System Design Deep Dive: Real-World Distributed Systems
Ready to become a System Design pro? Unlock the world’s largest distributed systems, including file systems, data processing systems, and databases from hyperscalers like Google, Meta, and Amazon.
- Analyze design trade-offs in real-world distributed systems using case studies from leading companies
- Evaluate the architecture and performance of distributed file systems like Google File System, Colossus, and Tectonic
- Design scalable and fault-tolerant distributed databases by understanding principles from Bigtable, Megastore, and Spanner
- Implement concurrency management techniques using Two-Phase Locking and distributed coordination services like Chubby and ZooKeeper
- Apply consensus algorithms such as Paxos and Raft to ensure data consistency and fault tolerance in distributed systems
Demonstrate your ability to analyze and design scalable distributed systems, impressing interviewers with real-world examples and trade-off reasoning.
Design and evaluate distributed file systems and databases that meet high availability and performance standards in production environments.
Effectively manage concurrent access and ensure data integrity in distributed applications using proven techniques and tools.
Utilize consensus algorithms to maintain data consistency and fault tolerance in distributed systems, ensuring reliable operations across nodes.
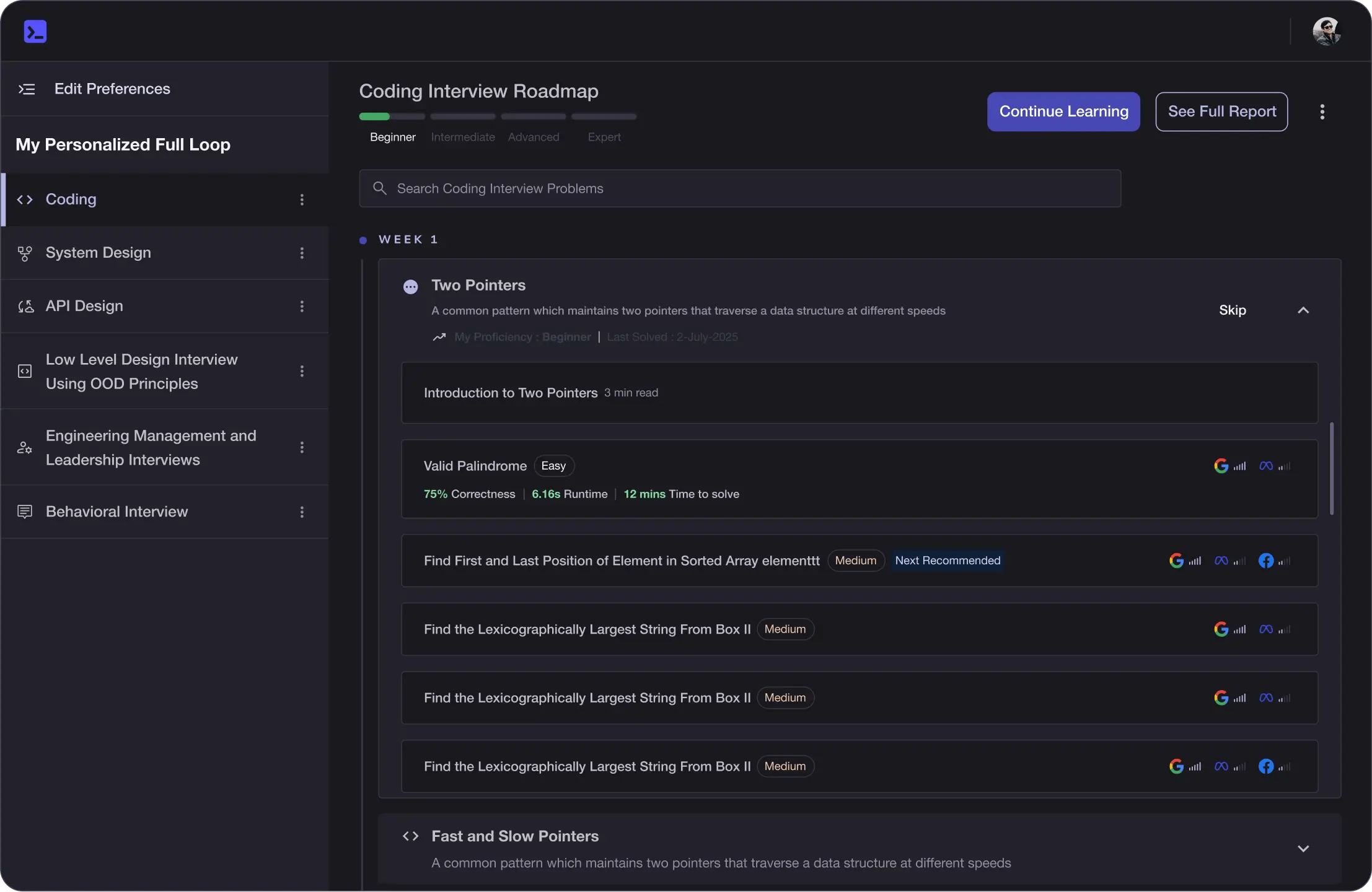
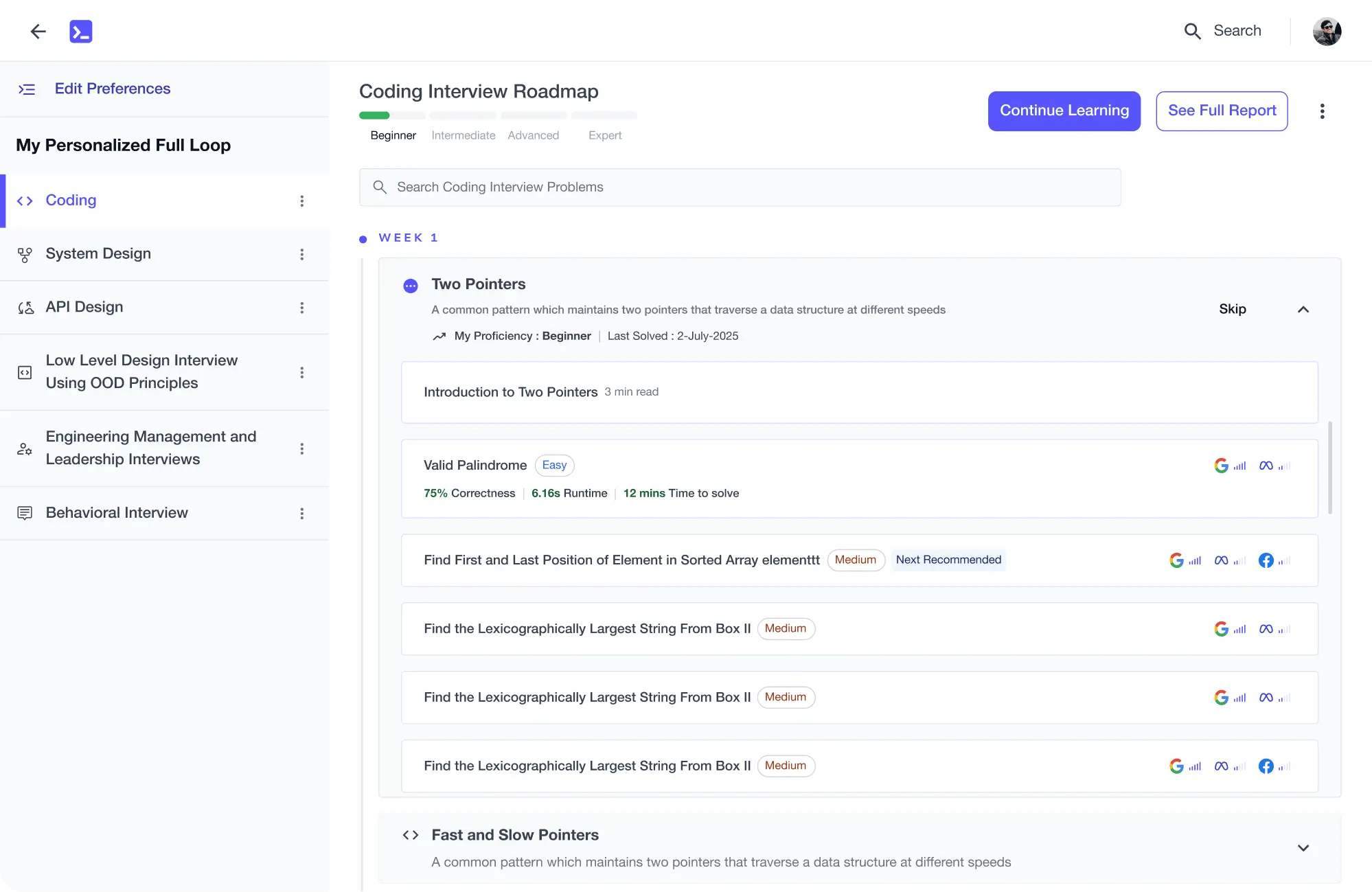
Learning Roadmap
3.
Google File System (GFS)
Google File System (GFS)
11 Lessons
