Core concepts of generative AI involve neural networks, adversarial training (GANs), variational inference (VAEs), and the ability of models to learn and generate data that resembles the training data distribution.
Join 3 million developers at
Join 3 million developers at
LEARNING OBJECTIVES
- Explore the fundamentals of generative AI, including its evolution, key architectures, and language representations.
- Analyze text preprocessing methods such as tokenization, stemming, and lemmatization to prepare data for generative AI models.
- Examine foundational concepts of natural language processing (NLP) and its progression to advanced models that enable language generation.
- Evaluate the mechanics of neural networks and their role in building context for generative AI applications.
- Investigate the encoder-decoder framework for sequence-to-sequence tasks and its impact on modern language models.
- Understand the principles of prompt engineering to effectively communicate with generative AI models.
KEY OUTCOMES
Design Generative AI Solutions
Apply foundational concepts to create innovative generative AI applications across text, image, and audio domains.
Optimize AI Model Performance
Implement model optimization techniques to enhance the efficiency and accuracy of generative AI systems in real-world settings.
Evaluate AI Systems Effectively
Assess generative AI models using intrinsic and extrinsic metrics to ensure quality and reliability in applications.
Lead AI-Driven Projects
Guide teams in developing and deploying generative AI solutions, addressing ethical considerations and emerging trends.
Why choose this course?
Master Generative AI or Get Left Behind
As generative AI rapidly transforms industries, not understanding its core principles can hinder your career. The stakes are high—without this knowledge, you risk being outpaced by peers who harness AI effectively.
The Challenge of Navigating Complexity
Even skilled developers struggle to grasp how generative AI systems function. Without a solid foundation, you may find yourself unable to leverage these tools creatively, limiting your potential to innovate and lead.
Your Path to AI Mastery Starts Here
This course demystifies generative AI by breaking down its principles and connecting them to real-world applications. Engage with hands-on lessons on foundational models, optimization strategies, and prompt engineering to build your experti
Elevate Your Career Today
Join a community of forward-thinking professionals ready to embrace the future of AI. Equip yourself with essential skills to thrive in this evolving landscape and make a meaningful impact in your field.
Learning Roadmap
1.
Introduction to Generative AI
Introduction to Generative AI
Explore the fundamentals and applications of generative AI for innovative solutions.
2.
Building Blocks of Generative AI
Building Blocks of Generative AI
Explore the evolution and techniques of generative AI and modern NLP.
Text Preprocessing EssentialsThe Emergence of NLPVectorizing LanguageBuilding Context with NeuronsReconstructing Context with Sequence ModelsLearning Phrase Representations Using Encoder-DecoderEmergence of Generative AIAttention Is All You NeedBidirectional Transformers for Language UnderstandingImproving Language Understanding by Generative Pretraining
3.
Foundation Models
Foundation Models
11 Lessons
11 Lessons
Explore foundation models, pretraining, optimization, and multimodal capabilities in generative AI.
4.
Intelligent Interaction with GenAI
Intelligent Interaction with GenAI
3 Lessons
3 Lessons
Master effective AI communication, dynamic knowledge integration, and autonomous agent capabilities.
5.
Practical Applications and Case Studies
Practical Applications and Case Studies
5 Lessons
5 Lessons
Explore the transformative applications of generative AI across various media formats.
6.
Future of Generative AI and Wrap Up
Future of Generative AI and Wrap Up
2 Lessons
2 Lessons
Explore the transformative potential and ethical considerations of generative AI advancements.
Certificate of Completion
Showcase your accomplishment by sharing your certificate of completion.
Complete more lessons to unlock your certificate
Developed by MAANG Engineers
ABOUT THIS COURSE
Generative AI is rapidly reshaping how software is built, how decisions are made, and how humans interact with machines. From large language models to multimodal systems, understanding generative AI is becoming a foundational skill. This course focuses on generative AI essentials, giving you the conceptual clarity and practical perspective needed to navigate this fast-moving space with confidence.
I built this course from my work in adaptive AI systems, intelligent tutoring platforms, and teaching complex machine learning concepts at scale. A recurring challenge I observed was that learners could use generative AI tools, but lacked a clear mental model of how these systems actually work. This course addresses that gap by breaking generative AI down into its core principles and connecting them to real-world applications.
