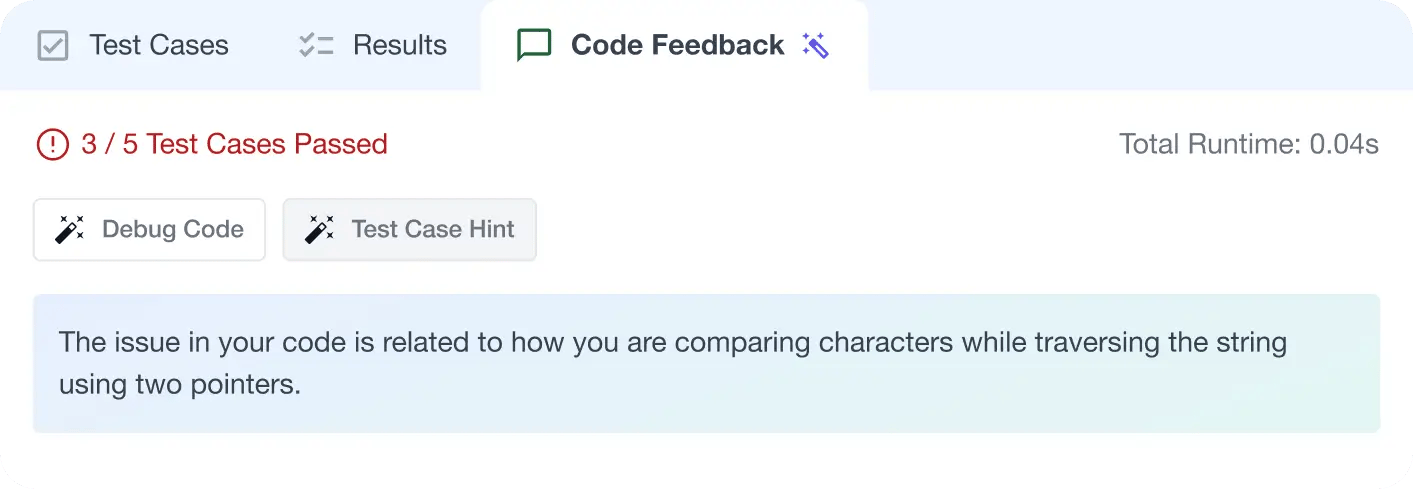
Write better code with AI feedback, smart debugging, and "Ask AI"
MAANG+ Interview Prep