11 Lessons
4.
Google Colossus File System
Google Colossus File System
3 Lessons
3 Lessons
5.
Facebook's Tectonic File System
Facebook's Tectonic File System
8 Lessons
8 Lessons
7.
Google Bigtable
Google Bigtable
7 Lessons
7 Lessons
8.
Google Megastore
Google Megastore
6 Lessons
6 Lessons
9.
Google Spanner
Google Spanner
9 Lessons
9 Lessons
11.
Many-core Key-value Store
Many-core Key-value Store
5 Lessons
5 Lessons
12.
Scaling Memcache
Scaling Memcache
7 Lessons
7 Lessons
13.
SILT
SILT
12 Lessons
12 Lessons
14.
Amazon DynamoDB
Amazon DynamoDB
8 Lessons
8 Lessons
16.
Two-phase Locking (2PL)
Two-phase Locking (2PL)
3 Lessons
3 Lessons
17.
Google Chubby Locking Service
Google Chubby Locking Service
8 Lessons
8 Lessons
18.
ZooKeeper
ZooKeeper
5 Lessons
5 Lessons
20.
MapReduce
MapReduce
8 Lessons
8 Lessons
21.
Spark
Spark
10 Lessons
10 Lessons
22.
Kafka
Kafka
8 Lessons
8 Lessons
24.
Understanding Consensus: Two Generals, FLP, & Byzantine Generals
Understanding Consensus: Two Generals, FLP, & Byzantine Generals
4 Lessons
4 Lessons
25.
Two-phase Commit
Two-phase Commit
4 Lessons
4 Lessons
26.
State Machine Replication
State Machine Replication
10 Lessons
10 Lessons
27.
Paxos
Paxos
6 Lessons
6 Lessons
28.
Raft
Raft
8 Lessons
8 Lessons
Fahim ul Haq
Software Engineer, Distributed Storage at Meta and Microsoft, Educative (Co-founder & CEO)
Trusted by 3 million developers working at companies
Desh S
Huawei Technologies
Sumit S
Learner
Jayanth H
Learner
Desh S
Huawei Technologies
Built for 10x Developers
Free Resources
cheatsheet
cheatsheet
cheatsheet
blog
guide