You’ll begin with the fundamentals of generative AI, including its evolution, key architectures, and language representations. From there, you’ll explore foundation models, pretraining, fine-tuning, and optimization strategies that power modern systems. The course also covers large language models, multimodal AI (vision and audio), and how context is constructed within neural systems. Throughout, you’ll develop the ability to interpret, guide, and effectively interact with AI systems.
If you want to master generative AI essentials and build a strong foundation for working with modern AI systems, this course provides a clear, structured path to get there.
ABOUT THE AUTHOR
Khayyam Hashmi
Computer scientist and Generative AI and Machine Learning specialist. VP of Technical Content @ educative.io.
Trusted by 3 million developers working at companies
A
Anthony Walker
@_webarchitect_
E
Evan Dunbar
ML Engineer
S
Software Developer
Carlos Matias La Borde
S
Souvik Kundu
Front-end Developer
V
Vinay Krishnaiah
Software Developer
Built for 10x Developers
No Passive Learning
Learn by building with project-based lessons and in-browser code editor
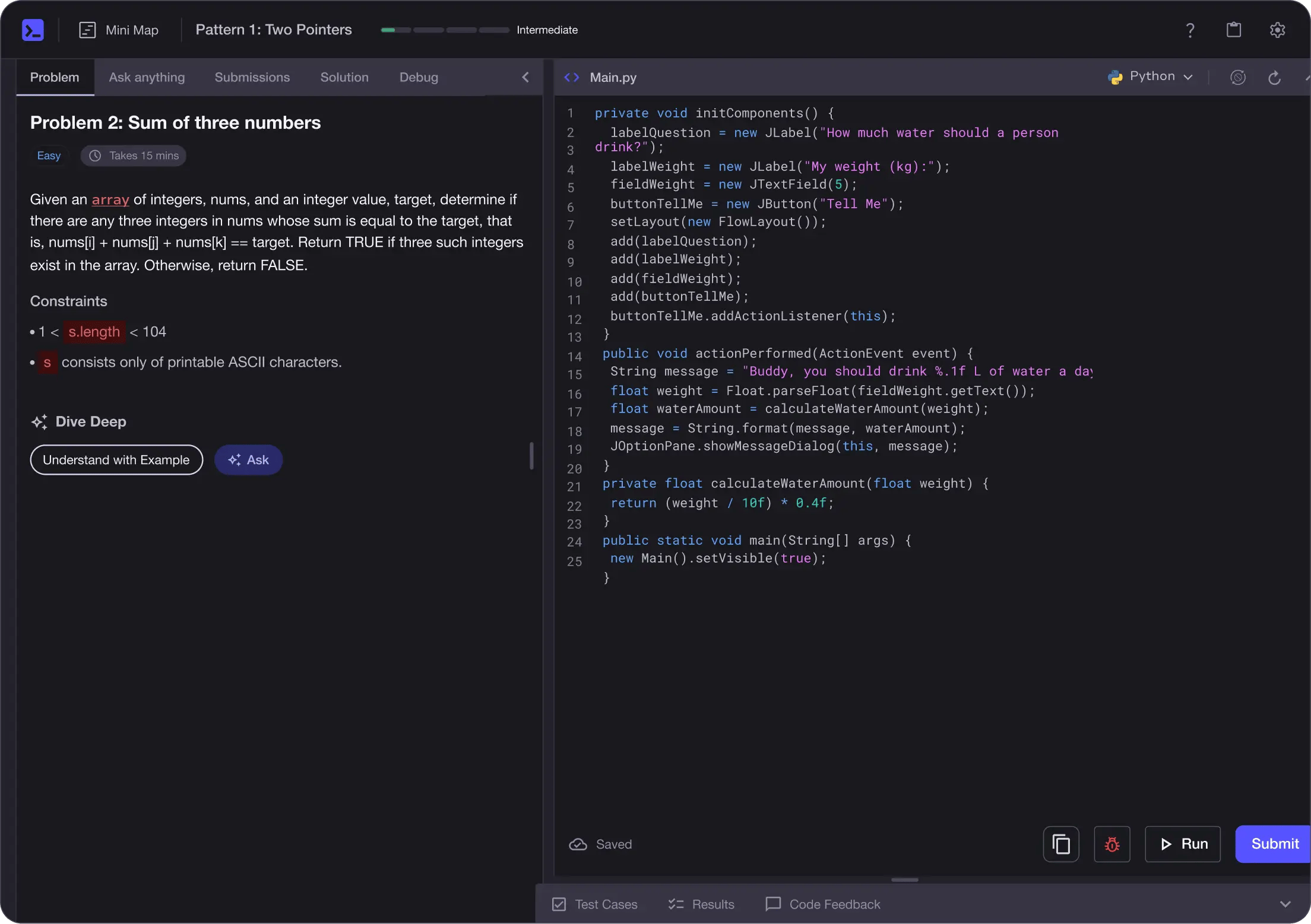
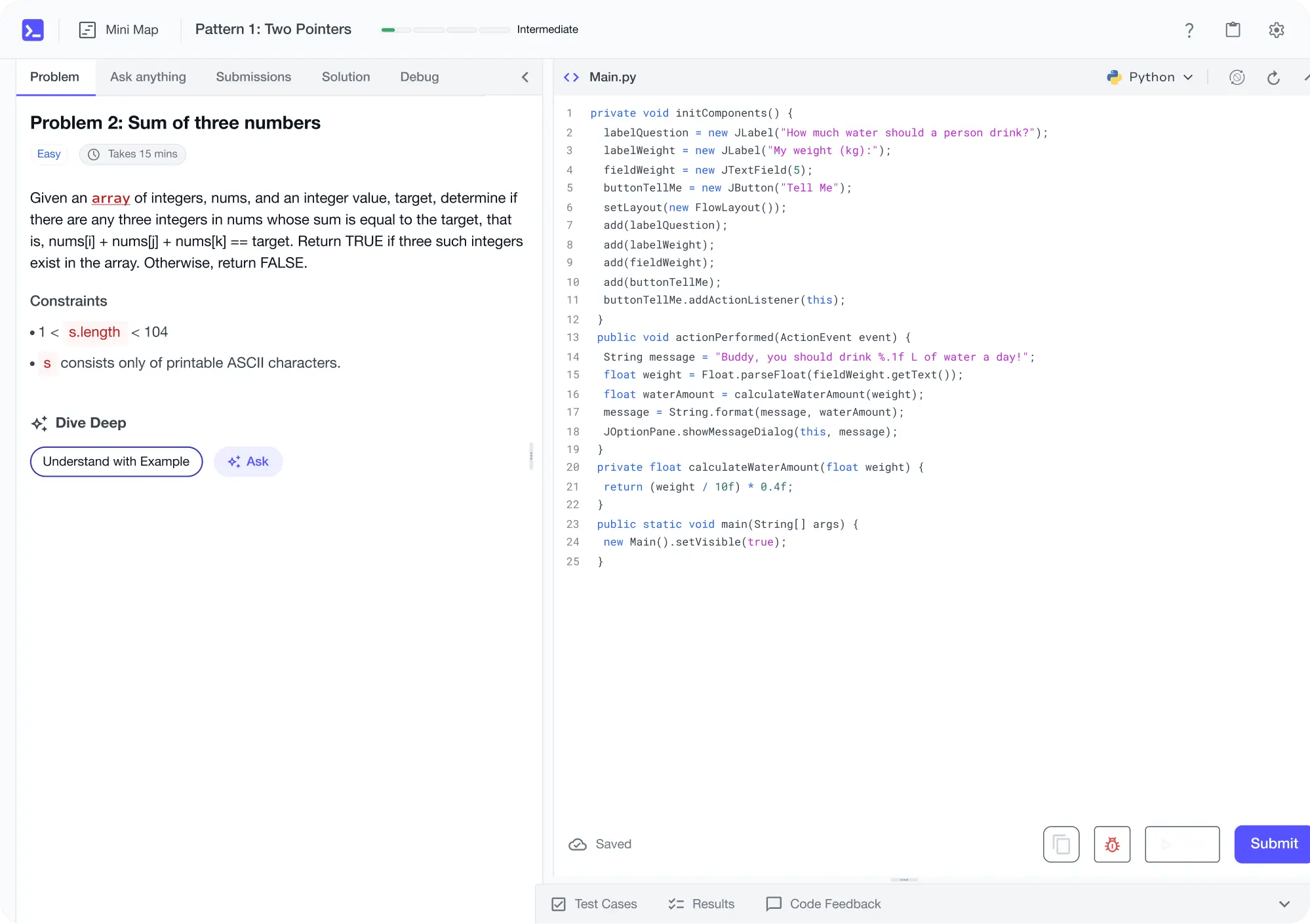
Personalized Roadmaps
The platform adapts to your strengths & skills gaps as you go
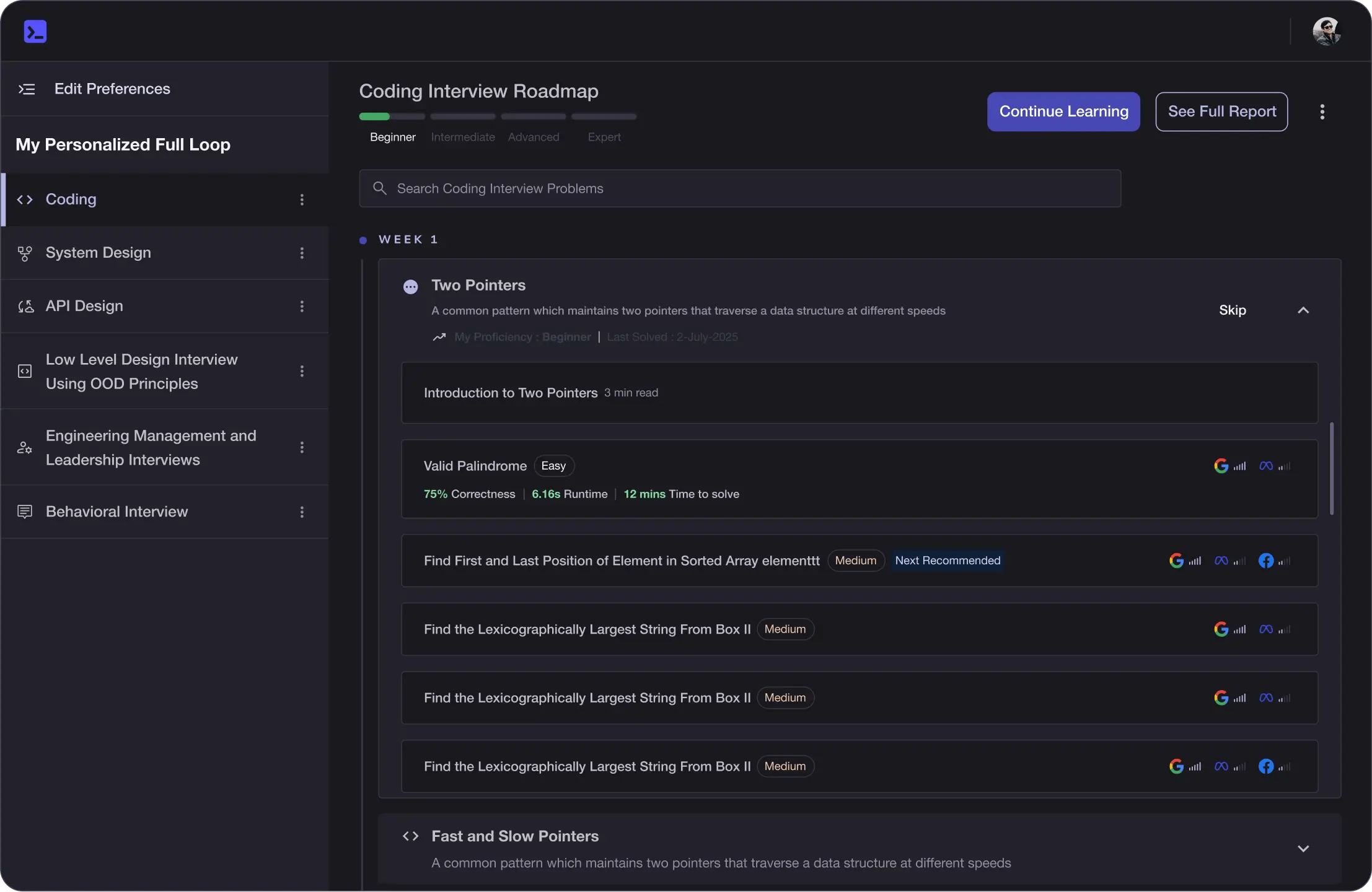
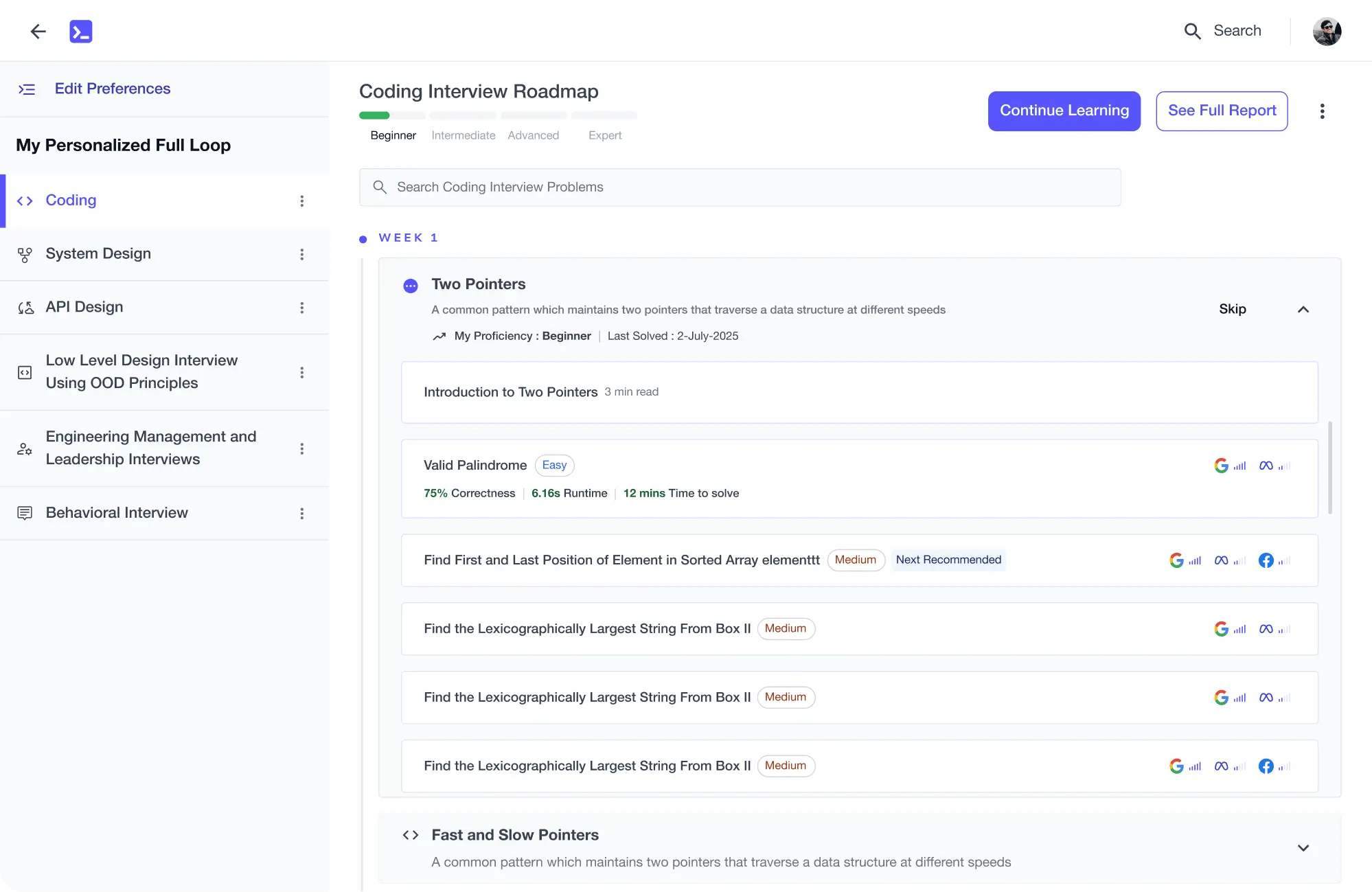
Future-proof Your Career