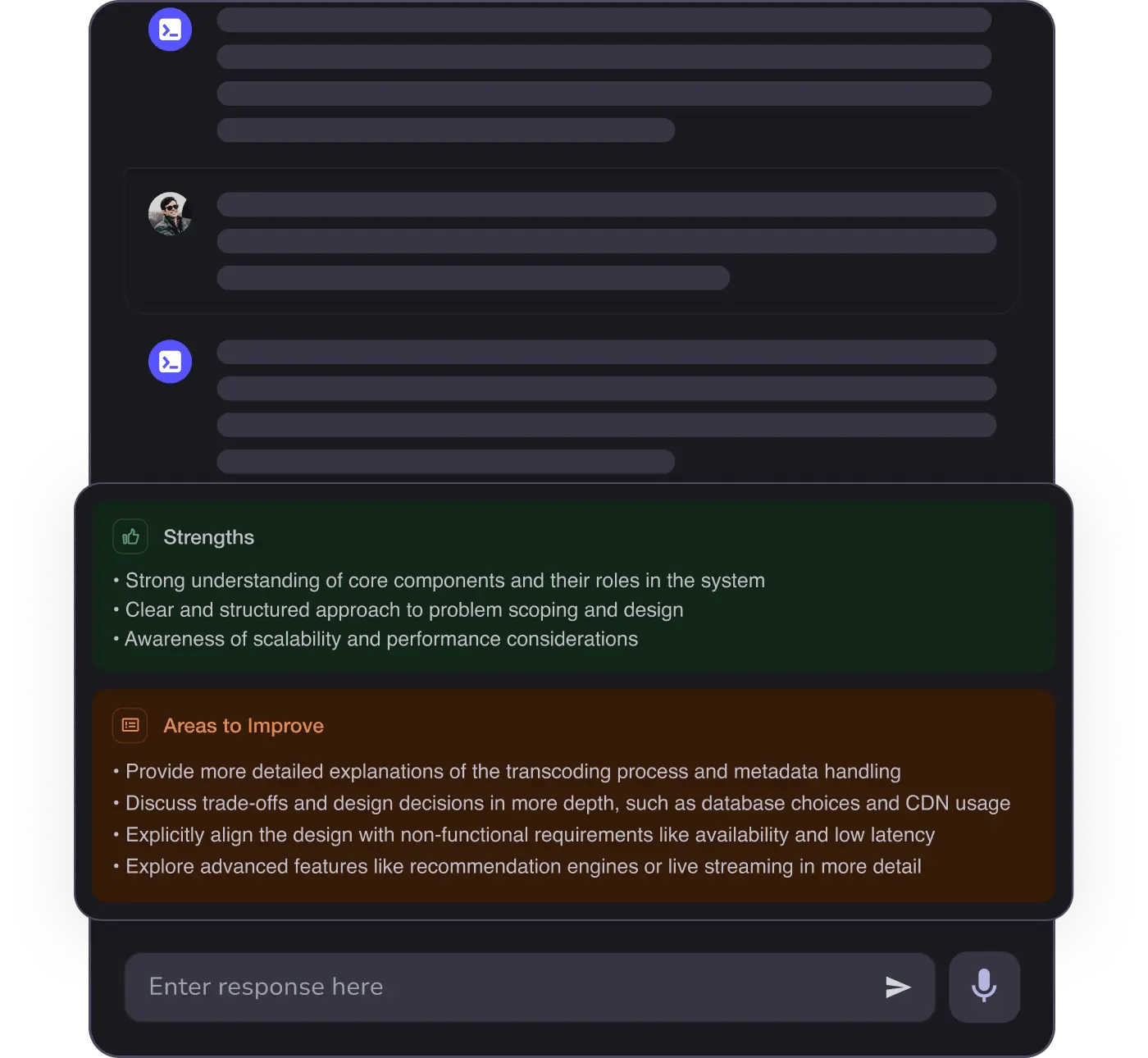
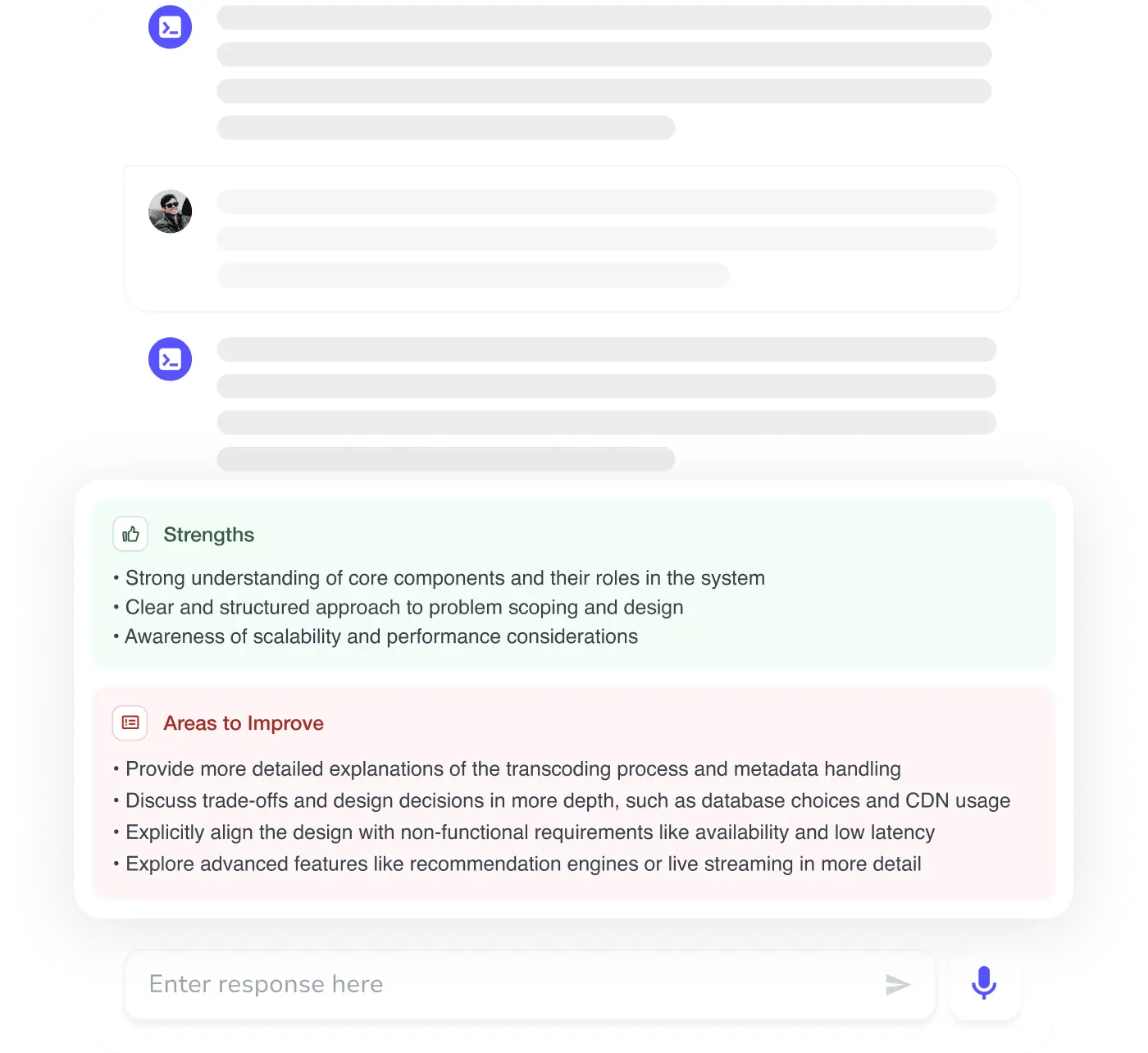
AI Mock Interviews simulate every technical loop at top companies
Free Resources