Get hands-on with in-demand skills
AI Code Mentor
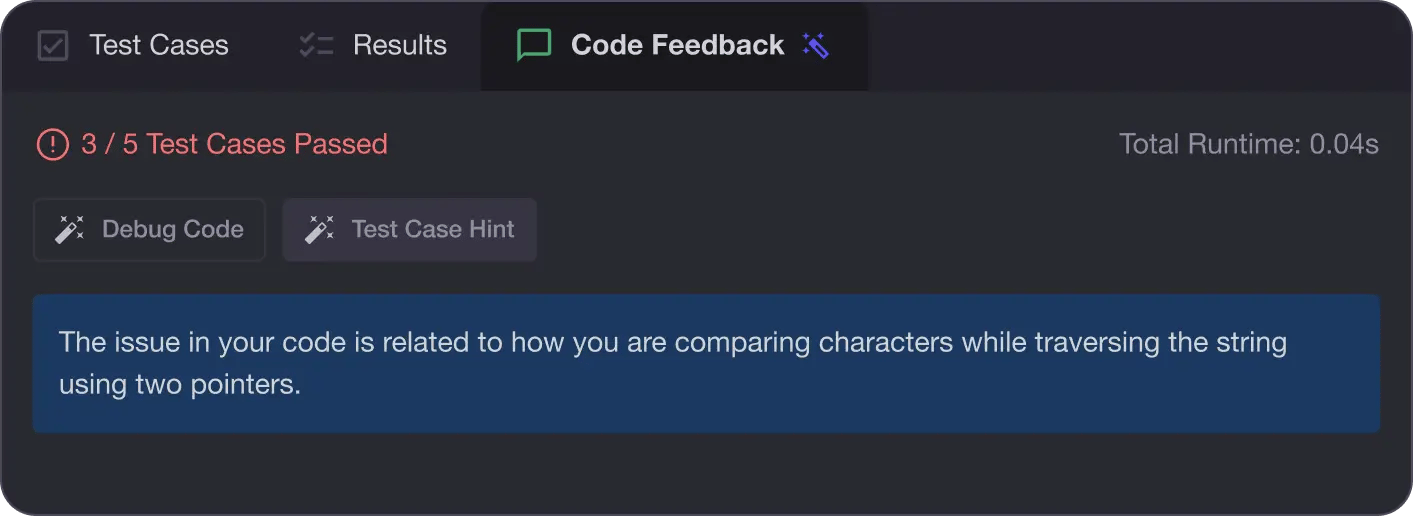
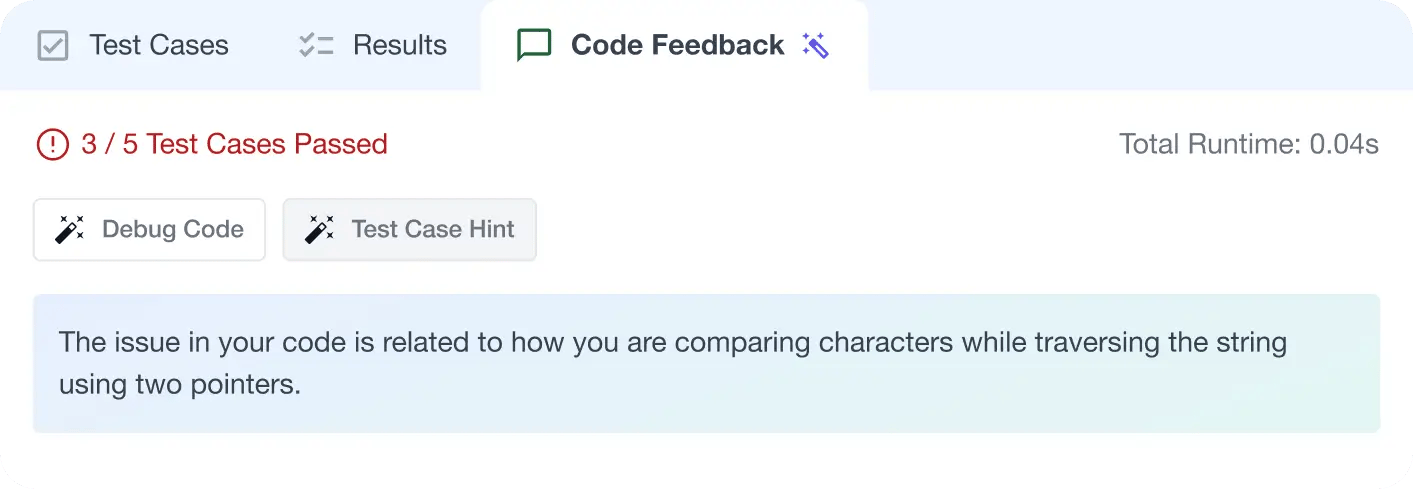
Write better code with AI feedback, smart debugging, and "Ask AI"
MAANG+ Interview Prep
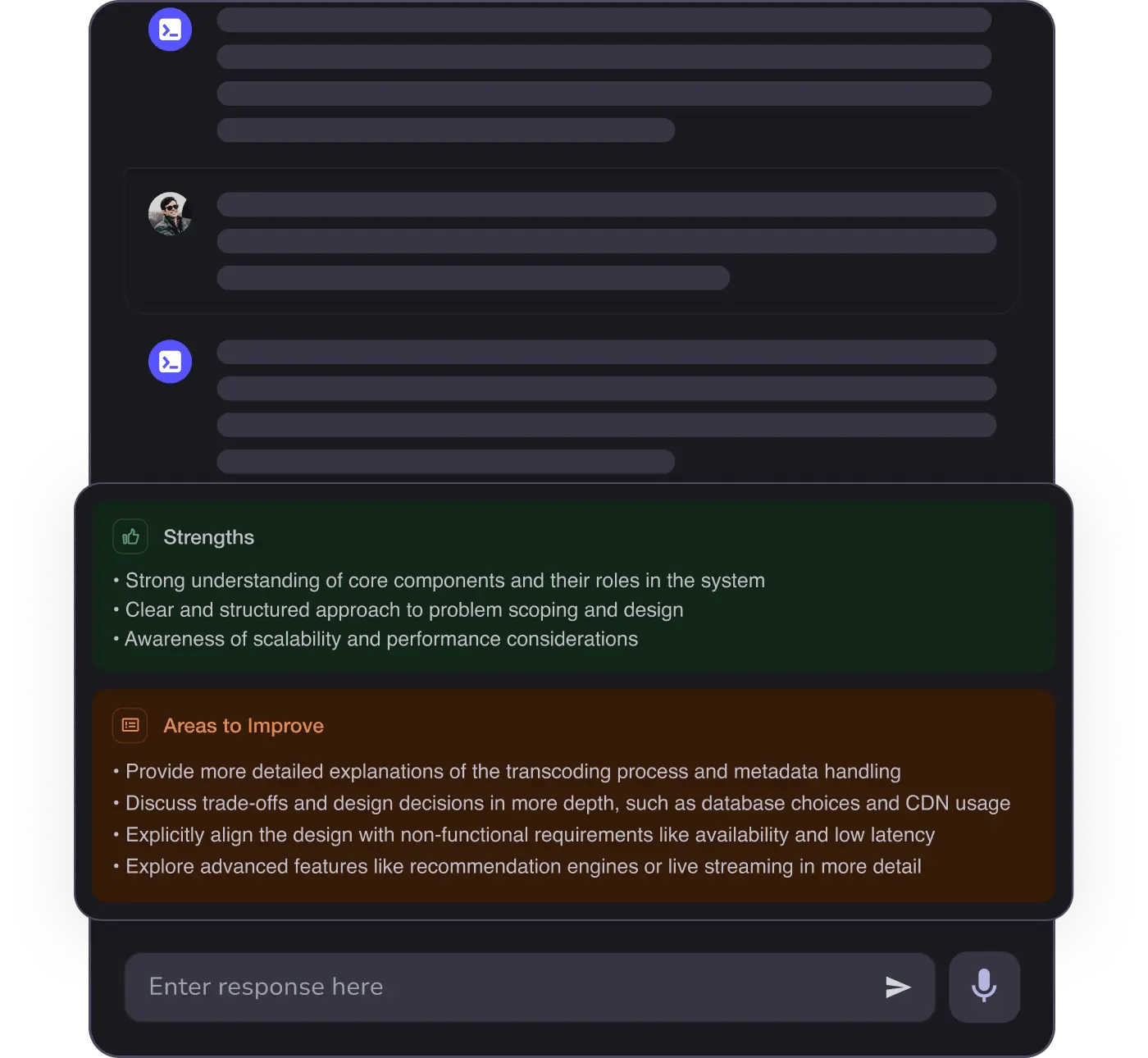
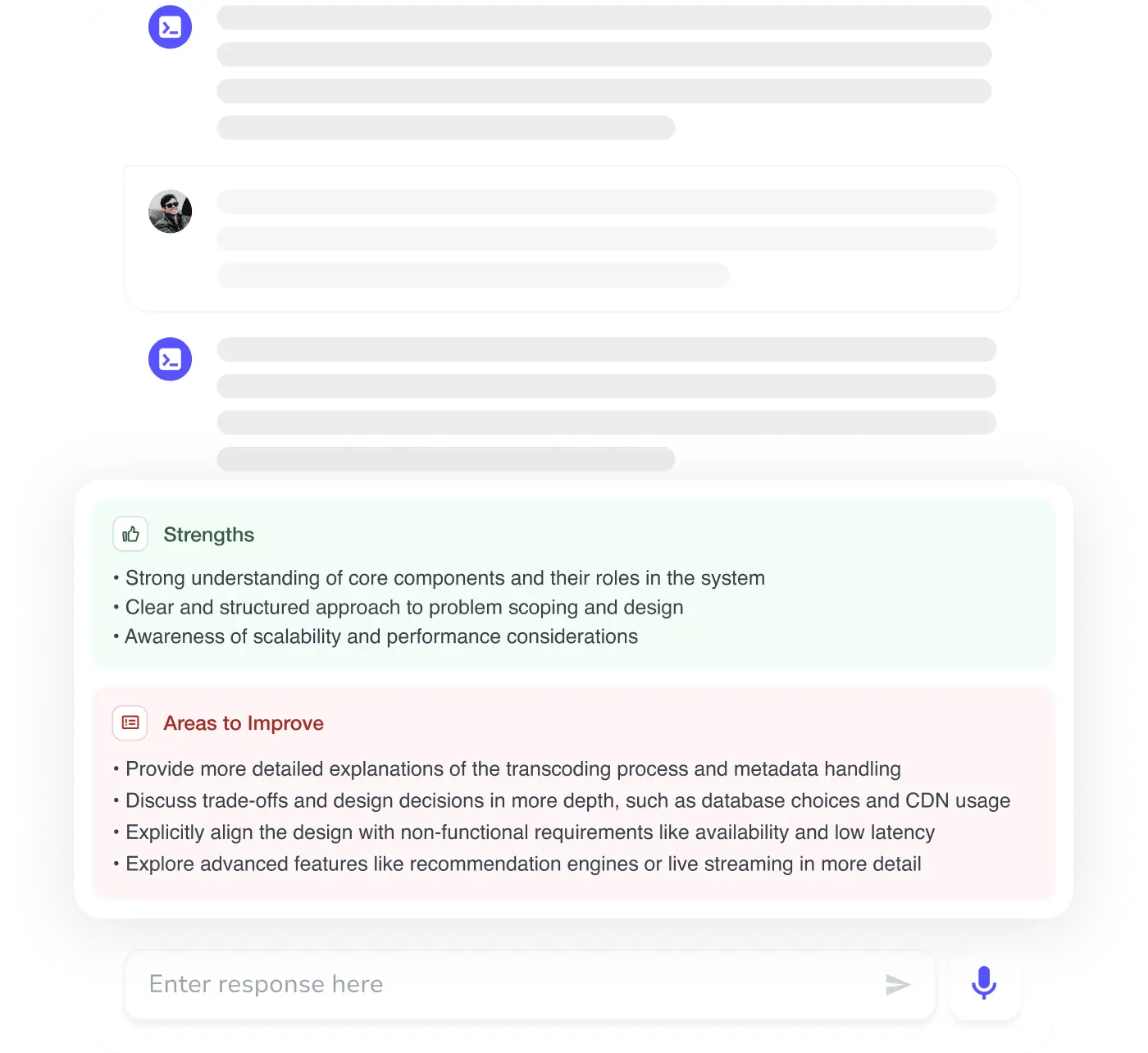
AI Mock Interviews simulate every technical loop at top companies
Free Resources
Frequently Asked Questions
What are the core concepts of generative AI?
What is generative AI?
Is generative AI difficult to learn?
What is generative AI in simple words?
What are GenAI basics?
